

Aceriz
-
Posts
206 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Aceriz
-
-
6 minutes ago, bclinton said:
I followed the instructions that were outlined in the youtube video - How to Setup and Configure a Reverse Proxy on unRAID with LetsEncrypt & NGINX
you could also try using the SWAG .sample config file... but would need to ensure that you either remove the reverse proxy for /admin... as described in the pinned message on the top of this forum .. additionally you may want to consider once your done with the reverse proxy setting up fail2ban which is what I have been working on and just got sorted out. . (instructions on first page (bottom) of this help thread).
-
4 minutes ago, bclinton said:
I followed the instructions that were outlined in the youtube video - How to Setup and Configure a Reverse Proxy on unRAID with LetsEncrypt & NGINX
Within the Bitwarden Docker template did you enable websocket ? by default it is now set to disabled... with the SWAG nginx .config file need to enable this...
-
Another question.... I am wondering how I would go about creating a Docker Log rotation for the bitwarden.log used in the fail2ban setup
I have found this attached at the pieter hollander site but am not sure where I would use such a thing within unraid.... or if it is even needed.
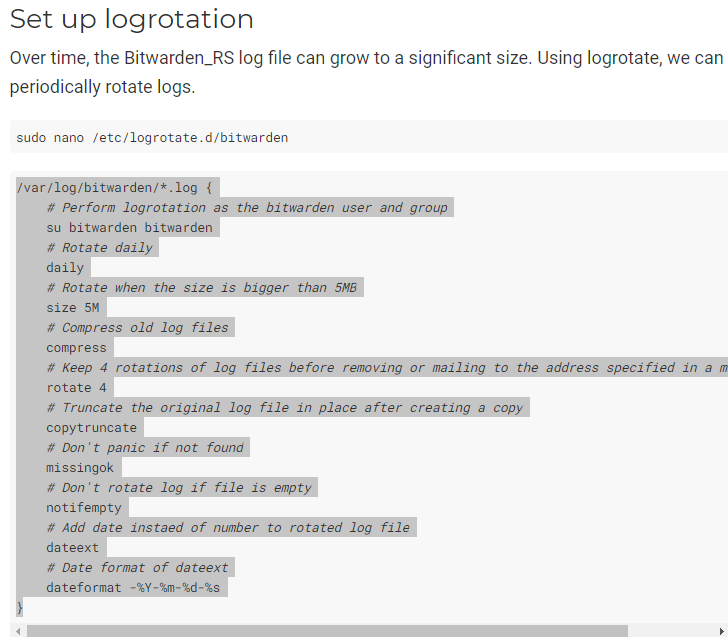
-
5 hours ago, Roxedus said:
regex to catch failed attempts
I was actually able to get it to work
") with much digging. .. I found the following https://pieterhollander.nl/post/bitwarden/ with some editing got the following to work
with much digging. .. I found the following https://pieterhollander.nl/post/bitwarden/ with some editing got the following to work
to the jail.local
[bitwarden-admin]
enabled = true
port = http,https
filter = bitwarden-admin
action = iptables-allports[name=bitwarden]
logpath = /log/bitwarden.log
maxretry = 2
bantime = 14400
findtime = 14400in the Filter.d folder added bitwarden-admin.conf
[INCLUDES]
before = common.conf[Definition]
failregex = ^.*Invalid admin token\. IP: <ADDR>.*$
ignoreregex =anything you might suggest to make it better.. I did test it... and it is working
-
1 hour ago, bclinton said:
believe it is right
I am talking actually about this section of the docker config page .

-
2 minutes ago, bclinton said:
Greetings folks! New unraid user and recently dropped lastpass and am trying to use bitwarden and swag in a docker container. I am able to run the chrome extension for bitwarden on the PC if I log in to the bitwarden server ahead of time with the browser. Otherwise I received the unable to fetch error. I assume once I get the extension working it will not need attention again. My current problem is getting the app on my phones (android) to connect. I am able to access my server through the browser on the phone but the app continues to refuse the connection. (Exception message:Hostname bitwarden.xxxx.duckdns.org not verfied) I followed Spaceinvaders youtube pretty much. Looking for a suggestion to help tackle the phone
Did you remember to add your subdomain to the SWAG unraid containter config in docker? I often forget this step and get your error
-
58 minutes ago, Roxedus said:
the admin panel needs another regex to catch failed attempts
do you think you could explain how to go about that? .... still very new...
I am assuming that it will be the addition of soemthing within the bitwarden2.conf file within filter.d
currently trying to add something like this line 3 as the error in the bitwarden log is "[2021-02-17 15:00:43.181][bitwarden_rs::api::admin][ERROR] Invalid admin token. IP: xxx.xxx.xxx.xxx"
# Fail2Ban filter for Bitwarden
# Detecting failed login attempts
# Logged in bwdata/logs/identity/Identity/log.txt[INCLUDES]
before = common.conf[Definition]
failregex = ^.*Username or password is incorrect\. Try again\. IP: <ADDR>\. Username:.*$
^\s*\[WRN\]\s+Failed login attempt(?:, 2FA invalid)?\. <HOST>$
^.*invalid admin token\. IP: <ADDR>\.
ignoreregex = -
2 minutes ago, Roxedus said:
Oh wow... So I thought that the fact that I could create account meant it wasn't working... I actually just did a test creation with the box unticked.... and got the error!!!
On another note... for protecting the /admin page.... thought I would comment that i used the default SWAG config file with appropriate edits.. which does have the /admin exposed via reverse proxy. but then I added and configured the fail2ban as per the last post on the 1st page of this forum.. which then appears to protect me from brute force attacks..
-
3 minutes ago, Roxedus said:
And singup is disallowed in the admin panel?
I have tried having the box ticked and not ticked.... saved inbetween with reset of docker each time without any difference...

-
Hi all... So I have read through all 11 pages here. By the way thanks @Roxedus..
My problem I am having is that within the Bitwarden log I am getting the following error... . Within the unraid docker container editor I do have the Signups_allowed set to FALSE... I have tried to under the general setting select "Default:false" for allow new signups saving.. but still get error...
My problem is that when I am on the reverse proxy page for bitwarden... I am still given the option to signup.. which I don't want.
[WARNING] The following environment variables are being overriden by the config file,
[WARNING] please use the admin panel to make changes to them:
[WARNING] SIGNUPS_ALLOWED, INVITATIONS_ALLOWED, ADMIN_TOKEN -
1 minute ago, ChadwickTheCrab said:
I just migrated to this today from LastPass and it works great so far. What's a good practice for backing up my password database. It's just me, a single user. I like the idea of being able to keep a USB stick with the exported encrypted json. If my Unraid server craps the bed, can I spin up a new Bitwarden container and be fine as long as I have my master password and the encrypted json? The encryption key stuff on the bitwarden support page confused me.
Following
Also just switching over from lastpass
-
On 3/18/2017 at 2:04 PM, local.bin said:
I moved the nextcloud.log to my nextcloud data directly, rather than mounting my data directly from letsencypt and note that the config.php edits are also needed to get nextcloud to output the log to the appropriate place
So I have been trying to get this setup... but seem to be hitting a bit of a barrier. when you say edit of the config.php to have the nextcloud to output the log to appropriate place... what edit are you putting in...
I am trying to read through the forum to find this but no luck... any help is great..
I followed dmacias's setup above..... to try and get things working... after much trial and error found out that with my binhex emby the log path was embyserver-*.txt not just server-*.txt......
but as I noted I am stuck now with the nextcloud.log... ..
On 3/18/2017 at 12:12 PM, dmacias said:Here's my setup. So for the LE docker I added
-
On 2/11/2020 at 7:14 PM, kilobit said:
Ok, here is everything you need to do to get this working.
First edit bitwarden container then click on "advanced"
Extra Parameters:
-e LOG_FILE=/log/bitwarden.log -e LOG_LEVEL=warn -e EXTENDED_LOGGING=trueThen add path:
container path: /log
host path: /mnt/user/syslog (unraid share you want bitwarden to log to)
access mode: read/write#apply/done
Next edit letsencrypt container
then add path:
container path: /log
host path: /mnt/user/syslog (unraid share you want bitwarden to log to)
access mode: read/write
#apply/doneNow edit ../appdata/letsencrypt/fail2ban/jail.local
* at the BOTTOM of the file add:[bitwarden] enabled = true port = http,https filter = bitwarden action = iptables-allports[name=bitwarden] logpath = /log/bitwarden.log maxretry = 3 bantime = 14400 findtime = 14400#save/close
Then create and edit ../appdata/letsencrypt/fail2ban/filter.d/bitwarden.conf and add:[INCLUDES] before = common.conf [Definition] failregex = ^.*Username or password is incorrect\. Try again\. IP: <ADDR>\. Username:.*$ ignoreregex =
#save and close
#restart letsencrypt container
***Testing
Use your phone or something outside your lan and once you fail 3 logins you will be banned.To show banned ips and unban enter the letsencrypt console from the docker window.
Lists banned ips: iptables -n -L --line-numbersUnbans ip: fail2ban-client set bitwarden unbanip 107.224.235.134
exit-End
The Only issue I have had with this setup is that on SWAG restarting the .conf file reverts to normal... I was able to solve with creating a new .conf file that is listed as bitwarden2.conf.. .. changing respective above. .. I did try creating .local file as per swag but could not figure out where to put it...
now to get emby and nextcloud setup with fail2ban... any suggestions?
-
12 hours ago, civic95man said:
If you want to pursue this route then it can't hurt anything.
So the weird thing, even though this makes absolutely no sense to me at all... But I think it might be the software thing with the ICUE and the passthrough.
So since I posted on Saturday I have uninstalled the ICUE and removed the device from the VM selection setup screen. (Only change made from before when there was an error after installing software and running PLEX).
Now in this post uninstall state I have been running the VM with a PRIME 95 blended load test in the VM now for almost the last 48 hours, with PLEX running on the server as well.. Without any errors what-so-ever ......
again this makes no sense as you had said... So I am going to do a test over this coming weekend where the only change I will make is re-adding the software and VM selection for the USB and if I get the error again it would seem to isolate down to that...
-
On 1/18/2021 at 4:56 PM, civic95man said:
Their solution was to nuke the offending VM and start over
So this might possibly be the solution... Over the last 3-4 days I started with a fresh install of windowsVM and for like the 3 days ran the VM with PLEX running without having any errors...
Then today I went to start adding my other software within the VM... (hadn't monitored the syslog during this process).. Went to do another test and got the tainted error..
I wondered if it might be one of the software applications. Specifically... I am wondering if it is the installed the iCUE corsair software that is for my H150i CPU pump.. (use for colour control/ control of fans/pump etc.... I do pass through the pump under the VM management and had it passed through in the last 3 days without the software...
Any thoughts on this ??
I am going to run the test again tonight having uninstalled the iCUE software and removing the pump from the VM management..
If this doesn't work I will follow through with the update to 6.9 rc :) -
3 hours ago, civic95man said:
At this point, I think the 6.9 route
In updating to 6.9 Would you recommend using the built in update tool ? Or should I try and do a "Fresh" install on 6.9...ie make a copy of the FLASH drive/ drive order main page print out(so i can reput this in on new launch/ key file for flash drive/ and share directories. That way I can just re-install fresh dockers, and fresh pluggins? Or do you think this won't make much of a difference...
thanks -
20 hours ago, civic95man said:
especially after a fresh reboot.
So I reset the system last night after setting up the Hugepages correctly I think(see above post)... But this time ran the system over night without the VM.
Overnight I didn't get any significant errors...
But on logging in this morning to the GUI got an order O error.. Not sure if this was due to me doing hugepages incorrectly or not... I am going to remove the hugepages and retest today,
I have attached the diagnostics from overnight and then mylogin to the gui this morning...
Thanks again for all help
-
11 hours ago, civic95man said:
Hugepages for your VM?
So I hadn't tried Hugepages before. I think I have set it up correctly. My system has 32GB of ECC memory so in the FLASH section behind the append I put in the following. "append hugepagesz=2M hugepages=12096 vfio-pci.ids=1b73:1100,10de:1ad8,10de:1e87,10de:10f8,10de:1ad9, initrd=/bzroot,/bzroot-gui nomodeset"
I chose the 12096 as I had tried putting it at the full 16128 but my system would not boot past the initial selection page for the gui safemode etc... froze on the countdown... so I reset and put the lower number in.I had the system boot up without the VM running. (Didn't give it that long but will test again over night)... ran the VM and within a few minutes got the error again I have attached the most recent Diagnostics Post hugepages change.
I will reset the server and overnight run the system without the VM started with Hugepages to see that that had no issues...(again the prior testing had isolated down to the VM but will retest). Then if anything I will look this weekend as I said at redoing the VM from scratch...
11 hours ago, civic95man said:format option of the SSD cache,
Just so I know is this something that will erase the data off of the SSD cache when If I look at updating as part of the problem solving ? Sorry if stupid question...
-
6 hours ago, civic95man said:
diagnostics AFTER t
Hey, So as I noted above Here is the new Diagnostics. So in this fresh reboot. I turned the VM on at 12:07. Did not notice error until about the 12 min later..
I am going to do another test tomorrow night. This time around I just turned on the VM and didn't do anything with it other than load the syslog page and a few other webpages and hit refresh for the 12 min.. but noticed I didn't get the error(as quickly as I had the other day). . . as it was a memory error I turned on a (plex in a browser) and got the error very quickly...
In my other testing last week though, I had run PLEX on this server, via another computer on my network and got no error for multi day run of constant video stream (got through 2multple continuous seasons of a show with no errors lol)...
I am going to tomorrow night run a test where I turn VM on but perhaps stress the memory and system with something other than PLEX to see what happens. Will post after.Thanks again for help.. and again will try and re-do the VM this weekend
-
4 hours ago, civic95man said:
So it seems to be VM related. Might be good to post diagnostics AFTER this happens again. That snippet of the syslog left out a lot of details and I saw reference to another OOM error.
Hey So please see the below attached which is the diagnostic I just pulled from the system. As I have had the system running for the last 2 days the syslog is full of the errors so you can't see things from the initiation of the system. As such I will also post a new diagnostic in like the next hour after a reboot that will show just the system starting up with plugins, and dockers without the error and then will timestamp in the post when I start the VM with a highly probable association to the error as I posted about yesterday.
4 hours ago, civic95man said:Their solution was to nuke the offending VM and start over. I guess you could try that. You could first try removing the xml but keeping the vdisk (assuming you're using vdisks for the VM). If that doesn't work then try creating a new vdisk, keeping the old one.
I will do this this weekend. I have no problems nuking the VM and re-doing things
one great thing about Unraid. I will post an update after I have done that. Any particular settings you recommend within the config .... I generally just follow spaceinvader's video for it..
4 hours ago, civic95man said:latest 6.9.0 release candidate.
If after I try the above. Is there a way to be setup so that I could try the latest release candidate. But if it doesn't work I can revert? Just not sure how to go about that if I cross that bridge
-
On 7/10/2020 at 1:13 AM, civic95man said:
Do these error only come up when the VM is active?
maybe a second cheap video card if you have room on the board
have you tried the 6.9 beta yet? I would only proceed down that route with caution as it isn't declared stable yet. Maybe 6.9beta1 so you aren't messing with pools yet.
Last resort you could use a phone or tablet if available to manage the VMs
Hey, So I know this is a delayed response. I wasn't able to in the summer update to a new bios that worked in my config due to the issues with the newer bios at the time not having the option to have the primary on-board GPU selected. After much talking with Asus and techinical service there they release a bios that does have the option I need. So I am now on the most up-to-date bios.
Over the last 4-5 days I have also had the time to really try and isolate down the problem. So I am able to run the system in Safe-Mode with docker and VM off without any of the errors. When I run in Safemode with VM on and Dockers off I get errors.
I then ran the system for about 48 hours in normal mode just dockers and pluggins and do not get errors. But within about 30 second of starting the VM get the following string of errors in the syslog... with the recurrent tainted errors. I have copied the below from the Syslog which was the first error that occurred following Instruction to turn on the VM within like I said 20-30 second... not sure if this line was significant :Jan 15 20:05:59 UNRAID kernel: type mismatch for 8c000000,4000000 old: write-back new: write-combining" or this one "Jan 15 20:07:36 UNRAID kernel: alloc_bts_buffer: BTS buffer allocation failure" as these occur right before the errrors
thanks all for thoughts and next steps of my troubleshooting
- Jan 15 20:05:20 UNRAID kernel: br0: port 2(vnet0) entered blocking state
- Jan 15 20:05:20 UNRAID kernel: br0: port 2(vnet0) entered disabled state
- Jan 15 20:05:20 UNRAID kernel: device vnet0 entered promiscuous mode
- Jan 15 20:05:20 UNRAID kernel: br0: port 2(vnet0) entered blocking state
- Jan 15 20:05:20 UNRAID kernel: br0: port 2(vnet0) entered forwarding state
- Jan 15 20:05:42 UNRAID kernel: vfio-pci 0000:65:00.0: enabling device (0100 -> 0103)
- Jan 15 20:05:42 UNRAID kernel: vfio_ecap_init: 0000:65:00.0 hiding ecap 0x1e@0x258
- Jan 15 20:05:42 UNRAID kernel: vfio_ecap_init: 0000:65:00.0 hiding ecap 0x19@0x900
- Jan 15 20:05:43 UNRAID acpid: input device has been disconnected, fd 11
- Jan 15 20:05:43 UNRAID acpid: input device has been disconnected, fd 12
- Jan 15 20:05:43 UNRAID acpid: input device has been disconnected, fd 13
- Jan 15 20:05:43 UNRAID acpid: input device has been disconnected, fd 14
- Jan 15 20:05:43 UNRAID acpid: input device has been disconnected, fd 15
- Jan 15 20:05:43 UNRAID acpid: input device has been disconnected, fd 16
- Jan 15 20:05:58 UNRAID kernel: no MTRR for 8c000000,4000000 found
- Jan 15 20:05:58 UNRAID acpid: client 12903[0:0] has disconnected
- Jan 15 20:05:58 UNRAID acpid: client connected from 7254[0:0]
- Jan 15 20:05:58 UNRAID acpid: 1 client rule loaded
- Jan 15 20:05:59 UNRAID kernel: type mismatch for 8c000000,4000000 old: write-back new: write-combining
- Jan 15 20:06:22 UNRAID kernel: usb 1-3: reset full-speed USB device number 2 using xhci_hcd
- Jan 15 20:06:22 UNRAID kernel: usb 1-7: reset full-speed USB device number 4 using xhci_hcd
- Jan 15 20:06:22 UNRAID kernel: usb 1-4: reset full-speed USB device number 3 using xhci_hcd
- Jan 15 20:07:36 UNRAID kernel: ------------[ cut here ]------------
- Jan 15 20:07:36 UNRAID kernel: alloc_bts_buffer: BTS buffer allocation failure
- Jan 15 20:07:36 UNRAID kernel: WARNING: CPU: 14 PID: 6191 at arch/x86/events/intel/ds.c:402 reserve_ds_buffers+0xe4/0x382
- Jan 15 20:07:36 UNRAID kernel: Modules linked in: xt_nat xt_CHECKSUM ipt_REJECT ip6table_mangle ip6table_nat nf_nat_ipv6 iptable_mangle ip6table_filter ip6_tables vhost_net tun vhost veth tap ipt_MASQUERADE iptable_filter iptable_nat nf_nat_ipv4 nf_nat ip_tables xfs dm_crypt dm_mod dax md_mod nct6775 hwmon_vid bonding igb(O) skx_edac x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel kvm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel pcbc wmi_bmof mxm_wmi intel_wmi_thunderbolt aesni_intel aes_x86_64 crypto_simd ipmi_ssif cryptd glue_helper intel_cstate mpt3sas pcc_cpufreq raid_class intel_uncore intel_rapl_perf i2c_i801 scsi_transport_sas ahci sr_mod i2c_core libahci wmi ipmi_si cdrom button [last unloaded: igb]
- Jan 15 20:07:36 UNRAID kernel: CPU: 14 PID: 6191 Comm: CPU 6/KVM Tainted: G O 4.19.107-Unraid #1
- Jan 15 20:07:36 UNRAID kernel: Hardware name: System manufacturer System Product Name/WS C422 PRO_SE, BIOS 3305 11/17/2020
- Jan 15 20:07:36 UNRAID kernel: RIP: 0010:reserve_ds_buffers+0xe4/0x382
- Jan 15 20:07:36 UNRAID kernel: Code: ff ff 48 85 c0 75 2c 80 3d e7 94 e9 00 00 75 1c 48 c7 c6 e0 22 c0 81 48 c7 c7 0c 10 d3 81 c6 05 d0 94 e9 00 01 e8 2b 42 04 00 <0f> 0b bb 01 00 00 00 eb 58 44 89 e7 49 89 85 40 09 00 00 48 89 04
- Jan 15 20:07:36 UNRAID kernel: RSP: 0018:ffffc90004477a70 EFLAGS: 00010282
- Jan 15 20:07:36 UNRAID kernel: RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000000000000007
- Jan 15 20:07:36 UNRAID kernel: RDX: 000000000000075a RSI: 0000000000000002 RDI: ffff88887f9964f0
- Jan 15 20:07:36 UNRAID kernel: RBP: 0000000000000000 R08: 0000000000000003 R09: 0000000000027000
- Jan 15 20:07:36 UNRAID kernel: R10: 0000000000000000 R11: 0000000000000050 R12: 0000000000000015
- Jan 15 20:07:36 UNRAID kernel: R13: ffff88887fb4f3e0 R14: fffffe00003a8000 R15: 0000000000000015
- Jan 15 20:07:36 UNRAID kernel: FS: 00001496b13ff700(0000) GS:ffff88887f980000(0000) knlGS:0000000000000000
- Jan 15 20:07:36 UNRAID kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
- Jan 15 20:07:36 UNRAID kernel: CR2: 00000209280ff038 CR3: 0000000113140002 CR4: 00000000003626e0
- Jan 15 20:07:36 UNRAID kernel: DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
- Jan 15 20:07:36 UNRAID kernel: DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
- Jan 15 20:07:36 UNRAID kernel: Call Trace:
- Jan 15 20:07:36 UNRAID kernel: ? kvm_dev_ioctl_get_cpuid+0x1d3/0x1d3 [kvm]
- Jan 15 20:07:36 UNRAID kernel: x86_reserve_hardware+0x134/0x14f
- Jan 15 20:07:36 UNRAID kernel: x86_pmu_event_init+0x3a/0x1d5
- Jan 15 20:07:36 UNRAID kernel: ? kvm_dev_ioctl_get_cpuid+0x1d3/0x1d3 [kvm]
- Jan 15 20:07:36 UNRAID kernel: perf_try_init_event+0x4f/0x7d
- Jan 15 20:07:36 UNRAID kernel: perf_event_alloc+0x46e/0x821
- Jan 15 20:07:36 UNRAID kernel: perf_event_create_kernel_counter+0x1a/0xff
- Jan 15 20:07:36 UNRAID kernel: pmc_reprogram_counter+0xd9/0x111 [kvm]
- Jan 15 20:07:36 UNRAID kernel: reprogram_fixed_counter+0xd8/0xfc [kvm]
- Jan 15 20:07:36 UNRAID kernel: ? vmx_vcpu_run+0x6b8/0xa97 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: ? vmx_vcpu_run+0x6ac/0xa97 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: intel_pmu_set_msr+0xf4/0x2e4 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: ? vmx_vcpu_run+0x6ac/0xa97 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: kvm_set_msr_common+0xc6e/0xd24 [kvm]
- Jan 15 20:07:36 UNRAID kernel: ? vmx_vcpu_run+0x6b8/0xa97 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: ? vmx_vcpu_run+0x6ac/0xa97 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: ? vmx_vcpu_run+0x6b8/0xa97 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: ? vmx_vcpu_run+0x6ac/0xa97 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: ? vmx_vcpu_run+0x6b8/0xa97 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: handle_wrmsr+0x4b/0x85 [kvm_intel]
- Jan 15 20:07:36 UNRAID kernel: kvm_arch_vcpu_ioctl_run+0x10d0/0x1367 [kvm]
- Jan 15 20:07:36 UNRAID kernel: kvm_vcpu_ioctl+0x17b/0x4b1 [kvm]
- Jan 15 20:07:36 UNRAID kernel: ? __seccomp_filter+0x39/0x1ed
- Jan 15 20:07:36 UNRAID kernel: vfs_ioctl+0x19/0x26
- Jan 15 20:07:36 UNRAID kernel: do_vfs_ioctl+0x533/0x55d
- Jan 15 20:07:36 UNRAID kernel: ksys_ioctl+0x37/0x56
- Jan 15 20:07:36 UNRAID kernel: do_syscall_64+0x57/0xf2
- Jan 15 20:07:36 UNRAID kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
- Jan 15 20:07:36 UNRAID kernel: RIP: 0033:0x1496b60454b7
- Jan 15 20:07:36 UNRAID kernel: Code: 00 00 90 48 8b 05 d9 29 0d 00 64 c7 00 26 00 00 00 48 c7 c0 ff ff ff ff c3 66 2e 0f 1f 84 00 00 00 00 00 b8 10 00 00 00 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 8b 0d a9 29 0d 00 f7 d8 64 89 01 48
- Jan 15 20:07:36 UNRAID kernel: RSP: 002b:00001496b13fe678 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
- Jan 15 20:07:36 UNRAID kernel: RAX: ffffffffffffffda RBX: 000000000000ae80 RCX: 00001496b60454b7
- Jan 15 20:07:36 UNRAID kernel: RDX: 0000000000000000 RSI: 000000000000ae80 RDI: 000000000000001d
- Jan 15 20:07:36 UNRAID kernel: RBP: 00001496b3fac000 R08: 0000564f326e7770 R09: 00000002d55a4cc0
- Jan 15 20:07:36 UNRAID kernel: R10: 0000000000000001 R11: 0000000000000246 R12: 0000000000000000
- Jan 15 20:07:36 UNRAID kernel: R13: 0000000000000006 R14: 00001496b13ff700 R15: 0000000000000000
- Jan 15 20:07:36 UNRAID kernel: ---[ end trace 84ab53b7f22d7e46 ]---
- Jan 15 20:07:36 UNRAID kernel: CPU 6/KVM: page allocation failure: order:4, mode:0x6080c0(GFP_KERNEL|__GFP_ZERO), nodemask=(null)
- Jan 15 20:07:36 UNRAID kernel: CPU 6/KVM cpuset=vcpu6 mems_allowed=0
-
On 12/5/2020 at 3:17 PM, SpaceInvaderOne said:
Yeah i have the same. I havent had time to look into this as yet but a quick fix is roll back to the earlier container.
In the template change repository to add :6.0 on the end so
onlyoffice/documentserver:6.0Thanks so much Spaceinvader. Life saver to say the least. I had thing a few months ago up and running with the old only office docker from only office but noted things not working(don't use much of document editing so probably had been down for a while.). But last night trying to find a new docker came across Siwats registry with your comment so downloaded it. Couldn't get it working until I found your comment.
On 12/7/2020 at 12:45 PM, Siwat2545 said:Interesting I’ll look into this when I’m free.
And thanks Siwat for looking into what happened. !!!
Also sorry for a stupid question, I had followed Spaceinvaders video for integration with Nextcloud and noticed that in the cert folder there is an extra file .csr . wondering if anyone can help me understand if this is needed? (I copied over the .crt and .key files from SWAG as per spaceinvaders video...
-
On 11/16/2020 at 4:13 PM, yogy said:
I've successfully setup ONLYOFFICE to work in my self hosted Nextcloud instance. Like many others here I use NginxProxyManager to setup reverse proxy and get a certificate from Let's Encrypt for my subdomains. As already mentioned here you don't need to create any config files and copying certificate and private key to a newly created folder certs in appdata ......
I think anyone who added at least one proxy host to NginxProxyManager with SSL certificate from Let's Encrypt pointing to the newly created subdomain will be able to configure OnlyOffice Document Server to work properly with Nextcloud. If not I will gladly provide some assistance.
My main intention here is creating a brief HOW TO in order to restrict the access to ONLYOFFICE Document Server (for security reasons and data integrity) with encrypted signature, known as Secret Key. Let me emphasize that I don't own the credit for this tutorial, I'm just posting something found among user comments in @SpaceInvaderOne YouTube video tutorial How to Install and Integrate Only Office with Nextcloud. Many, many thanks to @SpaceInvaderOne for providing great tutorials for us "nerds" and make our experience with unRAID easier.
HOW TO add and configure Secret Key in ONLYOFFICE:
Stop the OnlyOffice Document Server container.
In the "edit" option for the OnlyOffice Document Server docker, do "+ Add another Path, Port, Variable, Label or Device".
Config Type: Variable
Name: JWT_ENABLED (can be whatever you want to see in the UI, I used the key)
Key: JWT_ENABLED
Value: true
Description: Enables use of Secret key
[press ADD]Then add another variable:
Config Type: Variable
Name: JWT_SECRET (same thing, up to you)
Key: JWT_SECRET
Value: [WhateverSecretKeyYouWantToUse]. You can use the following command in Terminal (without quotes) to create a random Secret Key: "openssl rand -base64 48" and press Enter
Description: Defines the Secret key value
[press ADD][press APPLY]
Start OnlyOffice Document Server container.
Go to Nextcloud > Settings > ONLYOFFICE page. Enter the Secret Key and click Save (you should get the message: Settings have been successfully updated ..... No restart of the Nextcloud docker was needed.
Thank you so much for this !!
-
Hello all, I know this is likely a simple question But hoping someone can help me understand and setup something.
So I am trying to setup the extract app. --> https://github.com/PaulLereverend/NextcloudExtractJust wondering where I would run the following commands "sudo apt-get install unrar" and "sudo apt-get install p7zip p7zip-full" so that I can have the pre-requisits for the extraction app. Sorry if this is a simple question. Also wondering if this would be persistent between version updates. ?
Thanks in advance!!



[support] Vaultwarden (formerly Bitwarden_rs)
in Docker Containers
Posted
honestly Spaceinvaders are the best video that I have found... and use. Then alot of searching with the forums to find solutions...
this is your first time setting up SWAG right? have you checked the logs... to ensure that you are getting a server ready as per the spaceinvader video... do you have nginx connected with anything else for remote proxy?