




mpiva
Members
-
Joined
-
Last visited
-
Adding this two topics, might be related to the same issue: https://forums.unraid.net/topic/188403-passthrough-of-arc-a380-to-windows-11-vm/#findComment-1593728
-
VFIO / Intel ARC Passthrough IssueCurrently passing through an Intel ARC A380 (primary GPU) to a VM. Passthrough itself works fine, the VM starts and runs without issues, unraid perfectly fine after loosing GPU. Problem (on VM shutdown)After stopping the VM, the following error appears: vfio-pci 0000:08:00.0: not ready 678ms after FLR; waiting ... vfio-pci 0000:08:00.0: not ready 65535ms after FLR; giving upDevice layout: 08:00.0 → GPU 09:00.0 → Audio After this: PCIe subsystem becomes unstable (“PCIe basically dies”) Unraid is left in a bad state, unable to shutdown. Current behavior Only way to recover: full power cycle A simple reboot is not enough, the GPU does not come back System behaves like the PCIe bus is stuck after failed FLR QuestionIs there a way to prevent vfio-pci from issuing an FLR (Function Level Reset) when the VM shuts down? I understand this may prevent restarting the VM without a reboot, but that’s acceptable. I want to avoid the risk of having unclean shutdowns, and parity checks every time. Avoiding the broken PCIe state is more important than VM restart capability. What’s been tried VFIO hooks → ineffective (reset happens before stop hook run, or at least, it seems) Current startup vfio-pci.ids=8086:56a5,8086:4f92 video=efifb:off video=simpledrm:off video=vesafb:off pcie=noaer pcie_acs_override=downstream,multifunction isolcpus=8-15,24-31 also blacklisted i915 from modprobe. BTW, Unraid and the VM both run perfectly. However, shutting down either the VM or the system consistently results in an unclean shutdown, requiring a manual power-off.
-
Thanks JorgeB
-
Catch-22 situation I have new disks that are all larger than the current parity drives. When a disk fails, the standard procedure is to replace the failed disk with a new one. However, the system refuses the replacement because the new disk is larger than the parity drive. Question: why? The system should allow installing the larger disk and use it up to the size supported by the current parity drives. It should then automatically expand to the disk’s full capacity once the parity drives are upgraded to larger ones. Do I miss something, or this limitation can be overriden?
-
SFF-8087 to SATA. Will try to replace the cables. Thanks for the advice, btw, is not the first time, some disk drop from the raid before. (But never like above screenshot). Is this a common occurrence? Can Unraid handle this better? after all if there is no I/O against the disk when the disconnect/connect occurs. Unraid should gracefully handle, since there was no data lost.
-
Here, after I while both disks dropped from the raid. Recommendations? Double restore from parity disks seems dangerous. maxraid-diagnostics-20250429-0704.zip
-
Happens after a week or so. No reset. In the raid disks appears with an * in the temperature. Clicking on the link shows the disk content. But they also appear in unassigned disks. Why this happen, is the raid in risk? Everything seems to be green. Some Guidelines?


-
Totally right. It was a user script, that got incompatible with latest mover. Thanks
-
Also removed CA Mover Plugin just in case. And also installed the new CA Mover Plugin (the one supporting unraid 7) no avail. mover is always executing.... Oct 5 23:09:48 MAXRAID root: Starting Mover Oct 5 23:09:48 MAXRAID root: ionice -c 2 -n 0 nice -n 0 /usr/local/emhttp/plugins/ca.mover.tuning/age_mover start Oct 5 23:10:02 MAXRAID percent_mover.sh[1587592]: Cache is 1141671% full, which is greater than or equal to the set point of 80%. Running mover. Oct 5 23:10:02 MAXRAID root: Starting Mover Oct 5 23:10:02 MAXRAID root: ionice -c 2 -n 0 nice -n 0 /usr/local/emhttp/plugins/ca.mover.tuning/age_mover start Oct 5 23:11:07 MAXRAID ntpd[931836]: 10.0.0.1 on 2 br1 -> *multiple* Oct 5 23:11:07 MAXRAID ntpd[931836]: 192.168.1.5 on 1 br0 -> *multiple* Oct 5 23:15:01 MAXRAID percent_mover.sh[1622722]: Cache is 1141671% full, which is greater than or equal to the set point of 80%. Running mover. Oct 5 23:15:01 MAXRAID root: Starting Mover Oct 5 23:15:01 MAXRAID root: ionice -c 2 -n 0 nice -n 0 /usr/local/emhttp/plugins/ca.mover.tuning/age_mover start Oct 5 23:16:08 MAXRAID ntpd[931836]: 10.0.0.1 on 2 br1 -> *multiple* Oct 5 23:16:08 MAXRAID ntpd[931836]: 192.168.1.5 on 1 br0 -> *multiple* Oct 5 23:17:27 MAXRAID flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Oct 5 23:20:01 MAXRAID percent_mover.sh[1659059]: Cache is 1141671% full, which is greater than or equal to the set point of 80%. Running mover. Oct 5 23:20:02 MAXRAID root: Starting Mover Oct 5 23:20:02 MAXRAID root: ionice -c 2 -n 0 nice -n 0 /usr/local/emhttp/plugins/ca.mover.tuning/age_mover start Oct 5 23:21:09 MAXRAID ntpd[931836]: 10.0.0.1 on 2 br1 -> *multiple* Oct 5 23:21:09 MAXRAID ntpd[931836]: 192.168.1.5 on 1 br0 -> *multiple* Oct 5 23:25:01 MAXRAID percent_mover.sh[1695345]: Cache is 1141671% full, which is greater than or equal to the set point of 80%. Running mover. Oct 5 23:25:02 MAXRAID root: Starting Mover Oct 5 23:25:02 MAXRAID root: ionice -c 2 -n 0 nice -n 0 /usr/local/emhttp/plugins/ca.mover.tuning/age_mover start Oct 5 23:26:10 MAXRAID ntpd[931836]: 10.0.0.1 on 2 br1 -> *multiple* Oct 5 23:26:10 MAXRAID ntpd[931836]: 192.168.1.5 on 1 br0 -> *multiple* Oct 5 23:30:01 MAXRAID percent_mover.sh[1732330]: Cache is 1141671% full, which is greater than or equal to the set point of 80%. Running mover. Oct 5 23:30:02 MAXRAID root: Starting Mover Oct 5 23:30:02 MAXRAID root: ionice -c 2 -n 0 nice -n 0 /usr/local/emhttp/plugins/ca.mover.tuning/age_mover start Oct 5 23:31:11 MAXRAID ntpd[931836]: 10.0.0.1 on 2 br1 -> *multiple* Oct 5 23:31:11 MAXRAID ntpd[931836]: 192.168.1.5 on 1 br0 -> *multiple* maxraid-diagnostics-20241005-2339.zip
-
-
I think, that was the setting I have before, and that's why I rationalize it as auto-triggered. I was just editing my post when you responded. Is the below possible?: Probably what I want can be solved with multiple schedules: One is 4:00 AM with 50% (real schedule) and other every hour with 95% (pseudo auto-trigger) The rationale, Is, that if you put 95% in the schedule at night, and you have it 80% full at night, it won't trigger, but if you move that 20% left the next day, you will be out of space, in the middle of the day, forcing to run the mover in the day with the accompanying server degradation at that hour) And if you have 95% every hour, it will trigger when it reaches that threshold. Independent of the night, when the server degradation is preferred. With both schedules, you're fresh every day to fill your raid with 50% (45%) of the cache without worrying about the mover, and the mover runs only at night, giving you no degradation during the day, and in the case, you almost fill the cache, the hour schedule will act as a fallback in case you moved to much.
-
IDK, every time the cache is almost full, it triggers automatically in my setup. It doesn't wait till the scheduled time, My question is related to the %, if it applied, to the schedule, and the automatic trigger. Sorry misunderstood, gotcha. How min free space on the shared work on the cache, I thought the parameter was related to the storage in the raid. Probably what I want can be solved with multiple schedules. One is 4:00 AM with 50% and other every hour with 95% Again, the rationale, Is, that if you put 95% in the schedule at night, and you have it 80% full at night, it won't trigger, but if you move that 20% left the next day, you will be out of space, in the middle of the day, forcing to run the mover in the day with the accompanying server degradation at that hour)
-
First, @Reynald thanks Question: What are the settings for the following scenario: I want the Mover to trigger when SSD/s becomes almost full automatically. IE: 95% But, at the same time, I want it scheduled every day at 4:00 AM, to move if threshold is bigger than 30%. The rationale is the following: When moving a high amount of data to the array. Trigger automatically at 95%. But as a maintenance schedule, move, the not prefer cache files to the array, on the night.
-
I partially fix the issue, following Matias Hueber's "Performance optimizations for gaming on virtual machines (mathiashueber.com)" on his site, mentioned the topology of a Ryzen Processor . If you see his configuration it uses the second CCX for the guest The strange thing, is the ordering is the same in the web UI. Which means cpuset = CPU number in UI. With the above all the HTs will be light up. But notice the CPU pairing is CPU 0 and CPU 8, CPU 1 and CPU 9. When in the above graphics the pairing is [CPU 0, CPU 1] [CPU 2, CPU 3] So my question is, which one of this are wrong? It seems the UI is showing the wrong pairing. I used the UI to create the cpuset, and seems that created the bottleneck. IDK: if this also is replicated on CPU Pinning but since the UI is the same I guess so.
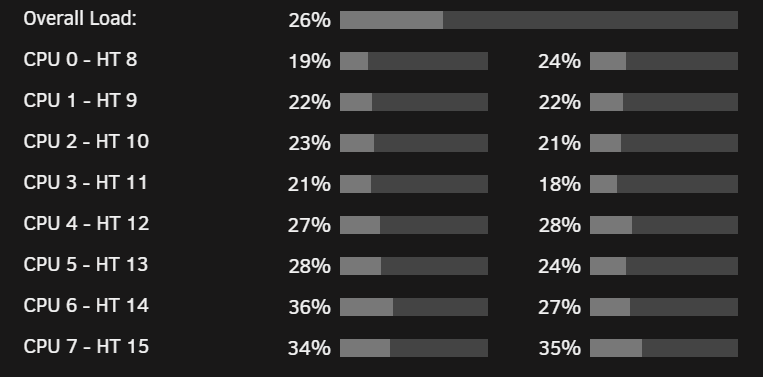

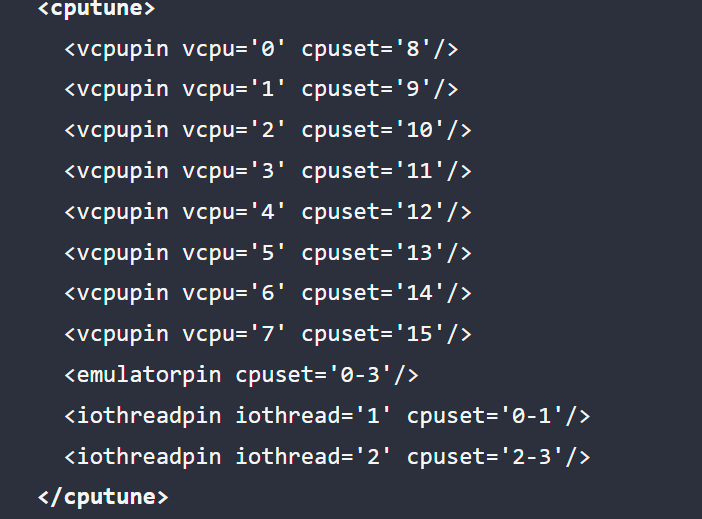
-
This happening for a long time, since Windows 10, updated virtIO several times. Current running version 100.90.104.21700 (2/23/2022). The strange thing is, it's not related to the SSD cache. But entirely when mover is running VM virtio network goes down to 4 MB/S. IN/OUT the unraid. Per example, if, I mount an external share from another computer in Unraid GUI, and start copying to unraid when mover is running I got 110 MB/S probably maxing the network. So there is no bottleneck on the SSD cache (2XSATA SSD in RAID-0). Tweaked iothreadpin on the VM, with no improvements. I'm kinda baffled, where the bottleneck is, Running Ryzen 1700. CPU usage when mover is running is negligible. Of course I tested it without any load. And the issue remains. Any clues, where the bottleneck exists?





