




Baskedk
Members
-
Joined
-
Last visited
Everything posted by Baskedk
-
Thanks for taking the time to look at the issue for me I will re-create the docker-file tonight 👍 Are you referring to any specific memtest? I am not aware of any memtest inside unraid? BR Baskedk
-
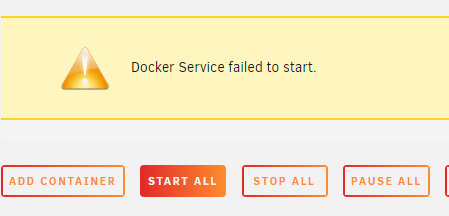
Hi everyone I have got a problem that I thought was a one-off a few days ago, where some of my containers was not responding anymore. I then went and looked at the docker section in unRAID where I was presented with "Docker service failed to start" I then rebooted the server and everything was fine again. But now, 3 days later, it happened again. I attached the diagnostics logs from unraid for any knowledgeable person to jump around in I would very much appreciate if anyone could help me find the root cause of this. Some containers are still running. I can access the server from Zerotier even after that message comes up. So docker is not completely dead. bytestacker-diagnostics-20231009-0803.zip
-
Hi community I have a kind of potentially massive issue..... I found out yesterday that one of my disks had been disabled due to errors, or something like that. I then (half an hour ago) replaced the disk with another one I had lying around. I made a clean shutdown, and replaced the disk while unpowered, booted up again, and assigned the disk (Disk 1) with the new disk and parity started building. I then after 10 minutes get a notification that the disks is experiencing massive error counts (See screenshot diskerrors.png) The disk 1 seems to be rebuilding, but what do I do with all these errors? Pasted the diagnostics as well. Hope someone out there will take a little time to help out I'm no expert, but that error count seems unhealthy..... jinx-diagnostics-20220401-1617.zip

-
That can't be done unfortunately. You can not run a hypervisor i site another hypervisor. So if you want to use Synology virtual manager you'll have to install xpenology directly on to the metal. And make sure that your hardware supports virtualization.
-
No need to have a certificate to run sftp on the DSM. And yes, you can change the port DSM uses for sftp inside the settings there. I can't see why not you could do the entire setup remotely. It should only be for adding disks to the setup as i see it. As for which bootloader version to use, it varies a bit for people what works. I believe I've used the setup @bmac6996 provided the details for on page 3 in this threat here. As for how to get going, there is a well documented tutorial from the XPEnology forums here: https://xpenology.com/forum/topic/7973-tutorial-installmigrate-dsm-52-to-61x-juns-loader/ And here is the serial generator for it as well: https://xpenogen.github.io/serial_generator/ Just make sure you don't use any of the Synology Quickconnect features with xpenology, since it is the one thing that directly communicates with synology's servers. If you need remote access to your instance, forward ports to it 😉
-
I've run XPEnology for 2+ years with passed through whole disks done i the same way you would pass a full disk to any other VM in unRAID without any issue what so ever. If you are in doubt about how to pass a full disk to a VM, see "spaceinvaderone's" exelent video on the topic. But when it is passed into the VM, you would just format it in the synology DSM software like if it was a standalone box. Hope this helps you going 😉
-
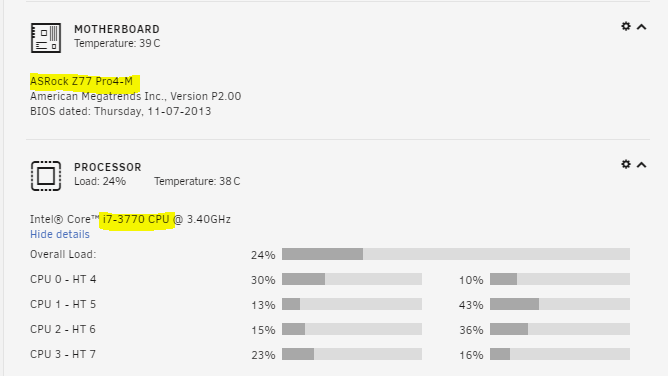
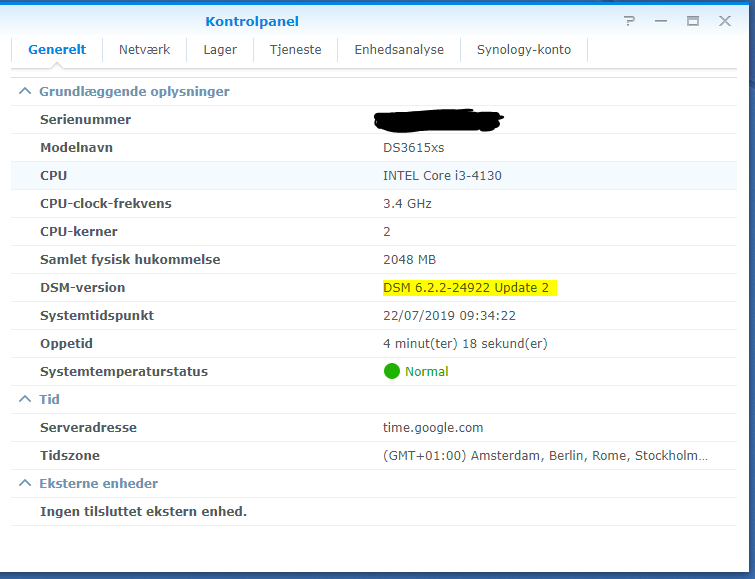
Just did the same as above on a i7-3770 on a ASRock Z77 Pro4-M today, and following the same procedure I got the same result. Works flawlessly. Thx again for the pointer. I don't know why it says it's an i3-4130, but it works, and that's what matters
-
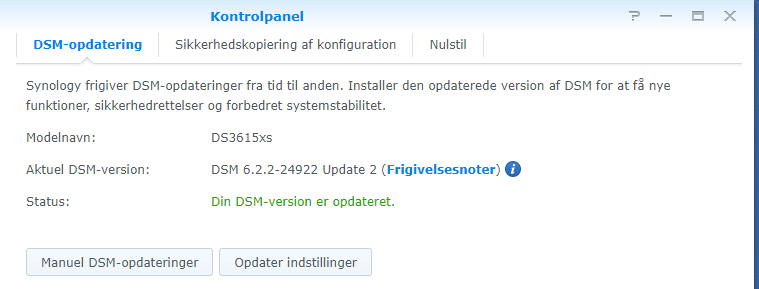
Did the above and can confirm that it works. For me at least. I too am rocking af supermicro. My board is a X9DAL though with dual E5-2418L Xeons I've been trying before without luck. Not with the newest version though. But it is the first time i've tried to set the NIC as "e1000e" and not just "e1000". If that made the differance or not, I don't know. But if works now for sure. Thanks for the pointer
-
I did create the disk 1st. And i have the system running now on loader 1.03b, I just could'n get it to discover the disk on the 1.04b loader. It booted and all. It just did'n discover the 2nd disk somehow. But as said, on the 1.03b it works fine. I guess it might come down to what hardware ppl are using i guess. unRAID is unraid, but XPEnology can be quite picky on hardware, and maybe that is what screws ppl over in this setup. What works for some, might not work for others. But when it comes to accessing unRAID resources from within DSM you can set up NFS/CIFS shares on unRAID and setup remote folder sharing in FileStation and add the shares there. And then you have a bridge between the two systems. It's not paticular fast transfer rates, but it works. It is a virtual environment after all.
-
Nope. I've replicated everything you have in your XML to the extend possible. Still no luck. Could you maybe upload your synoboot.img file for me to DL? without the MAC ofc. Btw, for the ds918+, where do you get a serial for that? I can only find a generator for ds3615xs, ds3617xs and ds916+. Not ds918+ Is it not needed for that one? Or how does that work? And why do you need to have 2 extra hdd's in your setup? Why not just the boot disk (synoboot.img) and a storage disk? Just curious
-
I assume you are reffering to ds918+ since I can't seem to find a 1.04b loader for 916+ but there is one for 918+. But i can't even get this one to show up on the network. What have you done for it to be discovered on the network? NIC interface e1000 ? What bios? Seabios or OMVF?, Machine: Q35-2.9? What is your settings?
-
Awesome. I'm gonna have to try that out. I'll post my frustration if it won't work 😉😂
-
Well, I got around this now. After even more trial and error since last time writing here, I skipped trying to get 1.04b loader to work even though i got that far. I found out that I could get it to recognize the virtual HDD if i used the 1.03b loader instead. But ONLY if i used the ds3617xs version. ds3615xs did not work for me at all. Could'n get it to be found on the network. DS3617xs could though. So after booting up on loader 1.03b with version ds3617xs and ofc renamed the NIC interface to 'e1000' in the XML editor. I got to the part where I should set it up. At 1st I tried to install automaticly from the synology site with the latest patch/firmware (DSM 6.2.1 version 23824). This ended up not booting anymore. So that obviously did'n work. Then I tried installing the previously version (version 6.2 23739) and that booted. As of now, I am stuck there when it comes to updates, but it's booting and working. and imo it's a pretty nice enhancement to unRAID to have DSM on top. I even only allocated 512mb ram to it and there is no problem what so ever. Hope you get it working btw, I found it not to get online if I booted it as VMWARE mode or what it is called. I got it working via the BAREMETAL option. I uploaded my synoboot.img to MEGA without my serial and mac address in it. if you want to try if it works for you. If you need to get a serial for it, use this link: Serial Generator for XPEnology If you need the .pat file i used, use this link: DS3617XS version 23739 DSM 6.2 If you want my Synoboot.img use this link: synoboot.img file 1.03b for DS3617xs
-
I've managed to get the "device" detected in the find.synology.com and it gets IP and so on. No problems there. But i can not get it to find a HDD in any way, shape or form! It's driving me nuts! I've used hours on this with different locations, sizes, formats and interfaces. It will not show up at all! <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/disk1/vdisks/XPEnology/vdisk2.img'/> <target dev='hdd' bus='sata'/> <address type='drive' controller='0' bus='0' target='0' unit='3'/> </disk> Does anyone have any pointers that i am missing out on? Is there something that have to be written to the Synoboot.img ? Any pointers is very appreciated !






