

bsim
-
Posts
191 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by bsim
-
Is there a method to how you arrived at these numbers or has it been mainly through trial and error? How would cutting down the memory size to 8GB affect the numbers?
-
automatic run parity check, web interface locked, crashed
bsim replied to bsim's topic in General Support
Has tunables been worked out as far as knowing typical usage values for an 8GB dual processor server? I saw that 6.1.4 introduced md_sync_thresh (default set to md_sync_window/2)...I've read all of the site on tunables, but other than the default being made for 512M memory, and finding a lot of cryptic guesses and wild testing goose chases...I can't find a good solid list of tunables to support much more memory. I've seen the tunables tester script, but it hasn't been updated in several years. I attached a current list of my tunables for a 24 drive array with 8GB...are they too aggressive? With these settings, a full parity check only uses 26% and 38% of memory. I pulled my defaults from...now seeing it was for a 32GB system...perhaps I was a bit too agressive.

-
automatic run parity check, web interface locked, crashed
bsim replied to bsim's topic in General Support
Restarted Parity check...one of my ST5000DM000's came back with a ton of parity errors! Of course just outside of warranty, but also found drive was a referb and not new...ordered from Amazon as new! Time for the old swapola! For the future...is there a clue in the syslog that would have clued me into an issue with one of the drives failing a parity check before I run it? -
Running the latest version of unraid, first monthly full parity check with latest version...web interface not existent...pings fine, can ssh to server fine...tried diagnostics from the command line and pulled syslog directly...when attempting to copy the zip/syslog through winscp, the small file copy kept on hanging, disconnecting and I had to keep reconnecting/resuming the file to get it finally...his is what I got...Is this a kernel/memory issue? Raid card did not scram any of the drives (from the raid network interface)...Nothing has been touched on the server for several months now. syslog-2018-11-02 CUT.txt EDIT: suspected that the docker container that I have autoupdating was causing issues, I shutdown the docker (/etc/rc,d/rc.docker stop), it did stop successfully...I then issued powerdown -r and it is taking forever "unmounting local filesystem"... it had a few errors too...attached a screenshot. It took forever to finally release the local filesystem before reboot...luckily, it did shut down gracefully...I seem to have bad days when a hard boot is necessary! We'll see if the problem rearises. restarting parity check.


-
Just got the latest 6.6.1 and saw that there were a few smart updates in the previous couple versions...Got me excited thinking my Areca situation may be changed...Noda...🤣 Will emhttp ever support the non standard smart commands enabling dashboard/main reporting of actual temps?
-
I think there were 3 or 4 boxes for 6.3.5 as well, but only two were pertainent...now with 6.4 only the two boxes are there.

-
The first box after specifying areca would be the port on the areca card the drive is on, first number counts, second one ignore...pain in the butt to connect with the actual drive...you have to pull a manual smart report and correlate with serials...I use this for each of the 24 slots... echo -n "01" ;smartctl --all --device=areca,1 /dev/sg24|grep "Serial Number:"|cut -d ':' -f 2 echo -n "02" ;smartctl --all --device=areca,2 /dev/sg24|grep "Serial Number:"|cut -d ':' -f 2 ... the second box would contain the address from lsscsi -g|grep "Areca"
-
The dashboard and the main page (emhttp) are the primary places of non functioning smart. I'm not going to enter each drive page to verify temperature of each drive when I have a dashboard/main page that displays the data front and center incorrectly? As of the last version of unraid I never received any notifications of pending sectors even though I had two drives launch to huge error numbers with all of the drives having the correct smart data pulled for each individual drive (seperate drive settings). The separate smart drive pages work with the custom smartctl settings, but the notifications never triggered...has something with them changed in 6.4? Do the notification thresholds in the smart page reflect on the notifications on the dashboard status page (red icon for problems)? Also, it looks like the second half of the smart information page seems to pull some sort of corrupt data?




-
Sorry if I seemed a bit brusk...just frustrated...SSD, I love the knowledge sharing, but for most speed has always taken a back seat to problems. I've been a network engineering/consulting for a couple decades so I understand the internal bus limitations very well. But I've always found that there is a sweet spot between cost and speed. The two sides of my issue with unraid usually come down to two types of users/administrators. One group sees the customized smart page per disk and the overall disk smart defaults page and see the problem solved. This group usually doesn't have the controllers in question and don't see the glaring issues in unraid that are deep inside the core of unraid. The second group (usually has to deal with the controller every day in question) and has to jump through hoops to use a controller that would cost several hundred to several thousand dollars correctly through the native unraid interface. I'm guessing the couple of guys that wrote the interface for the custom smart data were in this group. From other posts, it seems that the Tom sees the issue with emhttp, but from my own digging around through emhttp's code, it looks like the fix would probably require quite a bit of rewrites in the base coding. I'm thinking the base coding was written the way it was because at the time smartctl (which unraid relies on heavily) did not support custom controller configurations/command switches. A few guys stepped in (probably had to deal with their own controller issues) and wrote the special handling pages for smart controllers that were now supported by the new smartctl command line options. But unraid hasn't went back to internalize the third party additional work so that the three or four big problems are taken to heart. Hence core support issues. I'm guessing the several problems haven't been internalized because smart is always been treated as a secondary issue that tends to be a bit hokey pokey. A nice to have, rather than a signaling (full of false positives and potentially false negatives) of potential future issues. The current issues with the core unraid special controller support from what I've researched... 1. Main temperatures page does not show current temps of any non-generic smart controllers 2. Generic smart commands are issued to non-generic smart controllers (causing console errors with sense data) 3. Preclear not being able to record correct smart data to determine if there is a potential problem 4. The Unraid Dashboard not showing if potential smart signals are flagged for a specific drive (red errors for reallocated for instance) 5. Smart error warnings not being flagged in unraid notifications What I wrote in https://lime-technology.com/forums/topic/56820-bad-missing-sense-key-scsi-data/ was an attempt to start a discussion on future unraid full support of non-generic controllers since smartctl has been supporting them since something like 5.3 (unraid 6.4 now running 6.5)
-
Uhh...If you can find a spinning consumer drive that dumps at 180MB/s...I would love to see it and anyone running a 70TB SSD array wouldn't be interested in using my sub 100$ drive controller. My Areca spin downs are disabled on the controller and in unraid. I'm thinking you have my thread confused with a different thread, as I'm not having the sense data logging problem, as I have given up on the hopes of unraid supporting non generic smart data natively throught the emhttp interface. My previous reply at the end, was directed towards another user that had not read the entire thread and commented on the sense data issue that is caused by unraid emhttp generic native commands being issued to a proprietary controller not using the special smartctl switches. Please read the thread and stop hijacking the conversation, simple mathmatics and my usage habits tells me I'm ok with my array speeds. My issue, as originally stated, was having the main page support (emhttp) reporting the correct smart temperature instead of the default 30 degrees.
-
https://lime-technology.com/forums/topic/56820-bad-missing-sense-key-scsi-data/
-
I would say to get full support of the cards, a few of the hard codings of generic smart data pulls (in emhttp?) would have to use the per disk interface or the global disk interface settings using the specific drive controller settings. I love Unraid, and it's awesome flexibility...but having a lack of a specific mfg controller support when packages like smartctl have started supporting them (how many years ago? smartctl 5.39 supported Areca!), is a MAJOR issue, left looming is terrible, and negates the entire purpose of the smart statistics attempting to notify of eminent drive failure. For a system that is interested in data integrity, at least following up on smartctl's added support for special controller cards (happened a long time ago) should be followed as hard as possible. I agree that mfg implementation of smart data can be a bit flaky, but with smartctrl now having support, it's time to give the hard coded generic smart data retrieval attempts in unraid another revision. The pages that were added by the few users to support the non-generic smart controllers was a big help, but without core support in unraid, users data is threatened in one more way by not supporting the data points being exposed by every drive manufacturer out there. I agree that the smart data can be a bit hazy for predetermination of problems, but with a few of the backblaze papers out there, there are at least a few of the smart data points that should be at the heart of unraids notifications regardless of whether they carry the caveat of potential false positives! Data integrity seems to be the goal of unraid, harder incorporation of any data to that end, regardless of how heavily weighted the data may be, should be a core of unraid. Thoughts?
-
Yes, I understand the limitations of the 24 port card, but with the exception of local server use, anything beyond the gigabit network connection throughput to it is moot. The parity check for a 70TB server isn't going to be a quick one anyway, but using only spinners (except a direct to motherboard btrfs ssd mirror cache pool), I don't expect it to ever be. I regularly do parity checks at the beginning of each month which may cause a bit of a slowdown during those delightful few days. This isn't a high availability system, only running a few vm's off the cache set, streaming and backups. I have cat6a ran in many places at this point, so if I ever decide to jump to 10Gb network, I may do something with the card in the future. I understand all the nuances of using smartctl and it's command line, and yes, under each specific disk, if you put in the controller slot and the controller address you can get the smart listing under each disk. The smart default page for all the disks only helps with inputting the controller address (which changed between 6.3 and 6.4 btw from sg25 to sg24). This enabling does not help for any system alerts (especially for temp) or any preclear reporting. The emhttp is the source of many of the main smart config interests, and it doesn't use the drive config options under each drive...it is hard coded to use generic smartctrl commands and not the special areca, 3comm...etc...switches. The most obvious limit to this is that the main page will always be stuck at 30degC regardless of the actual temps. The bad or missing sense data is a pain in the butt on the console, but 6.4 may have changed some of that (not sure because all of my drives have to manually be reset to the new controller address...fun, fun)
-
I've went through some of the coding of the emhttp (main page temps) and have found a few locations that the infamous "30" degree comes from (looks like a default for no values)...I considered going through and attempting something, but without a larger overhaul of how unraid handles smart from all the different controllers, I may just keep doing about the same thing as you have with a single motherboard connected bay in 24 rack just for preclear smart info collection. Just sucks that most of the alarms/notifications available in the basic unraid aren't available for my ARC-1280ML 24 port with 2GB...was excited to get it for only 70$ on ebay! The onboard Areca web interface for the controller is pretty clean, just sucks not having the alarm functions support in unraid. Reading a few of the posts on areca support, it looked promising, but may have fallen to the wayside by unraid devs.
-
I haven't really been able to find a fix for this, from my research, the temperature of a drive on the "Main" page is pulled through hard code in emhttp, rather than using the settings for each disk's smart. I can get the smart data for each drive pulled correctly for each drive in their individual disk properties, but I can't get the "Main" temperature to change. Has anyone figured out how to change these temperatures? Is this an issue that Limetech would ever tackle?
-
From researching in the forums, i learned that the temperature display in the Main page is inside emhttp. Is there any update on if emhttp will support areca temperature on the Main page? Is there a way to modify emhttp after boot to pull the correct values?
-
Strange Issue with drive preclear on Areca controller
bsim replied to bsim's topic in General Support
This is very strange... So I switched the new drive over to the motherboard sata ports...refreshed the plugin page, still (broken) what I see from the preclear plugin is attached... I dropped to the old 1.15 preclear on the command line and it works beautifully... I uninstalled the preclear plugin, reinstalled it and everything shows up ok now! Is it possible there was a conflict with a dependency?

-
Running Unraid pro 6.3.5 on an Areca 1280...replacing a bad drive (final drive left of a great Seagate Barracuda ST3000DM001 collapse (6 drives in 8 months)...but I digress...I always preclear before assigning to array. New drive out of box, inserted on workstation...pulled smart and smart short test beautifully...stuck it in open server slot...Drive shows up clearly (serial/model) under "Unassigned devices", but shows as being spun down, never happens this way, clicking spin up doesn't spin it up... Going to latest preclear plugin to see if it will show...preclear shows drive letter but no model/serial number string, just an underscore...very creepy. If I stop the array, the drive correctly shows as a replacement drive option for any of the available drive assignment slots. If I change the physical drive slot in the server, same issue. The onboard raid card web interface shows that the drive is up and running as normal. Attempting to run the ancient preclear script (1.15) from the command line, shows the drive being available correctly, but gives me a problem with the smart not being able to get information from the drive (as expected), as smart support for Areca is still all screwed up in unraid and even with special configuration options doesn't really work in the web interface. I have rebooted the server with no changes...almost nothing in the logs that shows an issue when inserted...does anyone have a guess as to a why or fix?



-
I just didn't run the last slots of each controller and it did work ok. I've since moved the array to an entirely new mb/proc/mem/raid controller and didn't have to dance around it for too much longer.
-
I have an Areca 1280 24 port card, and I've went through each disk individually and entered the correct Areca slot/controller location information so that every drive separately now pulls all correct smart data and drive information. The next question is why the "Main" page still shows the temperature of all drives on the controller to be an apparent generic 30 degrees, when all the drives are in fact different temperatures according to their individual smart readouts. Is there something special needed to get those values to be accurate? Apparently they don't pull their data using each disks smart settings. All other drives (on different controllers) list their temperatures accurately. Any ideas?

-
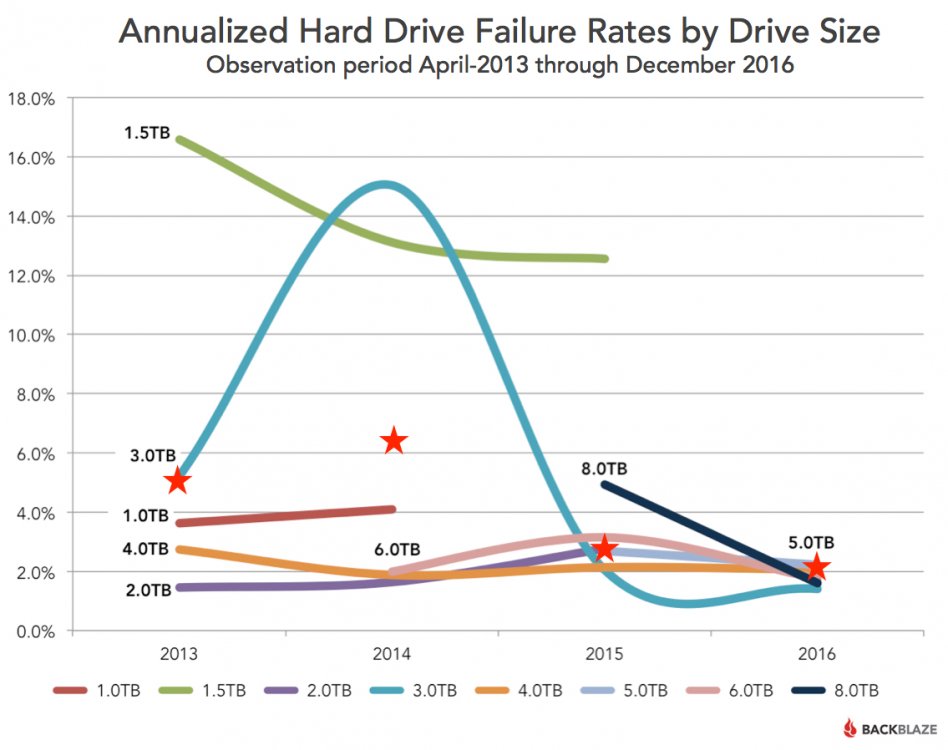
Folks, we've seemed to get off topic here...I agree every hard drive manufacturer sh*ts the bed every now and again, but hard drives are getting more reliable, for cheaper. I like backblaze (and many many companies subscribing to the core RAID premise... "Redundant Array of Inexpensive Disks") purchase drives by cost and not reliability (Seagate makes the cheapest/TB drives) which guarantees that I will have to replace drives, but the system they are part of will survive. Assuming failure rates at a random and consistent interval, buying "NAS" drives makes no sense (as their costs/TB are nuts). My stats on this model happen to be almost perfectly in line with backblaze, and I don't hammer drives all day long. From what I've read, the problem was that the model didn't have a vibration mitigation system that is normally part of a modern drive...meaning just powering on the drive in a array causes degradation. I started the topic to find out if anyone has heard anything about the status of the class action lawsuit because of the bad drive model. The reason I ask, is I've had 4 of the bad models (of 24 total drives) die instantly on me in the last 3 months. Thank you unraid for dual parity! The drives do run 24/7, are housed in a solid, protected and well ventilated system (drives don't hit 30 degC).
-
With the money I save on buying Seagates, I can afford to have a free one one every 4th drive. Raid for high end consumers requiring lower availability and high reliability is aiming for lowest priced drives (just as raid has classically aimed for). Just a bad run of drives, overall all drives are getting more reliable for less money...just sucks how much of a friggin monopoly the drive market is becoming ever since the flood. I remember really nice hitochi drives for 70$ before that! They dropped their warranties because they realized that their product model was a dog with a bad case of fleas. I've researched that the ST3000DM001 was the only drive without a rotational vibration sensor that counteracts excessive vibration in heavy-usage cases. Simple articles... https://www.extremetech.com/extreme/175089-who-makes-the-most-reliable-hard-drives http://www.zdnet.com/article/ssd-reliability-in-the-real-world-googles-experience/
-
Anyone heard of the Seagate ST3000DM001 class action lawsuit? A group of lawyers are suing Seagate for the crappy drives (80% failure rate over 3 years) that were made in 2012-2014 (3TB drives)? Reason why Seagate drives went from 3 year to 1 year warranty. I found the reason why I've lost 4 drives of a 24 drive array in less than 6 months. Thank unraid for dual parity support otherwise I would have really been p***ed off! Drive statistics were pulled off of the Backblaze servers study. https://en.wikipedia.org/wiki/ST3000DM001 https://www.hbsslaw.com/general-pages/seagate-hard-drives
-
Looks like I can confirm that I had two drives go bad mechanically in a month and a half! Thank goodness I'm double parity! Thanks for your help guys. I'm back up and running.
-
WTF!....ok, so I installed the new 5TB pre-cleared drive, and passively started watching the rebuild to see if the new drive or the old drive go to pluto...I then witnessed the "writes" column of drive 1 go from about the equal size of the new 5TB drive, to the pluto (18 x 10 to the 18th!) instantly! The controller is dumping the drive when this error occurs, so I would guess that it isn't an issue with a driver or unraid itself. The two drives are on different port of the controller card (and a different set of SFF-8087's). What's fishy is that the two drives are jumping to almost the same massive number + the number of actual writes it had when it went to pluto...This time, the areca isn't even reporting any read (or write) errors and just saying that the device failed (attached)! At this point, I can only guess is that 1. Two non identical drives went bad in the same way after several months of operating/parity checks. 2. Two unrelated but specific ports on the controller board went bad at the same time, 3. Two unrelated but specific cables went bad on two separate SFF-8087's. I can't really rule out a backplane issue, but I would have seen more issues from those slots for having it operating for multiple years 24x7 through an entire server gut/upgrade. I'm preclearing the second drive now, will try swapping in the second drive for disk 1 to see if anything is nailed down. Anybody have any thoughts? Anyone have any areca or supermicro backplane experience that would rival this really fluky problem? Why the gigantic number of writes reported to unraid? Why no errors in Areca the second time? I do see that the Areca has support for NCQ, and I remember a long while back (unraid 5ish) that there were problems using NCQ drives and non-NCQ drives with unraid attempting the use NCQ....could older drives be causing the controller to go funky? I can only guess this because disk 1 and disk 3 are two of my older drives. (even though I have a few 1TB drives without any issues) UPDATE: After pulling disk 1, and attempting to pull smart reports (from a different workstation), it is confirmed that the drive is dead (mechanical repetition and no drive detection). So now I'm leaning towards two drives went bad mechanically in one month and appeared with a really odd controller report to unraid (huge writes). I will probably wait for the second 5TB drive to preclear before rebuilding in the failed one's place (rebuild longer time than preclear + rebuild only once), but if I wanted to cut the risk of loosing even another in the preclear time, could I just keep one of the drives emulated while rebuilding on the previously inserted 5TB drive in waiting? I would essentially be rebuilding one of the two missing drives allowing me to at least recover from even one more additional failed drive during the second rebuild. If it is possible, would I just leave the bad drive assigned, and rebuild with the newly assigned 5TB? unraid-diagnostics-20170829-2256 (SECOND ISSUE).zip


















