




Enver
Members
-
Joined
-
Last visited
-
According to @Wody and his post-dated last year IT / IR is no longer an option with the 9400 and later series of cards. I have posted a question to him in his original post, hopefully he can shed some light.
-
Hello, I have just recently bought a Broadcom eHBA 9600 and am having a similar issue where the HDD's do not show in unRAID 7.1 but do appear in the Broadcom BIOS. I have posted my question here: https://forums.unraid.net/topic/192115-broadcom-9600-24i-hdd-not-showing-up-in-unraid-71-but-does-on-ehba-bios/ Can you please provide some support as to how you resolved your issue? Thanks, Enver
-
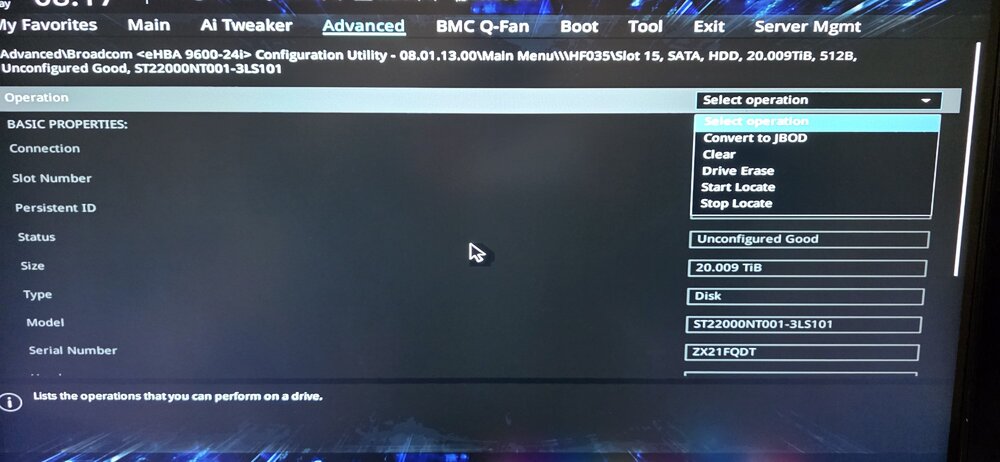
Thanks for the prompt reply.....this card is a mystery....there is no such 'feature'! You can see the available operations against a HDD below.
-
Hello, I have recently replaced my HBA controller with the Broadcom 9600-24i eHBA controller, you can read about the specifications here: eHBA 9600-24i Tri-Mode Storage Adapter | PCIe Gen 4.0 When I boot into the Asus WRX80 Sage II BIOS I can see the adapter and navigate to the onboard BIOS of the card. I have currently 16 drives attached to two of the three SFF-8654 8i ports populated with the following cables: SFF-8654 8i 74pin to 8 SATA. All of the drives are reporting back as available and healthy in the Broadcom BIOS, they are designated as 'Unconfigured Good'. I believe that changing the configuration from 'Unconfigured Good' to 'JBOD' would wipe any data on the drives; it suggests this in the Broadcom BIOS and warns you. When I boot into unRAID none of the drives attached the HBA appears. I am also sure that the new HBA card is not being passed through to the VFIO-PCI, which would be one of the reasons why the HDD's may not appear, see attached file. Interestingly unRAID seems to believe this is a Broadcom RAID controller, so perhaps this card needs to be flashed to IT Mode? I am unsure how to achieve this.....?? I have posted my diagnostic as well for review; I have noted an AER error but am assuming it may have something to do with the new card which could be safely suppressed.....although it seems to point to the root PCI hive. Can someone please advise how to resolve this issue. Thanks, Enver tower-diagnostics-20250719-1551.zip

-
https://forums.unraid.net/topic/111449-solved-vm-crash-vgaarb-changed-vga-decodes-olddecodesiomemdecodesnoneownsiomem/ Here is another example of the CoreFreq Plugin causing resets. Will post my diagnostics soon, I have rebooted the server several times since then BUT may have a historical log you can look at.
-
Do you run the CoreFreq plugin? If so set this to disable and autostart to disable.
-
Hello @turnipisum and @dcoulson Success! For me this has been resolved. The root cause for me was the CoreFreq plugin was set to enable and autostart. Once I disable autostart and set the plugin to disable I was able to boot the VM with the latest Nvidia driver and its been stable for the last few hours with round after round of 3DMark stress tests to prove it! Happy to share my BIOS and syslinux.cfg, along the way I enabled many HPC optimisations as recommended by AMD for the TRX/WRX platform. In my case the SVM:kvm entries are harmless and will most probably be rectified in a new Linux kernel. @ich777 This is just an FYI. No idea why the CoreFreq plugin would cause GPU resets; happy to share logs if this helps. Also do accept the plugin is experimental in nature.
-
My situation; the host is stable and I can restart the VM as many times as I like which is good for troubleshooting, however when I login to Windows 11 its stable anywhere from 30 seconds to 5 minutes until the screen goes black and then the Windows 11 machine reboots. So basically unusable. No load needs to be applied to the VM; it can be just idle at the desktop for it to crash. I am also now seeing the following in the unRAID logs: Mar 7 18:17:34 Tower kernel: SVM: kvm [64308]: vcpu0, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:35 Tower kernel: SVM: kvm [64308]: vcpu1, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:35 Tower kernel: SVM: kvm [64308]: vcpu2, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:35 Tower kernel: SVM: kvm [64308]: vcpu3, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:35 Tower kernel: SVM: kvm [64308]: vcpu4, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:35 Tower kernel: SVM: kvm [64308]: vcpu5, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:35 Tower kernel: SVM: kvm [64308]: vcpu6, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:36 Tower kernel: SVM: kvm [64308]: vcpu7, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:36 Tower kernel: SVM: kvm [64308]: vcpu8, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 Mar 7 18:17:36 Tower kernel: SVM: kvm [64308]: vcpu9, guest rIP: 0xfffff841bcc7bf99 unimplemented wrmsr: 0xc0010115 data 0x0 This seems to indicate some sort of Hyper-V / QEMU emulation error. I am sure this is related to the Windows 11 VM / Nvidia driver crashing but I haven't seen any guidance on how to fix this I do have "kvm-amd.avic=1" in my syslinux.cfg file which apparently is supposed to ignore this error? When you say trying an earlier Nvidia driver do you mean inside the Windows VM or on the host via Nvidia plugin? FYI my host is running Nvidia driver 530.30.02. I Windows 11 VM is running Nvidia driver 531.18. Things I am going to try tonight: Revert the Windows 11 VM Nvidia driver to an earlier version. Revert the unRAID host to an earlier version of the Nvidia driver. Try an Ubuntu VM tonight and pass through the same GPU just to see what happens. I did see some posts in Proxmox forums about disabling Above 4G Decoding which apparently fixed this for two users BUT that is a no go for me; the host won't even POST to BIOS screen i.e. initialise the GPU if Above 4G Decoding is turned off. -> CMOS CLEAR and RESET.
-
I am having the same problem. Asus WRX80 with two RTX4090's. The primary GPU is responsible for host duties, transcoding, analytics and some AI, including console video access. The second GPU in the 5th PCIE slot is passed through to the VM. What I am seeing is the following in the logs: Tower kernel: vfio-pci 0000:61:00.0: vfio_bar_restore: reset recovery - restoring BARs The VM loses video (black screen) and the entire VM crashes and then restarts Windows 11 and the process happens all over again. No issues with IMMOU groups; all devices are in their own groups and are passing through the VM. I have enabled IMMOU in the BIOS NOT in unRAID. i.e. PCIe ACS override is disabled. Having said that I have tried combinations of Downstream, Multifunction and Both and this doesn't seem to fix the issue. CSM disabled, and Enabled resizable BAR is enabled in the BIOS and Above 4G Decoding. Here is my syslinux.cfg: append amd_iommu=on amd_iommu=pt pci=noaer pci=acpi acpi_irq_balance apic apm=off rcu_nocbs=24-63 isolcpus=24-31,56-63 vga=extended pcie_acs_override=downstream,multifunction vfio_iommu_type1.allow_unsafe_interrupts=1 initrd=/bzroot This has got me stumped.
-
The ability to boot the Unraid Operating System off of PCIE / NVME or SATA / SSD drive instead of a USB key. As the title and short description suggests; I would very much like Lime Technologies to incorporate this as feature in an upcoming beta release. This post is a bit of a rant / whinge as an unhappy Unraid customer. RANT ON: The why: Because of the poor experience I have had over the last couple of years with the reliability, durability and frustrating user experience when a USB key has failed as a bootable device for Unraid. Because a USB key no matter what the brand or the warranty period is not an enterprise class solution for a bootable partition. Because in my experience whether you pay $5 or $50 for a USB key to replace the last one, the 5 year warranty period amounts to nothing when it costs you time, money and your server is down. The manufacturer of the USB key won't cover you for lost productivity and ultimately it will cost you more time and money to follow them up on their warranty. Most retailers and manufactures rely on consumers considering the USB key to be disposable and not pursue the arduous warranty / RMA process. Whilst I have the outmost respect for the Lime Technology support staff; my user experience has been less than optimal. To be told that the SLA for a failed USB key replacement within the arbitrary 12 month failure window is 3 days implies that you will need to wait up to 3 days before your server can be up and running again is unacceptable. <- I actually own two Unraid Pro Key licenses; only one of them is used; this was the only way could get my server up and running again in an acceptable amount of time. What is the point of backing up the key if you can't restore it to a new drive to use without having to contact support or request a new key? The 12 month arbitrary self-service replacement window - In a perfect world, we would buy the USB key with the 5 year warranty. The USB key would operate reliably for its 5 year warranty period and when it fails the Unraid user would utilise the self-service online replacement service. <- I have had no less than 4 USB keys fail; all with 5 year warranties (reputable brands, Sandisk, Lexar etc) in the time that Lime Technology has had the My Servers Plugin published to its consumers. All of them have failed requiring manual intervention by Lime Technology Support, I am currently waiting on another replacement. The second failure within two weeks. Its just not green or environmentally friendly. USB keys fail and when they do they aren't usually repurposed because of lack of trust or integrity in the failed storage device. They usually end up as e-waste and the plastics and materials are harder to recycle so normally end in land fill. The rationale: Its 2022 /2023, I find it incredulous we are still relying on this antiquated storage interface. USB keys are for the temporary storage of photos and documents! If you read any of the SanDisk or Lexar use cases; using a USB key as your primary boot partition isn't one of them! We spend so much time, money and effort building our version of the ideal Unraid server. Thousands of dollars are spent on repurposed enterprise server hardware, new enterprise class drives and then we leave uptime, reliability and durability of the entire server to a single device which is based on a memory storage interface standard that is slow, unreliable and was never meant for high durability (read / writes). Review the number of Unraid consumers who have posted a forum message where the root cause has been the USB storage media has failed. <- We have all been there numerous times. <- How many times has Lime Technology told you to plug your USB key into a USB 2.0 interface? I challenge you to find a modern server / workstation class motherboard that has a USB 2.0 port? I own an Asus WRX80E Sage WiFi motherboard. We have a high level of trust in modern NVME / SSD drives; we place some of our most important data on these devices; surely the Operating System for Unraid which includes configuration, passwords, encryption keys and certificates deserves the same level of durability!? NVME / SSD can be run in RAID 1 enough said. Most BIOS's support booting off NVME / SSD natively either in legacy or UEFI mode. NVME / SSD's support native hardware encryption that are TPM / BIOS aware. The current USB Creator tool can be hit and miss; some USB keys it recognises and allows you to format and create a bootable partition. Other keys simply cannot be seen by the USB Creator tool....despite the OS seeing the key....there doesn't appear to be any rationale as to why this may the case; another source of frustration and poor user experience. It should be a fairly straight forward process to repurpose / redeploy the USB Creator Tool onto a USB key....plug this key into your server and have the USB Creator Tools partition / image your internal NVME / SSD drive. NVME / SSD's don't suffer from the same FAT32 limitations; therefore partition limit sizing would not be a constraint. <- How many times have you had to reboot your server prematurely because the USB partition has filled up with logs whilst you attempt to diagnose the issue? How many times have you had Unraid tell you your logs are filling up......there is nothing actually wrong with your system....its just been running for a very long time? To summarise; @limetech PLEASE PLEASE PLEASE introduce the ability to boot off an enterprise class, internal storage medium such as PCIE/NVME or SATA/SSD drives. Hell even a consumer class NVME is more durable than USB key. I can't recall the last time an NVME drive failed because of lack of durability. In my opinion Lime Technology needs to update their support for bootable media; the last email I got from Lime Technologies support suggested I buy a Kingston DTSE9H USB key.....this key has not been manufactured by Kinston for years! NOT HAPPY! :RANT OFF
-
Bought two Kinston DataTraveller Exodia's just in case.....they both have unique GUIDs. I have now installed second Flash drive and have copied the Pro.key to it. The My Servers GUI suggests the key is not eligible for a replacement, even though I have never replaced the original Pro.key. I am thinking the backend is broken at the moment....
-
This has just happened to me as well. Running V6.10.0-RC2 for quite sometime and had to replace my failing flash drive. Followed the instructions using the USB Creator tool and copied the original Pro.key to the config folder of the new flash drive after I did the restore via the zip file backup. I was never given the option to replace the key, when i clicked on 'Fix Error' it allowed me to sign in intiallly but now its telling me the new key is blacklisted and I am unable to login to My Servers. I also cannot start unRAID and mount the drives.....this is extremely BETA! I have raised several support emails via several methods suggested to me by the My Servers GUI.....very frustrating!
-
Hey Guys, Telegraf has been logging the below over and over again whilst its running. This has been happening for the last week or so. I have tried downgrading Telegraf but that doesn't seem to fix the problem. I have deleted Telegraf and reinstalled it however the problem persists. Any advice you can provide would be greatly appreciated. Running: unRAID 6.9.2 InfluxDB:1.8.4-alpine Telegraf:latest 1.20.3 2021-11-03T10:06:58Z I! [agent] Hang on, flushing any cached metrics before shutdown 2021-11-03T10:06:58Z I! [agent] Stopping running outputs 2021-11-03T10:06:59Z I! Starting Telegraf 1.20.3 2021-11-03T10:06:59Z I! Using config file: /etc/telegraf/telegraf.conf 2021-11-03T10:06:59Z I! Loaded inputs: apcupsd cpu disk diskio docker kernel mem modbus net net_response netstat nginx processes sensors smart swap system temp 2021-11-03T10:06:59Z I! Loaded aggregators: 2021-11-03T10:06:59Z I! Loaded processors: 2021-11-03T10:06:59Z I! Loaded outputs: influxdb 2021-11-03T10:06:59Z I! Tags enabled: host=Tower 2021-11-03T10:06:59Z I! [agent] Config: Interval:10s, Quiet:false, Hostname:"Tower", Flush Interval:10s 2021-11-03T10:06:59Z W! [inputs.smart] nvme not found: verify that nvme is installed and it is in your PATH (or specified in config) to gather vendor specific attributes: provided path does not exist: [] 2021-11-03T10:06:59Z W! [inputs.docker] 'perdevice' setting is set to 'true' so 'blkio' and 'network' metrics will be collected. Please set it to 'false' and use 'perdevice_include' instead to control this behaviour as 'perdevice' will be deprecated 2021-11-03T10:06:59Z W! [inputs.docker] 'total' setting is set to 'false' so 'blkio' and 'network' metrics will not be collected. Please set it to 'true' and use 'total_include' instead to control this behaviour as 'total' will be deprecated 2021-11-03T10:07:00Z E! [inputs.docker] Error in plugin: Got permission denied while trying to connect to the Docker daemon socket at unix:///rootfs/var/run/docker.sock: Get "http://%2Frootfs%2Fvar%2Frun%2Fdocker.sock/v1.21/info": dial unix /rootfs/var/run/docker.sock: connect: permission denied 2021-11-03T10:07:00Z E! [inputs.docker] Error in plugin: Got permission denied while trying to connect to the Docker daemon socket at unix:///rootfs/var/run/docker.sock: Get "http://%2Frootfs%2Fvar%2Frun%2Fdocker.sock/v1.21/containers/json?filters=%7B%22status%22%3A%5B%22running%22%5D%7D&limit=0": dial unix /rootfs/var/run/docker.sock: connect: permission denied 2021-11-03T10:07:10Z E! [inputs.docker] Error in plugin: Got permission denied while trying to connect to the Docker daemon socket at unix:///rootfs/var/run/docker.sock: Get "http://%2Frootfs%2Fvar%2Frun%2Fdocker.sock/v1.21/info": dial unix /rootfs/var/run/docker.sock: connect: permission denied
-
https://www.linkedin.com/pulse/swtpm-unraid-zoltan-repasi/
-
Hello, Has anyone installed the ARECA driver for unRAID 8.6.3? You can download the latest driver here: http://www.areca.us/support/s_unRAID/driver/unRAID-6.8.3.zip ARECA does provide instructions but for me they don't make sense. They refer to zip files that don't exist and want you create a bootable USB for some reason? I would have thought booting into unRAID via USB as normal would be the way to go, to skip the USB bootable key creation part and skip to step 5 in the following instructions. The problem is the ARCMSR driver is in use when I attempt "rmmod arcmsr" via cmdline. Can someone please provide some guidance how to do this? I have an ARECA 1883ix-12 card the temperatures and SMART info has never worked for me, the card in in JBOD mode; my current theory is whatever driver version is in the vanilla version of unRAID 8.6.3 doesn't understand this card; hence my attempt to upgrade to the latest OEM driver. Update device driver for Raid controllers that were not supported by build-in driver ======================================================================================== 1. Extract unRAIDServer-6.8.x-x86_64.zip to an USB flash drive with volume label 'UNRAID'. 2. Extract arcmsr-1.50.0X.00-20200310-unRAID-6.8.x.zip to UNRAID USB flash drive /. 3. Right-click on the file °•make_bootable°¶ and select °•Run as administrator°¶. The °•syslinux°¶ utility will write the Master Boot Record and create a small hidden file named °•ldlinux.sys°¶ on the Flash device, making it bootable. 4. Boot from unRAID USB flash drive. 5. After boot up, login as root. type following commands to update device driver. # rmmod arcmsr # insmod /boot/arcmsr.ko.xz 6. To make new arcmsr.ko.xz driver take effect for next boot, type following command to rebuild bzmodules. # cp /boot/buildbzmod /root # chmod +x buildbzmod # ./buildbzmod # reboot




