




juanamingo
Members
-
Joined
-
Last visited
Everything posted by juanamingo
-
I deleted the docker image and it started up. Am re-creating my containers now. Thanks @JorgeB
-
Just upgraded from 7.1.2 -> 7.1.4 (stable), I'm unable to get docker to start. Attached are my diagnostics. I haven't tried downgrading or deleting the docker image and starting over, yet. Waiting on expert input.... guardian-diagnostics-20250716_0413.zip
-
Sounds good - thanks again! I'll keep that in mind next major upgrade I do to this system.
-
I updated all shares that had calculated space to 10gb and that worked! Thank you! Is there a better way to adapt to "low space" than manually updating all of the shares min free space?
-
I just deleted my docker.img and re-created it, then reinstalled all my apps. As far as I could tell, they were all working correctly - until I noticed that my Sabnzbd was showing I tried running docker safe perms again, deleting and reinstalling the container, deleting the perms.txt and reinstalling All the same issue.... Then I went to check other dockers and they all seem to be exhibiting similar behavior. From inside the Sabnzb container: This seems to be happening on several containers.... the /data and sub directories all seem to have the correct permissions: drwxrwxrwx 1 nobody users 91gb is the least amount of space on a single drive, 1tb the most, the cache drive has 1.8tb free. And the docker image isn't full... I'm missing something, but no idea what.... guardian-diagnostics-20250327-1123.zip

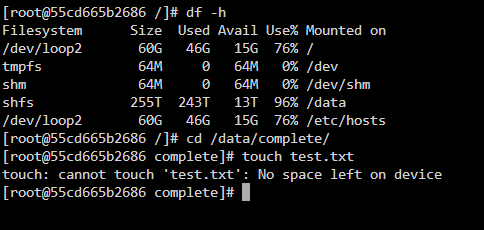

-
That did it - thanks @JorgeB
-
Thank you! I'll try that and report back as soon as I'm able to carve out the time.
-
Currently on 7.0.1 and for the first time I'm getting an error when updating or re-installing a container I removed /var/lib/docker/image/btrfs/layerdb/sha256/8d8bb5bda995f63b61e02380fda9305564793791aadc064a382f799308d6c513 and re-tried and getting the same error. /var/lib/docker/image/btrfs/layerdb/tmp is empty. I just rebooted a few minutes ago and tried again, with the same results. It's happening on updating and re-installing containers, but doesn't seem to happen on never-before installed containers. Any suggestions? guardian-diagnostics-20250312-1244.zip
-
Yes - but only of the important content, and that's already set up on another NAS.
-
I'm looking for the most cost-effective way to expand my storage capability. My current setup: SUPERMICRO CSE-846TQ-R900B 24bay hot-swap LSI 9305-24i HBA 2 x 20TB IronWolf PRO Dual Parity 14 x 10TB IronWolf PRO Storage 10 x 14TB IronWolf PRO Storage 2 x 2TB Samsung 850 EVO Cache I've run out of drive slots and am running low on space. The cheapest route would probably be to replace the 10TB drives with 20TB one at a time, but then I'll have fully functional 10TB drives that aren't being used, kind of a waste IMO. I'd like to keep them in service until they fail and then replace with a larger drive. The ideal setup would be a cheap JBOD case, good PSU and using another LSI-9305-24i with longer cables. Any suggestions on a case? I'd like to stay under $1500 total, with about $250 of that going to the 2nd LSI card
-
I ended up using the 2 SSDs to replace the failed m.2 cache drives and am rebuilding all my dockers. Using the command ^^ on another machine, I was able get 99% of the data off the drive. I'm going to try and warranty both m.2 drives (they're both showing failed and are both under warranty)
-
Will do ASAP. In the meantime I had pulled both drives and connected them to my arch linux machine and ran a btrfs check. one drive was fine, the other didn't complete the check. (don't have the errors handy). So far, I've had luck copying data off using btrfs restore -i -v /dev/sda1 ./temp --path /appdata So far it's pulled off > 137 GB and still going. only a few errors have come up about unable to retrieve a file. Mostly for containers I don't care about.
-
Howdy... I just had a docker instances fail to load its UI and then noticed no docker containers were loading, and got a message that a drive was missing from the cache pool. I rebooted the system and when it came back up, the docker service wasn't started and one of my NVME cache drives was missing from the pool. I shut down, pulled both drives and reseated them. Same thing, drive didn't show. I shut down again, swapped ports and both drives showed up - but BIOS gave a message that one of the drives failed SMART check and to replace it. I shut down again, swapped ports to the original position and both drives showed up (with the same BIOS SMART message). I got a message that the cache pool had returned to normal - but now it shows on the Pool Devices tab "Unmountable: Unsupported or no file system", and on the Array Operations tab "Unmountable disk present" and need to check the box to format the drives. I tried stopping the array and removing the "bad" (NVME1) drive, starting and stopping, then setting to 1 drive and starting, with the same results - need to format the drive to use it. It was a 2 drive btrfs pool. The SMART report says the drive was placed into read only mode. Any way to see the data on the "good" (NVME0) drive - my appdata folder is there... guardian-diagnostics-20240829-1331.zip
-
Gotcha - thank you sir! It looks like I'd have to compile a custom kernel to suppress that.
-
Well I finally got a chance to look into this. I have 4 nvme slots on my board and 2 nvme drives in a cache pool. I pulled both drives and installed heatsinks on them because every so often when the mover was running one of the drives would hit 50-60C and I didn't like that much. (I think it was the drive that was erroring, but i'm not sure) Originally the drive with the errors was in slot 0, and the 2nd drive in slot 1. When reinstalling the drives i put the drive with errors in slot 2, and the 2nd drive in slot 0, leaving slots 1 and 3 unoccupied. I'm still seeing the errors and they've followed the drive.... Some google research seems to indicate this is a harmless error - BUT in a week or so, log folder will fill up and I'll need to delete the syslog.1 or reboot. Any suggestions besides seeing if Samsung will replace the drive?
-
Thanks - I'll try that as soon as I can pull the server and lyk. I shouldn't be worried about a drive reporting only 315 hours on when it should have > 1500?
-
Good afternoon all! Fix Common Problems just notified me that my log folder was filling up - currently about 67% full. I took a look and saw that there are two 3 syslog entries - totaling about 256Mb, so i took a look in the newest syslog and I'm seeing this repeated: Jun 6 15:31:25 Guardian kernel: nvme 0000:02:00.0: AER: aer_layer=Physical Layer, aer_agent=Receiver ID Jun 6 15:31:25 Guardian kernel: nvme 0000:02:00.0: AER: aer_status: 0x00000001, aer_mask: 0x00000000 Jun 6 15:31:25 Guardian kernel: nvme 0000:02:00.0: [ 0] RxErr (First) Jun 6 15:31:25 Guardian kernel: nvme 0000:02:00.0: AER: aer_layer=Physical Layer, aer_agent=Receiver ID Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: Hardware error from APEI Generic Hardware Error Source: 514 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: It has been corrected by h/w and requires no further action Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: event severity: corrected Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: Error 0, type: corrected Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: section_type: PCIe error Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: port_type: 0, PCIe end point Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: version: 0.2 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: command: 0x0406, status: 0x0010 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: device_id: 0000:02:00.0 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: slot: 0 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: secondary_bus: 0x00 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: vendor_id: 0x144d, device_id: 0xa80a Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: class_code: 010802 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: bridge: secondary_status: 0x0000, control: 0x0000 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: Error 1, type: corrected Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: section_type: PCIe error Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: port_type: 0, PCIe end point Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: version: 0.2 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: command: 0x0406, status: 0x0010 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: device_id: 0000:02:00.0 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: slot: 0 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: secondary_bus: 0x00 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: vendor_id: 0x144d, device_id: 0xa80a Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: class_code: 010802 Jun 6 15:31:31 Guardian kernel: {127142}[Hardware Error]: bridge: secondary_status: 0x0000, control: 0x0000 device_id: 0000:02:00.0 is my Samsung 980Pro NVMe drive, which is the 2nd drive in my cache pool. I haven't noticed this error before and have been running this setup for about 3-4 months. The only thing that has changed is upgrading from 6.9 -> 6.10.1 -> 6.10.2 One thing that's weird is I looked at the attributes for the drive and see: "Power on hours 315 (13d, 3h)" - which is NOT right.... Its partner drive has "Power on hours 2,605", which is ~108 days or ~3 1/2 months - and sounds about right as they were installed at almost the same time (about a week apart) Any suggestions? guardian-diagnostics-20220606-1527.zip
-
Thanks! I haven't had a chance to get back to this, but if I'm able to try that, I'll let you know how it goes.
-
Interesting... one of the few things I haven't tried is pulling the Quadro... Maybe roll back the driver too... I'll give those a whirl and report back. Thanks!
-
Anyone have any ideas? Any other info or configs i need to provide? I've been trying every setting i could possibly think of and came across, but no luck so far. I did read that threadrippers were problematic for passthrough, but also read that it had been fixed in 6.8 or 6.9 (don't remember which).
-
I contacted Supermicro about this and they had nothing illuminating to add, other than they recommend populating the GPU at the 1st slot (closest to cpu) - which is counterintuitively named Slot 7.... So moved the GPU to that slot, bound them to vfi at boot again, rebooted, and updated the vm. I'm stuck in D3 now. here are the logs while stuck in d3 and after force stop. Edit: Now getting the `internal error: Unknown PCI header type '127' for device '0000:41:00.0'` on starting the vm. guardian-diagnostics-20220128-1638-after-force-stop.zip guardian-diagnostics-20220128-1635-_in-D3.zip
-
Well, I thought I had made some progress.... I tried stubbing the card in syslinux, but it didn't appear to work (still showed in the Nvidia Driver card list) I removed that entry and tried vfio-bind and rebooted. The card didn't show under the Nvidia list, and i passed it through without a bios to the vm. I ran my benchmark and it ran for a good 10 minutes, I thought I was good.... and then it crashed just like before. I'm not sure if it makes a difference so I dumped diagnostics before, and after force stopping the vm. My board _only_ supports UEFI boot, so I can't try legacy. It looks like one of my m.2 cache drives dropped when the card crashed.... maybe there's something wrong with the drives.... guardian-diagnostics-20220127-1848-crashed.zip guardian-diagnostics-20220127-1851-force-stop.zip
-
Thanks man - appreciate it!
-
I'm pretty sure you'd only notice if you were benchmarking, at least that's been my experience. Hope it helps! As far as your GPU passthrough - have you installed the nvidia drivers and run anything graphically intensive on it? Is it stable? I'm having issues as soon as i do anything gpu "intense" and was curious if you did anything special, or if it just worked. I posted my woes here
-
Just out of curiosity, why pass the drive through? Just to install direct to the drive? You could mount the drive separately (or add another cache pool with that drive) and then point the vdisk image at that drive, making it the size of the drive. That'd be cleaner IMHO - if you ever wanted to upgrade the m.2 down the road, you'd just have 1 file to move to the new drive.



