




knutarn
Members
-
Joined
-
Last visited
Everything posted by knutarn
-
Any new on this? I like to love to have feks plex move a movie on SSD and move it back when it no aktiv on 1 week So if the are new movie when many ppl look on, so its on the SSD
-
hoo! thx!
-
Yes I working on it But what is my array fail?
-
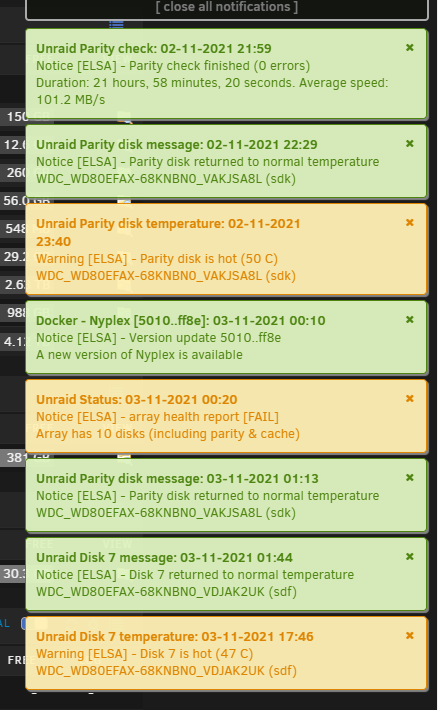
Hay guys! I get this: (fail) What is this? Efter I change the SSD disk too new on. elsa-diagnostics-20211103-1833.zip
-
Hi! Looks like I'm still having problems. Has removed the bad SSD disk from unraid. And set up a new vDisk and appdata storage folder on one of my file disks until I get a new SSD. But get this mld in LOG. Oct 25 23:10:45 Elsa nginx: 2021/10/25 23:10:45 [error] 7100#7100: *169 upstream timed out (110: Connection timed out) while reading upstream, client: 192.168.1.76, server: , request: "POST /update.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.30", referrer: "http://192.168.1.30/Settings/DockerSettings" And it takes a very long time and for example turn on/off the Docker service. New diag file here elsa-diagnostics-20211025-2314.zip
-
Yes I use normal disk right now and not the SSD But is slow like H*** I remove the SSD from the server . And it is faster
-
Oct 25 20:12:12 Elsa avahi-daemon[5765]: Joining mDNS multicast group on interface docker0.IPv6 with address fe80::42:b2ff:feca:b773. Oct 25 20:12:12 Elsa avahi-daemon[5765]: New relevant interface docker0.IPv6 for mDNS. Oct 25 20:12:12 Elsa avahi-daemon[5765]: Registering new address record for fe80::42:b2ff:feca:b773 on docker0.*. Oct 25 20:13:24 Elsa kernel: print_req_error: 2 callbacks suppressed Oct 25 20:13:24 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x1:(WRITE) flags 0x100000 phys_seg 1 prio class 0 Oct 25 20:13:34 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:13:44 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:13:54 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:04 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:09 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 32598576 op 0x1:(WRITE) flags 0x100000 phys_seg 1 prio class 0 Oct 25 20:14:15 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:25 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:27 Elsa kernel: vethd6499df: renamed from eth0 Oct 25 20:14:27 Elsa kernel: docker0: port 1(veth844bb46) entered disabled state Oct 25 20:14:35 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:45 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:46 Elsa ntpd[2033]: kernel reports TIME_ERROR: 0x41: Clock Unsynchronized Oct 25 20:14:55 Elsa avahi-daemon[5765]: Interface veth844bb46.IPv6 no longer relevant for mDNS. Oct 25 20:14:55 Elsa avahi-daemon[5765]: Leaving mDNS multicast group on interface veth844bb46.IPv6 with address fe80::4c7d:1cff:fefe:5e55. Oct 25 20:14:55 Elsa kernel: docker0: port 1(veth844bb46) entered disabled state Oct 25 20:14:55 Elsa kernel: device veth844bb46 left promiscuous mode Oct 25 20:14:55 Elsa kernel: docker0: port 1(veth844bb46) entered disabled state Oct 25 20:14:55 Elsa avahi-daemon[5765]: Withdrawing address record for fe80::4c7d:1cff:fefe:5e55 on veth844bb46. Oct 25 20:14:56 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0
-
Here it is I have just downgrader OS and rebootet (for test) elsa-diagnostics-20211025-2011.zip
-
Hey! I just make a new unraid docker image. And it slowe like a **** Dont now what is wrong. This is from Log Oct 25 19:29:30 Elsa nginx: 2021/10/25 19:29:30 [error] 6817#6817: *22324 upstream timed out (110: Connection timed out) while reading upstream, client: 192.168.1.76, server: , request: "POST /update.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.30", referrer: "http://192.168.1.30/Settings/DockerSettings" And when i add container. Oct 25 19:40:07 Elsa nginx: 2021/10/25 19:40:07 [error] 6817#6817: *24741 upstream timed out (110: Connection timed out) while reading upstream, client: 192.168.1.76, server: , request: "POST /Docker/AddContainer?xmlTemplate=user%3A%2Fboot%2Fconfig%2Fplugins%2FdockerMan%2Ftemplates-user%2Fmy-binhex-krusader.xml&rmTemplate= HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.30", referrer: "http://192.168.1.30/Docker/AddContainer?xmlTemplate=user%3A%2Fboot%2Fconfig%2Fplugins%2FdockerMan%2Ftemplates-user%2Fmy-binhex-krusader.xml&rmTemplate=" I just make a new docker on my disk and not SSD Reff:
-
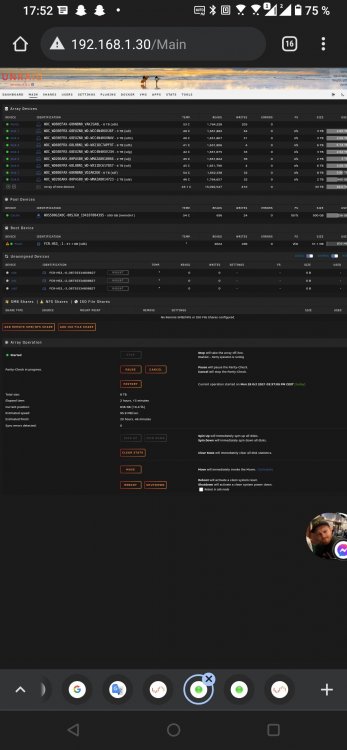
Ho. What this means ? I can enter the ssd ** Is broken ?
-
Hey:) After I had to kill Windows VM (when it was stuck) I could not turn it on again. I try and restart the server. Then suddenly all the VMs were gone and Docker service will not start. (Docker Service failed to start.) What happened here ? elsa-diagnostics-20211025-1717.zip
-
hoo no
-
Get this: Feb 22 17:27:48 Elsa root: mover: started Feb 22 17:27:48 Elsa move: move: skip /mnt/disk1/system/docker/docker.img Feb 22 17:27:48 Elsa shfs: set_nocow path: /mnt/cache/system Feb 22 17:27:48 Elsa move: move: skip /mnt/disk1/system/libvirt/libvirt.img Feb 22 17:27:48 Elsa root: find: 'system': No such file or directory Feb 22 17:27:48 Elsa root: mover: finished
-
Hooo thx!
-
Dont now I am new on this XD Shuld I ??
-
Now its gone. and the plex work norm again
-
Get this in my log: Feb 22 15:43:03 Elsa nginx: 2020/02/22 15:43:03 [alert] 6714#6714: worker process 30118 exited on signal 6 and transoc on plex is buggy. ( green legg) Feb 22 15:42:15 Elsa login[29970]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:17 Elsa nginx: 2020/02/22 15:42:17 [alert] 6714#6714: worker process 29969 exited on signal 6 Feb 22 15:42:17 Elsa login[29978]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:19 Elsa nginx: 2020/02/22 15:42:19 [alert] 6714#6714: worker process 29977 exited on signal 6 Feb 22 15:42:19 Elsa login[29987]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:21 Elsa nginx: 2020/02/22 15:42:21 [alert] 6714#6714: worker process 29986 exited on signal 6 Feb 22 15:42:21 Elsa login[29997]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:23 Elsa nginx: 2020/02/22 15:42:23 [alert] 6714#6714: worker process 29996 exited on signal 6 Feb 22 15:42:23 Elsa login[30005]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:25 Elsa nginx: 2020/02/22 15:42:25 [alert] 6714#6714: worker process 30004 exited on signal 6 Feb 22 15:42:25 Elsa login[30017]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:27 Elsa nginx: 2020/02/22 15:42:27 [alert] 6714#6714: worker process 30016 exited on signal 6 Feb 22 15:42:27 Elsa login[30027]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:29 Elsa nginx: 2020/02/22 15:42:29 [alert] 6714#6714: worker process 30026 exited on signal 6 Feb 22 15:42:30 Elsa login[30036]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:31 Elsa nginx: 2020/02/22 15:42:31 [alert] 6714#6714: worker process 30035 exited on signal 6 Feb 22 15:42:31 Elsa login[30044]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:33 Elsa nginx: 2020/02/22 15:42:33 [alert] 6714#6714: worker process 30043 exited on signal 6 Feb 22 15:42:33 Elsa login[30054]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:35 Elsa nginx: 2020/02/22 15:42:35 [alert] 6714#6714: worker process 30053 exited on signal 6 Feb 22 15:42:35 Elsa login[30069]: ROOT LOGIN on '/dev/pts/1' Feb 22 15:42:37 Elsa nginx: 2020/02/22 15:42:37 [alert] 6714#6714: worker process 30068 exited on signal 6 Feb 22 15:42:39 Elsa nginx: 2020/02/22 15:42:39 [alert] 6714#6714: worker process 30078 exited on signal 6 Feb 22 15:42:41 Elsa nginx: 2020/02/22 15:42:41 [alert] 6714#6714: worker process 30089 exited on signal 6 Feb 22 15:42:43 Elsa nginx: 2020/02/22 15:42:43 [alert] 6714#6714: worker process 30090 exited on signal 6 Feb 22 15:42:45 Elsa nginx: 2020/02/22 15:42:45 [alert] 6714#6714: worker process 30091 exited on signal 6 Feb 22 15:42:47 Elsa nginx: 2020/02/22 15:42:47 [alert] 6714#6714: worker process 30098 exited on signal 6 Feb 22 15:42:49 Elsa nginx: 2020/02/22 15:42:49 [alert] 6714#6714: worker process 30101 exited on signal 6 Feb 22 15:42:51 Elsa nginx: 2020/02/22 15:42:51 [alert] 6714#6714: worker process 30102 exited on signal 6 Feb 22 15:42:53 Elsa nginx: 2020/02/22 15:42:53 [alert] 6714#6714: worker process 30106 exited on signal 6 Feb 22 15:42:55 Elsa nginx: 2020/02/22 15:42:55 [alert] 6714#6714: worker process 30107 exited on signal 6 Feb 22 15:42:57 Elsa nginx: 2020/02/22 15:42:57 [alert] 6714#6714: worker process 30112 exited on signal 6 Feb 22 15:42:59 Elsa nginx: 2020/02/22 15:42:59 [alert] 6714#6714: worker process 30115 exited on signal 6 Feb 22 15:43:01 Elsa nginx: 2020/02/22 15:43:01 [alert] 6714#6714: worker process 30116 exited on signal 6 Feb 22 15:43:03 Elsa nginx: 2020/02/22 15:43:03 [alert] 6714#6714: worker process 30118 exited on signal 6 elsa-diagnostics-20200222-1546.zip
-
Shuld this MB work? ASUS ROG Strix X570-F Gaming, S-AM4 Gaming VM and Plex with GPU
-
Corsair HX1000i, 1000W PSU or 1200w ? What shuld i go for?
-
Hey! Is this USB card reader OK ? http://www.ebay.com/itm/NEW-Kingston-MobileLiteG2-Card-reader-external-Mac-PC-USB-/172256775178?hash=item281b4dcc0a:g:PXAAAOSwBPNXSG5u

