




extrobe
Members
-
Joined
-
Last visited
-
I'd love to see partial-parity scheduling. eg, do 25% each week, meaning a full scan is done every 4 weeks. Currently, doing a full scan takes nearly 25hours, so don't tend to run them unless I have had a dirty restart or something. Being able to phase it would allow users to keep parity in check
-
Thanks @jude, this did the trick for me in 6.7 stable as well
-
I asked pretty much the same question on reddit the other day. One of the devs responded that they're working on a change to allow you to force a 'move' when you're mapping a remote path - for this specific reason
-
I get the same error - 6.7 is the next major release (with a new dashboard etc) that's currently being tested.
-
Hi - having a bit of trouble with the extended test. It's been 'running' for best part of 3 days now, but don't think it's actually doing anything. On the plugin tab, it says it's processing a specific share ( Status: Processing /mnt/user/wAppDataBackup) , but it's been like that for most of the time it has been running. There's no disk activity, so don't think it's actually doing anything But unsure how to check / force stop / if this is actually normal or not
-
Thanks trurl, Yes, I did go through those as well, and as far as I can gather, that all looks ok - I used the folder browse button to be extra sure. I've not configured scripts / email templates / password file / admin / logs (latter 2 being the default locations) but I don't use any of these, and in any case, they all default to /config anyway, which I've checked exists within appdata. Perhaps it wasn't SAB - I did have a couple of non-CA store dockers installed which may not have been correctly setup, but thought I'd check it wasn't using an internal folder for unpacking activities. I've just done a full reset of the img file, so going to grab some large files and see how they get on before I add all the more suspect dockers!
-
Just a quick query I had... what volume does SabNZB use when unpacking (or repairing perhaps) files? From time to time I'm running out of space on the docker image. I've checked every docker app and all volumes are mapped to the cache drive / a user share. The issue seems to get triggered when SAB is unpacking a particularly large file, so wondered if the unpacking process might be the trigger for this? For now, I'm avoiding anything > ~10GB (img is 20GB, of which 8GB is used), but wonder if this might unwarranted and the issue coming from elsewhere. (I'm a little hesitant to stress test my theory as it's a PITA to fix, but thought I'd ask anyway)
-
I also wonder if there's something better that can be done ref Plex - we all know it's a pain when it comes to backing up, and this accounts for the majority of the backup size. The cache directory doesn't actually need backing up though according to plex documentation. Doesn't help with the masses of metadata files, but would cut the backup size significantly. I'm sure tailoring the plugin to have app-specific behaviours isn't going to be particularly welcome from a development point of view, but Plex feels like a worthy exception.
-
Sorry if this is a really n00b question - but how would I go about restoring just one of my apps? One of my MariaDB db's seems to have gotten corrupted, but not sure how to go about restoring just that app's data, rather than everything Thanks! Edit: ok - looks like I just need to un-tar the most recent backup and copy the relevant file across - not too onerous-a-job, but would +1 either app-specific tar files or app-specific restore functionality - would cut the restore time down dramatically!
-
If the PlexmediaServer folder still exists in your appdata folder, you should be fine. Remove any existing dockers. Create a new one using 'my templates' (eg, my-PlexMediaServer) - this should re-use all the mappings you had before. Spin it up - give it a couple of mins to sort itself out, then try connecting. If you still can't connect, check the docker logs
-
Thanks Squid - I eventually found the very useful Archived Notification menu where it gave me some more detail. I found... So was indeed the temp setting off the failure. I've upped the WARN threshold to 50c, so that should sort it out (it's never less that 38/39, so doesn't take much to get it to 40)
-
I frequently wake up to a status message on my server stating However, I can't see what the issue is. Some days it's reporting fine - about 50/50 Parity is valid, and last checked a few days ago. When I run fix common problems, there are no errors or warnings Only thing I can think of, is that when mover is running, the cache drive sometimes gets warm (40c-42c) - could this be triggering the FAIL notification?
-
So, after 3 solid days of trying to get this working - I finally worked out what the underlying issue was - both for being able to 'claim' my original server, form sharing libraries, and remote connections. My MTU size was defaulting to 1500, but was evidently too high! Changed it to 1484 (well, used MSS Clamping instead) and instantly worked. Yikes!
-
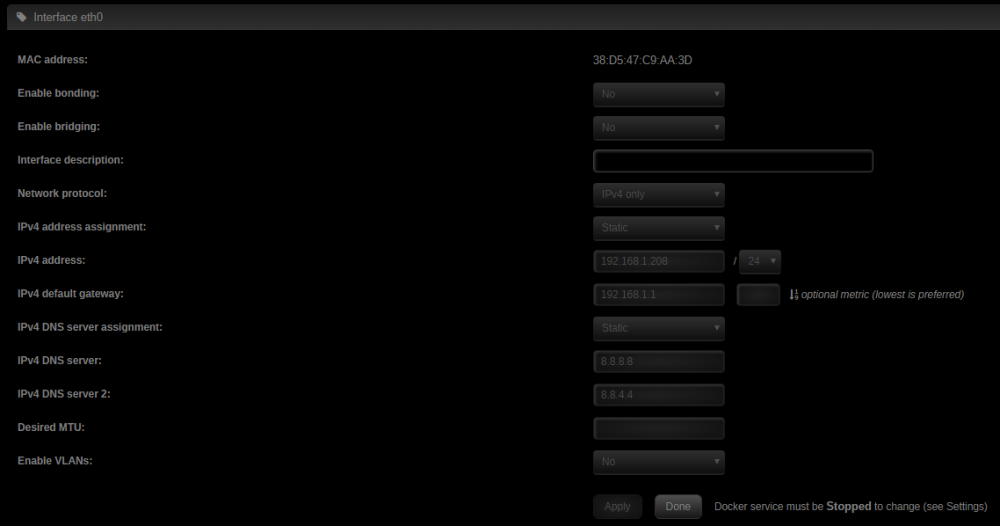
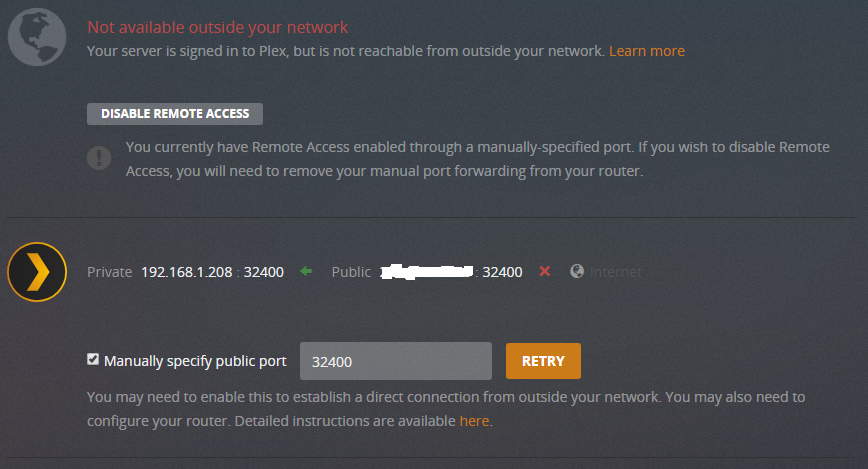
OK - could do with a bit of help on this bit if anyone is able to. I can't currently get remote access to work - but my hunch is that it's my unraid network interface setup Remote access just won't succeed - I'm using Unifi router, with a modem in bridge mode, so there should not be a double-NAT issue. In Plex, i've set 'manual port' to 32400 (I've tried letting uPnP take care of it, and I've tried an alternative port - same results) In Unifi, this port is forwarded to the local IP if I browse to [public facing ip]:32400/web, the plex web interface successfully loads - so I think that rules out a forwarding / nat issue I also have (had) another plex install on another machine, which worked just fine, including remote access. So reckon it's something local to the docker/server I've attached my eth0 setup - it was a bonded connection (bond0) which I hastily turned back to a regular one when I was having a different problem which I thought might be network related, and wonder if I've done something funky which is blocking communications. I'm unsure if the logs can help point towards the issue, but I get a little lost sifting the the logs - not really sure what I'm looking for!

-
Yes - but didn't manage to get a response. In the end, I backed up the appdata folder, create a fresh Plex install and copied the plugin support, media & metadata folders. This seemed to sort it out. Still have a couple of issues that I might need a hand with (can't get remote access to work, but could be an Unraid network config issue), and problem sharing libraries - but I'll do a bit more troubleshooting before I pop back!




