DoINeedATag
Members
-
Joined
-
Last visited
-
The script will only run for two hours. In the thread below some people reported really fragmented drives taking 48+ hours sometimes. If you use the user scripts plug-in to run daily it'll finish over time, or increase the run time in the script. Also if you have files larger then 8gb on the majority of the drive it won't be able to improve those files. Which is fine as the system is working as intended. Also you can see if it's your files or directories by doing frag -d or frag -f Overall if you run this once in a blue moon on most drives that should be exceedingly sufficient from what I've read and learned researching this topic. Again depends on your use case, a docker image folder or shared file system that gets added to and deleted from regularly probably will benefit from an occasional defrag. But remember you are adding wear and tare to the drive by defragging, use your best judgement when/if you should defrag. Hope that helps!
-
Alright from my testing I think I fixed this script to work with both 6.12.x drive mappings (/dev/md1p1 or /dev/mapper/md1p1). However I don't have an Unraid machine that has BOTH drive mappings at the same time. So I am not sure what will happen if you do (at least in theory its just two OR statements so it should handle both?) So use at your own risk and verify with blkid what kind of disk mappings you have. #!/bin/bash # ##################################### # Script: XFS Extended Defragmentation v0.3.1 # Description: Defragmentate only HDDs (SSDs will be ignored) if requirements met for a selectable running time. # Author: Marc Gutt, Computron, DoINeedATag # # Changelog: # 0.3.1 # - Fixed regex finding both /dev/mapper/mdxpy and /dev/mdxpy (DoINeedATag) # - Made it so the notification setting actually did something line 68 # - Only for Unraid version 6.12+ # 0.3 # - 6.12.6+ fix for regex finding drive paths (Updated by Computron & DoINeedATag) # 0.2 # - SSD recognition added # 0.1 # - first release # # ######### Settings ################## # defrag_seconds=7200 : Defrag only for a specific time in seconds (default is 7200 seconds = 2 hours) # defrag_only_sleep=1 : Defrag only when parity is not active (set to 0 to disable) # notification=1 : Notify yourself (set to 0 to disable) defrag_seconds=7200 defrag_only_sleep=1 notification=1 # ##################################### # # ######### Script #################### # make script race condition safe if [[ -d "/tmp/${0///}" ]] || ! mkdir "/tmp/${0///}"; then exit 1; fi; trap 'rmdir "/tmp/${0///}"' EXIT; # defrag only if parity is not spinning if [[ $defrag_only_sleep == "1" ]]; then # obtain parity disk's device id parity_id=$(mdcmd status | grep rdevName.0 | cut -d = -f 2) echo "Parity has device id $parity_id" # we defrag only if parity is not spinning parity_state=$(smartctl -n standby "/dev/$parity_id") if [[ $parity_state != *"STANDBY"* ]]; then echo "Defragmentation has been skipped because of active parity disk" exit fi fi echo "Search for HDDs..." # parse /etc/mtab and check rotational status declare -a mtab while IFS= read -r -d '' line; do disk_mapper_id_regex="^/dev/mapper/md([0-9]+)p([0-9]+)" disk_id_regex="^/dev/md([0-9]+)p([0-9]+)" if [[ "$line" =~ $disk_mapper_id_regex ]] || [[ "$line" =~ $disk_id_regex ]]; then disk_id=${BASH_REMATCH[1]} part_id=${BASH_REMATCH[2]} rotational=$(cat /sys/block/md${disk_id}p${part_id}/queue/rotational) if [[ "$rotational" == "1" ]]; then mtab+=("$line") echo "Found HDD with id md${disk_id}p${part_id} (added)" continue fi echo "Found SSD with id md${disk_id}p${part_id} (skipped)" fi done< <(cat /etc/mtab | grep -E '^/dev/mapper/md|^/dev/md' | tr '\n' '\0') if [ ${#mtab[@]} -eq 0 ]; then if [ $notification == "1" ]; then /usr/local/emhttp/webGui/scripts/notify -i alert -s "XFS Defragmentation failed!" -d "No HDD found!" fi echo "No HDD found exiting" exit fi printf "%s\n" "${mtab[@]}" > /tmp/.xfs_mtab echo "Content of /tmp/.xfs_mtab:" cat /tmp/.xfs_mtab # defrag xfs_fsr -v -m /tmp/.xfs_mtab -t "$defrag_seconds" -f /tmp/.xfs_fsrlast
-
In the terminal can you check in htop that you see xfs_fsr running? Use F4 to filter for xfs_fsr Can you run blkid and check if your xfs drives are using either /dev/md1p1 or /dev/mapper/md1p1 for the mapping? I have another machine on 6.12.8 (Node2) and it has it's xfs drives mounted differently then 6.12.6 (Node1) (not sure if its normal or not). root@Node1:~# blkid | grep xfs /dev/sdn1: UUID="" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="" /dev/mapper/md2p1: UUID="" BLOCK_SIZE="512" TYPE="xfs" /dev/mapper/md1p1: UUID="" BLOCK_SIZE="512" TYPE="xfs root@Node2:~# blkid | grep xfs /dev/sdb1: UUID="" BLOCK_SIZE="512" TYPE="xfs" /dev/md1p1: UUID="" BLOCK_SIZE="512" TYPE="xfs"

-
There is a nice script over at this post: https://forums.unraid.net/topic/98033-xfs-extended-defragmentation/ It uses the user scripts plugin to be able to schedule for what ever time frame fits your pools use case. I updated it to work with 6.12.6 ( I believe it will work on 6.12.8 also). Either way figured I would share it here since this is the first article I found talking about this topic from google. Updated script as of 3/28/24
-
Here is an updated version for Unraid Version 6.12.6. I used and modified both mgutt and Computron's code to get it working. Your mileage may very on other versions. I called it version v0.3 just to keep things straight if others find this code and get it confused with the one on the main page. #!/bin/bash # ##################################### # Script: XFS Extended Defragmentation v0.3 # Description: Defragmentate only HDDs (SSDs will be ignored) if requirements met for a selectable running time. # Author: Marc Gutt, Computron, DoINeedATag # # Changelog: # 0.3 # - 6.12.6+ fix for regex finding drive paths (Updated by Computron & DoINeedATag) # 0.2 # - SSD recognition added # 0.1 # - first release # # ######### Settings ################## # defrag_seconds=7200 : Defrag only for a specific time in seconds (default is 7200 seconds = 2 hours) # defrag_only_sleep=1 : Defrag only when parity is not active (set to 0 to disable) # notification=1 : Notify yourself (set to 0 to disable) defrag_seconds=7200 defrag_only_sleep=1 notification=1 # ##################################### # # ######### Script #################### # make script race condition safe if [[ -d "/tmp/${0///}" ]] || ! mkdir "/tmp/${0///}"; then exit 1; fi; trap 'rmdir "/tmp/${0///}"' EXIT; # defrag only if parity is not spinning if [[ $defrag_only_sleep == "1" ]]; then # obtain parity disk's device id parity_id=$(mdcmd status | grep rdevName.0 | cut -d = -f 2) echo "Parity has device id $parity_id" # we defrag only if parity is not spinning parity_state=$(smartctl -n standby "/dev/$parity_id") if [[ $parity_state != *"STANDBY"* ]]; then echo "Defragmentation has been skipped because of active parity disk" exit fi fi echo "Search for HDDs..." # parse /etc/mtab and check rotational status declare -a mtab while IFS= read -r -d '' line; do disk_id_regex="^/dev/mapper/md([0-9]+)p([0-9]+)" if [[ "$line" =~ $disk_id_regex ]]; then disk_id=${BASH_REMATCH[1]} part_id=${BASH_REMATCH[2]} rotational=$(cat /sys/block/md${disk_id}p${part_id}/queue/rotational) if [[ "$rotational" == "1" ]]; then mtab+=("$line") echo "Found HDD with id md${disk_id}p${part_id} (added)" continue fi echo "Found SSD with id md${disk_id}p${part_id} (skipped)" fi done < <(cat /etc/mtab | grep -E '^/dev/mapper/md' | tr '\n' '\0') if [ ${#mtab[@]} -eq 0 ]; then /usr/local/emhttp/webGui/scripts/notify -i alert -s "XFS Defragmentation failed!" -d "No HDD found!" exit fi printf "%s\n" "${mtab[@]}" > /tmp/.xfs_mtab echo "Content of /tmp/.xfs_mtab:" cat /tmp/.xfs_mtab # defrag xfs_fsr -v -m /tmp/.xfs_mtab -t "$defrag_seconds" -f /tmp/.xfs_fsrlast
-
Ah that makes sense! Seems like I spent a lot of time fretting about nothing! At least I learned something along the way though. Thank you for explaining that for me.
-
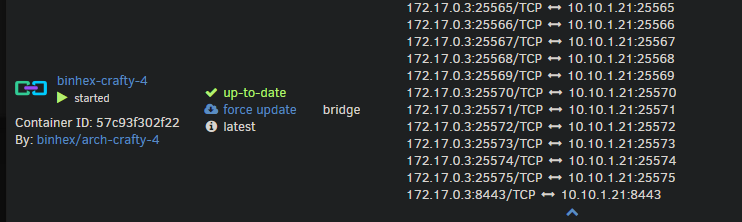
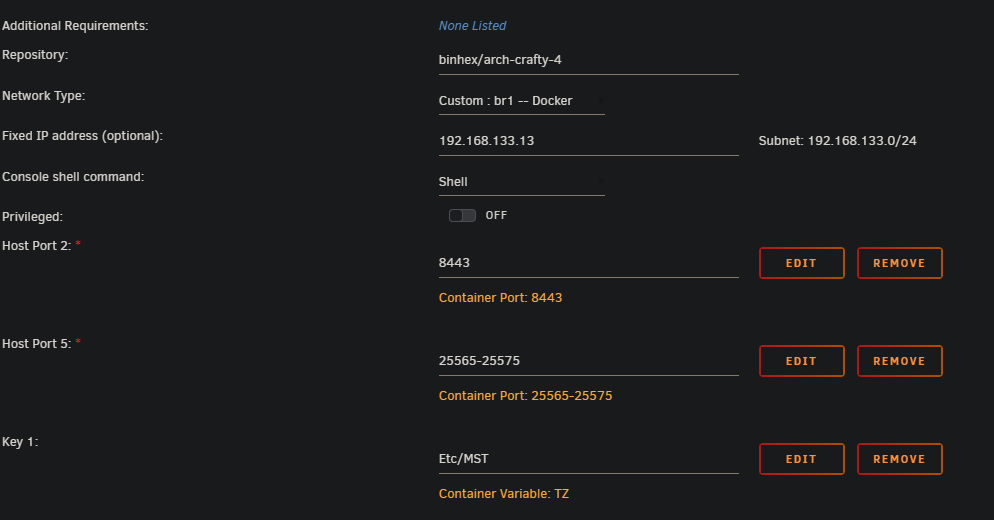
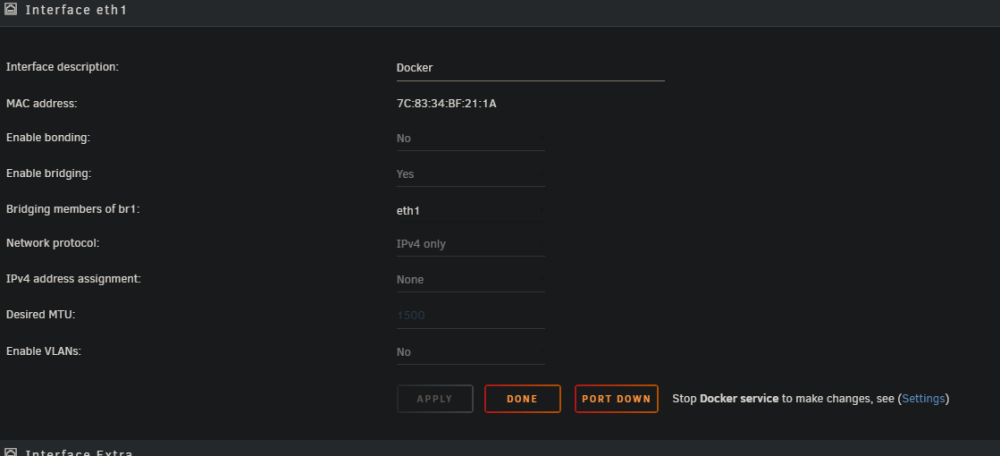
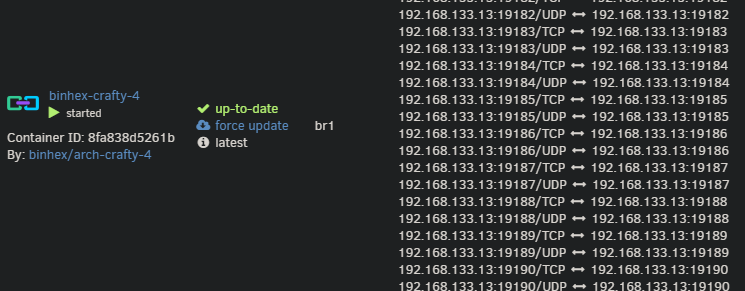
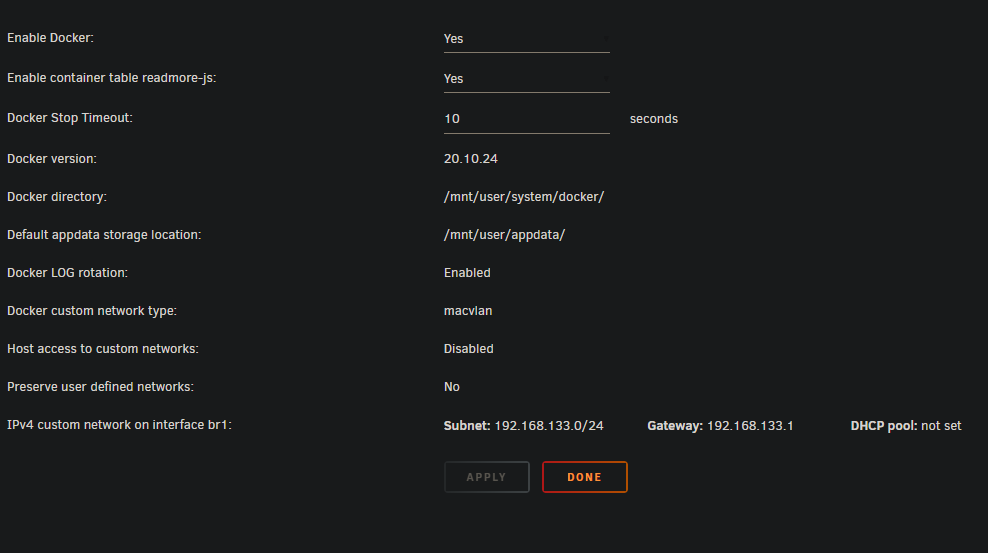
Hi all, I am struggling with docker not respecting the port settings of the template when using a custom network on eth1. I don't remember this being an issue in the past (I haven't played with unraid for game servers for years now. So maybe it's new? I'm not sure) I am using Unraid Version: 6.12.6 Attached are some photos of my settings. In this example Binhex Crafty 4 has an insane amount of ports open for bedrock edition. I don't play bedrock and removed the settings for these ports in the config. When I am in bridge mode it uses the config and creates a smaller list of open ports. When I used br1 it does not listen to my settings and uses all the ports. I would like it to use my custom network as that is the one I only have public facing game servers port forwarded through my firewall. I also tried just changing port number but it doesn't change anything when using the custom network. I have been googling around for a couple days now and have come up short. I am not even sure what to "name" this problem. I tried using Portainer to see if a "more advance" docker management system would fix this and I didn't have any luck. Edit/clarficiation: I removed these ports from the template: 8000:8000, 19132-19232:19132-19232/tcp, 19132-19232:19132-19232/udp (but in the screenshot you can see with br1 it uses all 201 of these ports) If anyone has any advice or guides I can follow that would be great!