





Husker_N7242C
Members
-
Joined
-
Last visited
Everything posted by Husker_N7242C
-
Doesn't install. I'm on Unraid 6.12.13. It goes through the motions of installing but the appdata folder only contains an empty 'config' folder. I've rechecked mapping to appdata and recording, tried removing and reinstalling.
-
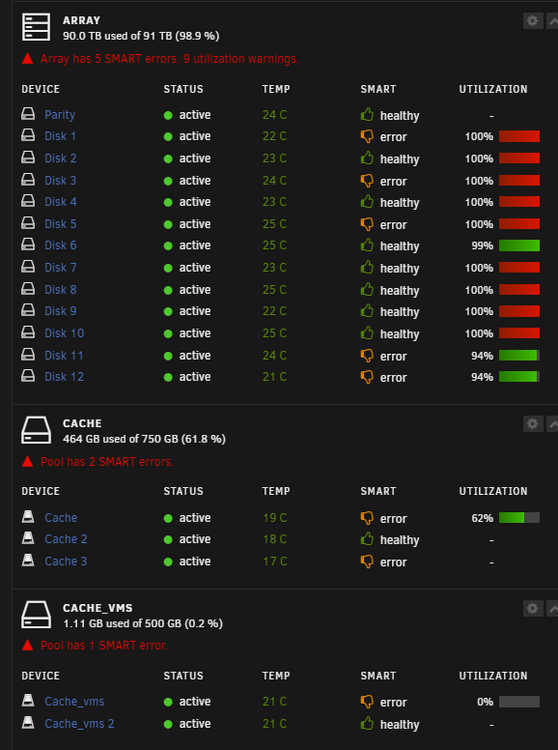
Thanks @JorgeBas always. Have I done something wrong to cause this? Should I replace any drives? I notice some have errors, all relating to "CRC error count" and giving me thumbs downs.
-
Hi all, Docker has stopped working on my server. I'm not 100% on the timeline because I moved house and it has been off for a while but I think what happened is I did an update right before moving to 6.12.10, it broke docker, I moved, turned it on 3 months later at the new house, docker still broken so I updated just now to 6.12.13 to see if that resolved the issue, it didn't. Any advice would be greatly appreciated. nas-diagnostics-20240913-1845.zip
-
Thanks so much for your help @JorgeB. It is up and running again with only 2 files in lost and found, most data looks intact. Are you able to shed any light on why the parity didn't emulate the disk contents in this instance?
-
Hi guys, I recently added a new parity disk, rebuilt parity ok then a couple of days later I had an issue with a power cable which caused read errors on multiple disks. I shut down the server prior to any disks being disabled and I replaced the bad cable. After replacing the cable and rebooting disk4 is unmountable. Parity should be valid, but contents of disk aren't being emulated. I don't understand why. I tried running xfs_repair -n /dev/sdp twice but the disk hasn't come good. Is there a way to emulate the disk so that i can copy the data to other disks and try re-formatting the unmountable disk? Attached is a screenshot of the GUI and diagnostics. Thanks in advance nas-diagnostics-20231102-1954.zip
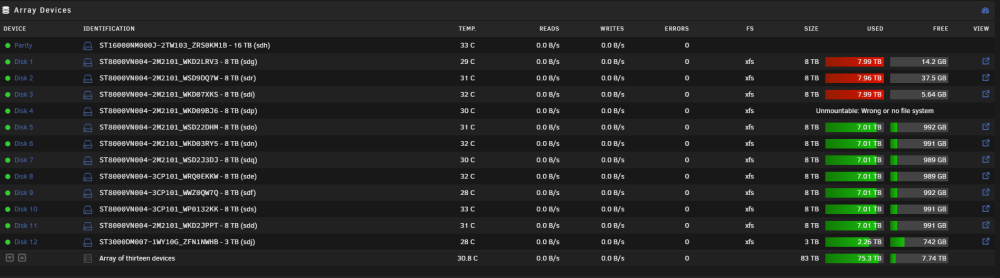
-
G'day ich777, I'm testing out your LuckyBackup container and I think there is a bug... When I backup from one UNRAID server to another UNRAID server using "backup source inside destination" with 10 snapshots enabled, then following happens: 1. The files are copied successfully 2. Modified files are stored in the snapshots folder within the destination correctly The issue is with restorations. No matter which snapshot I select, it only restores the latest backup set and seems to ignore that I've selected an older snapshot. This makes it impossible to restore any version of a file/directory apart from the latest backup. I can confirm the the older version of a file does get copied to the snapshots folder then the date/time folder and I can grab an older copy of the file out manually, however restore simply doesn't work as expected. Do you know of a way to fix this issue, or an alternate container that can do UNRAID to UNRAID backups with snapshots?? Many thanks for all of your contributions! Dan
-
(as in its cache of websites and steam games, not its appdata)
-
I finally worked it out. It was the lancache container's cache. It reported as practically empty but was hundreds of gigs. I moved to the array for now and will have a look at how to manage it's size better, assuming that it knows its own cached website data size correctly. Thanks @JorgeB & @trurl for trying to give me a hand!
-
Same. Some thing has changed very recently and the "Docker Safe New Permissions" is now broken because you can't set the include/exclude shares any longer. I'm stuck because I have all of my shares barring one excluded

-
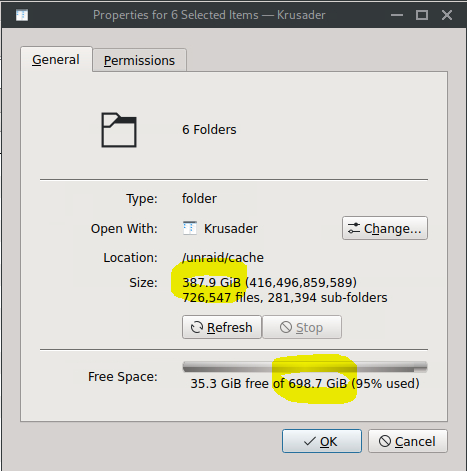
G'Day @JorgeB, All VM vdisks are on the other cache pool. The docker image, System folder, appdata and a few folders waiting for mover are all that is on this cache pool. All folders had been selected when I grabbed the total file size in Krusader.
-
Thanks. I thought it was RAID0 from the start. Just prior to posting I clicked "perform full balance", but then cancelled after reading forums and realising that it wasn't going to help. I wasn't attempting to change the RAID level.
-
I've used more than 375GB, it holds about 430GB when "full" at the moment. The GUI shows "Size 750GB"
-
@trurl nas-diagnostics-20221216-2350.zip
-
Hi guys, As the title says, my cache drive is nearly full but there is no where near 750GB of files on it. Any ideas why and how to rectify? Here are some screenshots from Krusader and the GUI

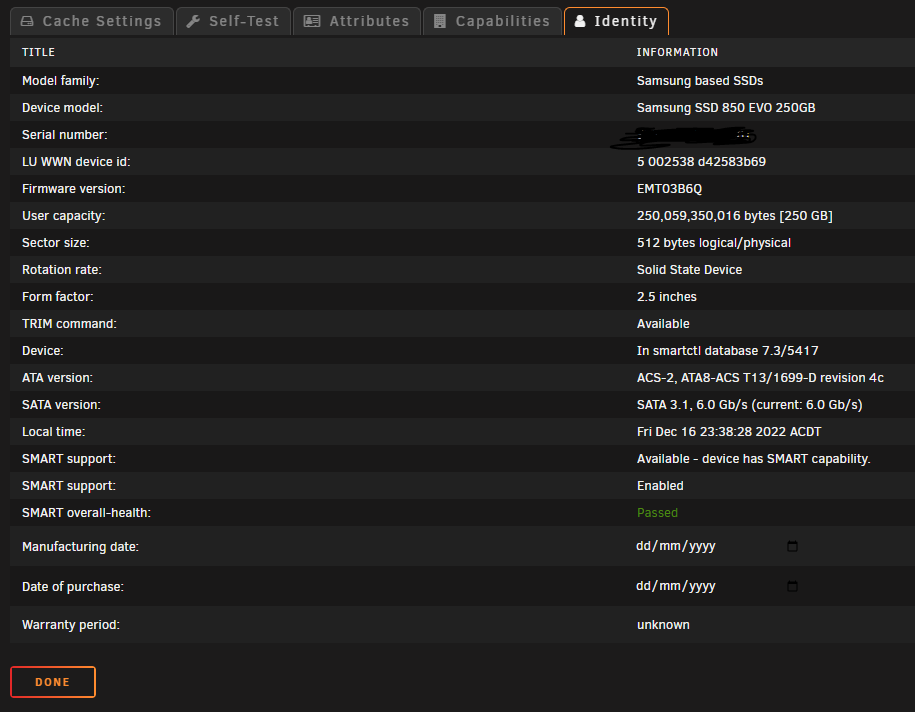
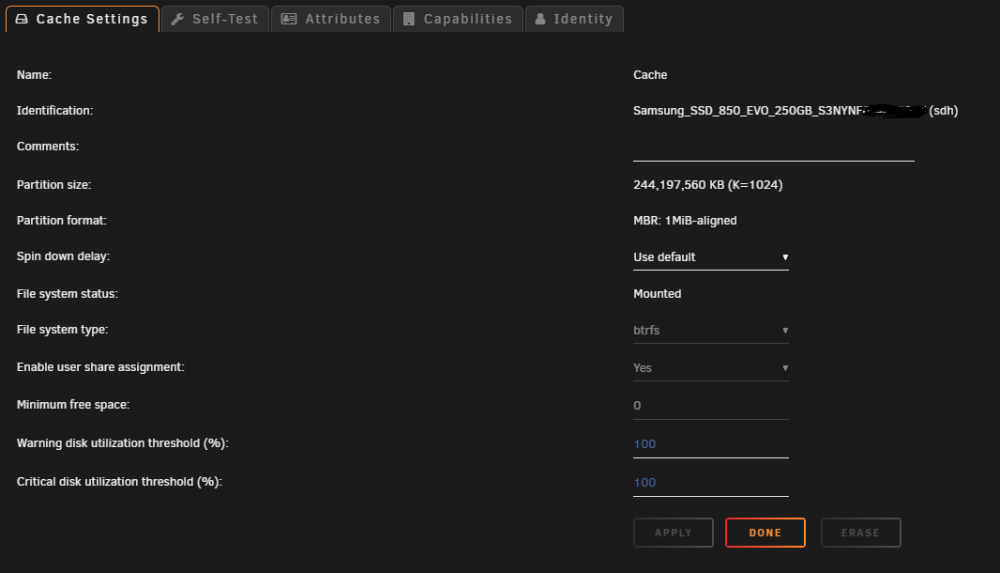
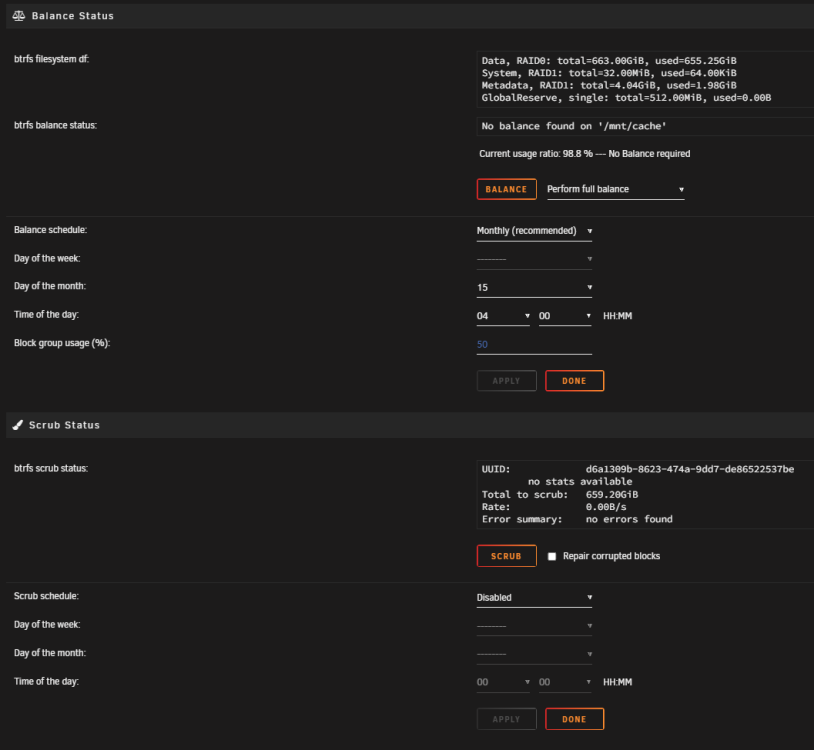
-
Thanks again @JorgeB, I've disabled spin-down now and will go through the process again for disabling EPC and low current spinup to be sure it is still applied. I was quite careful when I originally did this to be sure that all commands succeeded but you never know. I'll mark your response as solution and get back in touch if re-applying the workarounds don't prevent this. I want to avoid having the drives continuously spun-up as we are just coming into summer in Australia and the server's room isn't airconditioned so I try to keep it as dormant as possible during the middle of the day, no downloads, no transcoding, just a couple of VMs on the SSDs (with 12x 140mm Noctua fans) then let it all rip at night.
-
Thanks @JorgeB as always for responding, however I've been through the process HERE to disable EPC and Low Current Spinup for all of these drives in the past. Is there anything else in the diagnostics that looks wrong? I'll disable spin-down, add the drive back to the array and wait for it to happen again, that we I can be possitive it is/is not this known issue. Just to double-check - if I stop the array, remove the disk, start the array and then stop the array again, re-add the disk and let the array rebuild, will I loose any data written to disk2 (currently emulated) since it was disabled, or does the drive get rebuilt from parity information instead?
-
Hi everyone, My old server had continuous issues with disks being disabled, yet being found healthy. I never could get to the bottom of it. I rebuilt the server: -New motherboard (brand new, old stock, SuperMicro X10-DRH-CT) -New CPU(s) (used E5-2690V3 x2) -New RAM (128GB DDR4 ECC) -New HBAs (and SAS-Sata cables) (LSI 9207-8i x2) -New USB Flash Drive (Sandisk Cruzer Blade 32GB) -New Power Supply (850w Corsair) I Ran it for two weeks on Windows (no HDDs) and run many hours of stress-testing to ensure the temps stay low nothing failed out of the box. I transferred over the disks and flash and all seemed well for a week but I've just had disk2 disabled due to read errors. The drive isn't that old and the dashboard reports "Healthy"... but disabled. I'd really appreciate it if anyone with more knowledge than me had a look at the diagnostics (attached) and could make some recommendations? If you need any more info please let me know? Dan nas-diagnostics-20221202-1659.zip
-
Hi everyone, Can anyone tell me if I'd be able to use the built-in LSI 3108 controller on the Supermicro X10DRH-C motherboard for UNRAID? Is it possible to flash this to IT mode? (I have no experience with built-in raid cards and only a little with PCI-e add-in cards. Also no experience with Supermicro BIOS or flashing them). Product Page - https://www.supermicro.com/en/products/motherboard/X10DRH-C PDF User Manual - https://www.supermicro.com/manuals/motherboard/C600/MNL-1628.pdf
-
Thanks! I've had 3 of these Crucual MX500 250GB drives fail super early. The 500GB seem to be better but the 500GB drives are only holding v-disks, so maybe the 250GB drives got a bit thrashed.
-
Hi everyone, I found that Docker had crashed somehow. Stopping and starting docker didn't resolve it so I rebooted the server. It took about 10 minutes to stop the array and then when it came back online got stuck at starting array for a VERY long time. It seemed to be doing something but super slow. There is an I/O error repeated at the end of the syslog attached, not sure if it is related or not (or what it means). Any help interpreting the diagnositics would be greatfully received. Daniel syslog nas-diagnostics-20220725-1904.zip
-
Looks like you are right! Version 5 doesn't support ECC. Higher versions don't support older BIOSs... guess unraid is stuck between a rock and a hard place... or should include both and descibe the choice in the boot menu... or just remove it completely. I think I would have seen this if I had to download and create a boot USB myself but missed it because I know UNRAID recommends ECC memory, so incorrectly assumed that the memory tool packaged with OS would work with ECC memory. Probably needs a re-think.
-
It's just an ASRock x79 Extreme 11. Pretty cool board (for it's time) but I don't know of any diagnostic tools like that for it. It threw a boot code last week before I ran all of the memory tests but the code was a general memory error that didn't indicate a particular dimm.
-
Unfortunately not, it is nearly 40MB of "Location: SOCKET:0 CHANNEL:? DIMM:? []" in the syslog from the crash. When I look at cat /var/log/syslog now (after hard reset) it doesn't mention memory errors yet.
-
Thanks for replying again. Of the 8 dimms, it is possible that there could be more more than one with a fault. It is also quad channel so would have to remove more than 1 at a time and it will be a LONG process to eliminate. There MUST be a way to scan the memory properly. If UNRAID can encounter the issues within 24 hours so consistently, surely a memory testing program can too. I'll check the system event log as well for a hint
-
The one that comes with UNRAID. From what I can see, memtest86 supoprts testing ecc memory. Is there another version that would be better for DDR3 ECC?










