




zaraki1311
Members
-
Joined
-
Last visited
Everything posted by zaraki1311
-
I will run a few test when I get home. I am wondering if it tripped over no domain and is failing to do anything with the credentials. Possibly adding @workgroup to the end of the username might work
-
Have you tried removing the share in UD and re-adding it? I think I had to do that after the update.
-
Is your windows share password protected? Is it a share of a disk or of a folder?
-
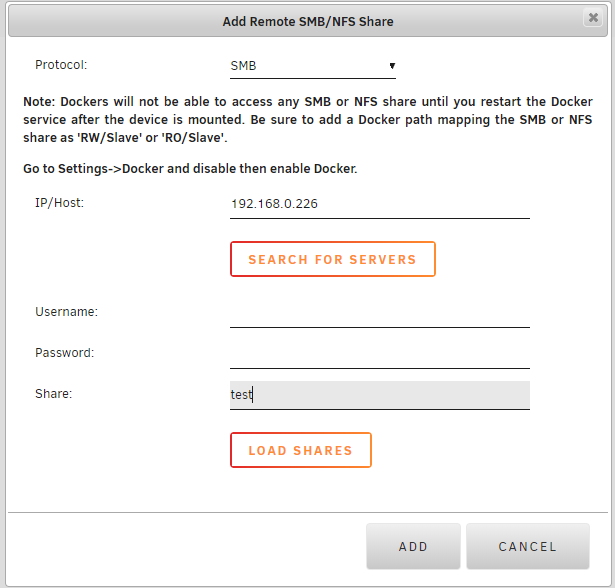
Looks like I was wrong. When it is a windows drive share I have not been able to get it to authenticate without a username our password, but if it is a folder share it works great. I have attached the files for the folder share. There is no point attaching the files for the drive share as even in my Windows machines it is asking for credentials samba_mount.cfg
-
I was entering just the ip address and the share in the share section. I tried the everyone and guest accounts with no password but that did not work as it complained about a missing password.
-
Looks like it works other than when it is a drive share using the Advanced Share. When it is an advanced share it complains it can't be found in fstab, below is the command it ran and the error. I have tried running a few test commands to get a working one but no luck yet, but that is mostly me being a linux noob. I will continue testing this weekend and let you know. If you need or want anymore testing for Windows let me know and I will do my best to help out. mount -t cifs -o '//192.168.0.226/f' '/mnt/disks/192.168.0.226_f' mount: /mnt/disks/192.168.0.226_f: can't find in /etc/fstab.
-
Sorry not sure if I understand what you would like me to test. Do you want me to try to connect to one of my shares that does not require any credentials? Or do you want me to test one of my secured shares without credentials?
-
Awesome. Thanks for doing that it seems to be working. Are there any tests you would like me to run?
-
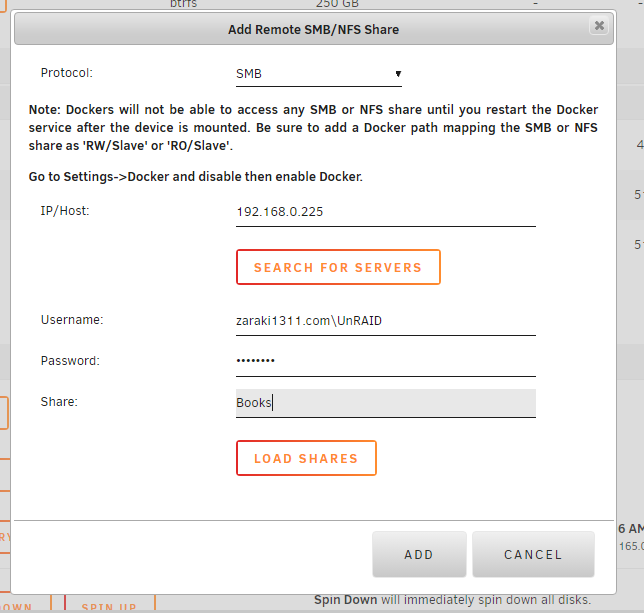
Here is an example. There are 2 ways to enter the domain that are standard. Domain/User or user@domain. A possible solution would be to add an optional domain field below the user.
-
So After a little playing I have sort of got this to work. If I copy the mount command and give it the domain parameter and run it in the terminal it works fine and shows in UD like it was setup with UD, but if I reboot I have to remount manually. Below is an example of what I ran. Is there a chance that support for domain users will be added? mount -t cifs -o rw,nounix,iocharset=utf8,_netdev,file_mode=0777,dir_mode=0777,,vers=3.0,username=UnRAID,domain=zaraki1311.com,password=******* '//192.168.0.225/Books' '/mnt/disks/192.168.0.225_Books'
-
Hello, I have been using this plugin for a few months now without much issue, but today I made a few changes in my network that seem to have broken a few things. My current setup is my my unraid server is basically just to run VMs and dockers. My main storage is a QNAP server. I have been using Unassigned Devices to map my network shares to my dockers. The change I made today was to make my QNAP an domain controller. This change makes it so a domain account is required to access a share. I have configured all of that, but it appears that I can't connect to the shares with Unassigned Devices now. I am using SMB to connect and adding the domain to the front of the user. All my Windows machines seem to be working fine connecting. below is the log I get from unraid. Any help would be greatly appreciated. Mar 13 19:05:40 ArlongPark unassigned.devices: Mount SMB share '//192.168.0.225/Books' using SMB3 protocol. Mar 13 19:05:40 ArlongPark kernel: Status code returned 0xc000006d STATUS_LOGON_FAILURE Mar 13 19:05:40 ArlongPark kernel: CIFS VFS: Send error in SessSetup = -13 Mar 13 19:05:40 ArlongPark kernel: CIFS VFS: cifs_mount failed w/return code = -13 Mar 13 19:05:40 ArlongPark unassigned.devices: Mount SMB/NFS command: mount -t cifs -o rw,nounix,iocharset=utf8,_netdev,file_mode=0777,dir_mode=0777,,vers=3.0,username=zaraki1311.com\UnRAID,password=******* '//192.168.0.225/Books' '/mnt/disks/192.168.0.225_Books' Mar 13 19:05:40 ArlongPark unassigned.devices: Mount of '//192.168.0.225/Books' failed. Error message: mount error(13): Permission denied Refer to the mount.cifs(8) manual page (e.g. man mount.cifs)
-
Hey, So I am running into an odd issue. I have the docker setup and I have changed the WEBUI ports to 6010 and changed it in the config file and the lan network to 192.168.0.0/24. When I try to connect to the webui it fails, if I turn the vpn off and try it works fine. Any thoughts? 2018-12-30 19:54:15.085103 [info] VPN_ENABLED defined as 'yes' 2018-12-30 19:54:15.108729 [info] OpenVPN config file (ovpn extension) is located at /config/openvpn/US_Las_Vegas.ovpn dos2unix: converting file /config/openvpn/US_Las_Vegas.ovpn to Unix format... 2018-12-30 19:54:15.139019 [info] VPN remote line defined as 'us-lasvegas.privateinternetaccess.com 1198' 2018-12-30 19:54:15.159417 [info] VPN_REMOTE defined as 'us-lasvegas.privateinternetaccess.com' 2018-12-30 19:54:15.179087 [info] VPN_PORT defined as '1198' 2018-12-30 19:54:15.199322 [info] VPN_PROTOCOL defined as 'udp' 2018-12-30 19:54:15.218725 [info] VPN_DEVICE_TYPE defined as 'tun0' 2018-12-30 19:54:15.237422 [info] LAN_NETWORK defined as '192.168.0.0/24' 2018-12-30 19:54:15.257325 [info] NAME_SERVERS defined as '8.8.8.8,8.8.4.4' 2018-12-30 19:54:15.276949 [info] VPN_OPTIONS not defined (via -e VPN_OPTIONS) 2018-12-30 19:54:15.298100 [info] Adding 8.8.8.8 to resolv.conf 2018-12-30 19:54:15.316610 [info] Adding 8.8.4.4 to resolv.conf 2018-12-30 19:54:15.334796 [info] Starting OpenVPN... Sun Dec 30 19:54:15 2018 WARNING: file 'credentials.conf' is group or others accessible Sun Dec 30 19:54:15 2018 OpenVPN 2.4.4 x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Sep 5 2018 Sun Dec 30 19:54:15 2018 library versions: OpenSSL 1.1.0g 2 Nov 2017, LZO 2.08 Sun Dec 30 19:54:15 2018 TCP/UDP: Preserving recently used remote address: [AF_INET]199.127.56.115:1198 Sun Dec 30 19:54:15 2018 UDP link local: (not bound) Sun Dec 30 19:54:15 2018 UDP link remote: [AF_INET]199.127.56.115:1198 Sun Dec 30 19:54:15 2018 WARNING: this configuration may cache passwords in memory -- use the auth-nocache option to prevent this Sun Dec 30 19:54:18 2018 [d2c3cc3a096826d7413d1c3a2cf62c6f] Peer Connection Initiated with [AF_INET]199.127.56.115:1198 Sun Dec 30 19:54:19 2018 TUN/TAP device tun0 opened Sun Dec 30 19:54:19 2018 do_ifconfig, tt->did_ifconfig_ipv6_setup=0 Sun Dec 30 19:54:19 2018 /sbin/ip link set dev tun0 up mtu 1500 Sun Dec 30 19:54:19 2018 /sbin/ip addr add dev tun0 local 10.6.10.6 peer 10.6.10.5 Sun Dec 30 19:54:19 2018 Initialization Sequence Completed 2018-12-30 19:54:19.366890 [info] WebUI port defined as 6010 2018-12-30 19:54:19.387864 [info] Adding 192.168.0.0/24 as route via docker eth0 RTNETLINK answers: File exists 2018-12-30 19:54:19.407133 [info] ip route defined as follows... -------------------- 0.0.0.0/1 via 10.6.10.5 dev tun0 default via 192.168.0.1 dev eth0 10.6.10.1 via 10.6.10.5 dev tun0 10.6.10.5 dev tun0 proto kernel scope link src 10.6.10.6 128.0.0.0/1 via 10.6.10.5 dev tun0 192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.152 199.127.56.115 via 192.168.0.1 dev eth0 -------------------- iptable_mangle 16384 2 ip_tables 24576 5 iptable_filter,iptable_nat,iptable_mangle 2018-12-30 19:54:19.429013 [info] iptable_mangle support detected, adding fwmark for tables 2018-12-30 19:54:19.460735 [info] Docker network defined as 192.168.0.0/24 2018-12-30 19:54:19.500971 [info] Incoming connections port defined as 8999 2018-12-30 19:54:19.522651 [info] iptables defined as follows... -------------------- -P INPUT DROP -P FORWARD ACCEPT -P OUTPUT DROP -A INPUT -i tun0 -j ACCEPT -A INPUT -s 192.168.0.0/24 -d 192.168.0.0/24 -j ACCEPT -A INPUT -i eth0 -p udp -m udp --sport 1198 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --dport 6010 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 6010 -j ACCEPT -A INPUT -s 192.168.0.0/24 -i eth0 -p tcp -m tcp --dport 8999 -j ACCEPT -A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT -A INPUT -i lo -j ACCEPT -A OUTPUT -o tun0 -j ACCEPT -A OUTPUT -s 192.168.0.0/24 -d 192.168.0.0/24 -j ACCEPT -A OUTPUT -o eth0 -p udp -m udp --dport 1198 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 6010 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --sport 6010 -j ACCEPT -A OUTPUT -d 192.168.0.0/24 -o eth0 -p tcp -m tcp --sport 8999 -j ACCEPT -A OUTPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT -A OUTPUT -o lo -j ACCEPT -------------------- Adding 100 group groupadd: GID '100' already exists Adding 99 user useradd: UID 99 is not unique 2018-12-30 19:54:19.560569 [info] UMASK defined as '002' 2018-12-30 19:54:19.583026 [info] Starting qBittorrent daemon... Logging to /config/qBittorrent/data/logs/qbittorrent-daemon.log. 2018-12-30 19:54:20.609145 [info] qBittorrent PID: 209 2018-12-30 19:54:20.610596 [info] Started qBittorrent daemon successfully...
-
Hello, I am running into an issue where I can't seem to hit the daemon with a desktop client when the VPN is turned on. The daemon is set to run on 58846 and I have the following mappings enabled 58846/tcp 192.168.0.240:5884658846/udp 192.168.0.240:5884658946/tcp 192.168.0.240:5894658946/udp 192.168.0.240:589468112/tcp 192.168.0.240:81128118/tcp 192.168.0.240:8118 The web ui of the docker instance is able to hit the daemon no issue, when I try to connect with my desktop client it cannot find the daemon. If I turn the VPN off and try with my desktop client it connects no issues. any thoughts on how to get around this?

