Airless
Members
-
Joined
-
Last visited
-
Awesome, thanks all! Looking forward to the final release.
-
I haven't. I'm not keen on updating to a pre-release version on my main/only unraid server. I did look through the change logs for rc3 and rc4 and didn't see any mention of the smartctl package being upgraded. Someone who has the latest RC installed what does the following output for you? smartctl --version If I don't get any answers by the weekend I'll see if I can setup a little trial instance. If SMART isn't updated I guess submitting a feature request is my best bet?
-
Hi there, One of my drives seems to be affected by this reported bug in the smartmontools tracker for v7.1 of the tool. https://www.smartmontools.org/ticket/1346 My drive is a ST2000NMCLAR2000 and just as reported doesn't show much SMART data and cannot run self tests. The issue does not occur in 7.0 and is fixed in 7.2. Is it possible to update the tool myself? What are the odds smartctl could get updated to 7.2 in the next update of Unraid? smartctl 7.1 is over 2 years old at this point. Thanks
-
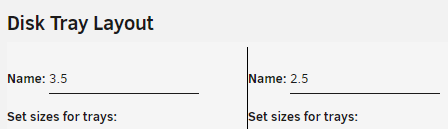
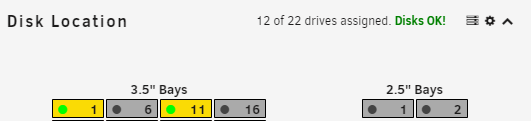
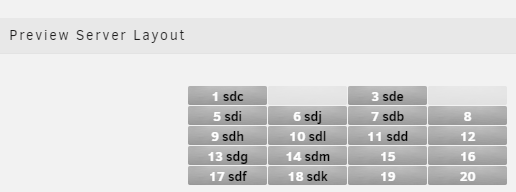
Thank you so much for the great plugin. I'm migrating over from the Server Layout plugin and have a couple of low-priority comments/suggestions. BUG - Disk Group Name Special Characters The Name field in a disk group doesn't seem to handle the " character correctly. For example if I type the name 2.5" Bays the field only shows 3.5 This only seems to be an issue with the input field itself as all other areas the name is displayed shows text after the " character. SUGGESTION - Disabling Bays I read through the few times this feature has been brought up in the thread and completely understand that it's impossible to support every case configuration under the sun. However, I think the way the Server Layout plugin handles this is a fairly simple implementation and would make this plugin quite a bit more powerful. The other plugin allows you to click on bays when configuring to hide them from being rendered (examples below). This all allows me to better match the layout of my server with 2x2.5" bays at the top and 16x3.5" bays in the bottom. Of course, you're volunteering your time to build this and it may be more difficult to implement than it appears on the surface. I figured it was at least worth showing how this has been implemented in other places in case it inspires new features and ideas Thanks again for all of your hard work.