




Rock G
Members
-
Joined
-
Last visited
Everything posted by Rock G
-
I understand and you are absolutely correct, always check compatibility between the 3 parts. The mobo and chipset supports the stock speed of my RAM however it's a bit outside of the official support of the CPU which I also noticed on the faq below. However, I've had this cpu+ram+mobo combo for roughly 3yrs+ running unraid with no major headaches or annoyances and I imagined if it was not compatible, it would've exhibited the same issues shortly after and not just now. Nevertheless, I will make note of this and if I'm unable to pinpoint the cause and it becomes unbearable, I will swap them out. Appreciate your feedback @JonathanM.
-
Thank you @JorgeB and yes my mistake, I meant I switched the docker from macvlan to ipvlan mainly because I initially noticed the hard locks whenever Plex is in use (which happens to be the docker always in use). I had the XMP profile enabled and set to 3200MT/s but I decided to disable it recently while trying to pinpoint the root of this issue. The stock speed is 3000MT/s. I'll monitor over the weekend to see how things go and then run memtest later if needed. Appreciate the suggestion.
-
Over the past few weeks I've been experiencing random hard freeze almost every couple of days. It doesn't seem to matter whether there's a high load/activity or if the system is idle (in terms of me accessing anything). Unfortunately it has gotten worse to a point that it happens practically everyday. I primarily use the server as a NAS and I only have a handful of dockers and VMs (which I haven't used for quite some time). Also, I only run dockers as needed and I don't leave them running constantly. My initial reaction was the docker ipvlan setting which I found on other threads, but changing it to macvlan didn't clear the issue. Next stop was the cache drive. I found some data corruption on my nvme cache drive which was set to btrfs so today I decided to rebuild cache drive and try XFS. I disabled docker, cleared/deleted partition/formatted to XFS which all went smoothly but before I can even rebuild any of my dockers, I ran into a couple more hard freeze. When this happens, the GUI becomes unresponsive and I have to manually shutdown. Ignoring the data corruption lines in the syslog, I noticed quite a few entries of rcu_sched self-detected stall on CPU which I'm not familiar with. Can someone pls review the attached logs, dumb it down for me pls and provide feedback? I only exported the sections before I had to shutdown but I can upload the entire syslog if needed. Thanks in advance and always very appreciative of the community. Edit: forgot extra details. XMP is disabled and also disabled C-states for kicks. CPU: Threadripper 2990WX Mobo: MSI MEG X399 Creation RAM: HyperX Predator 64GB (4x16) 3000MHz CL15 UnRaid v: 6.10.3 random1_06.22.2022.txt random2_06.24.2022.txt
-
Looking good on 6.9.0-rc2. Thanks for all your work and time!
-
Thanks for the feedback and tips @itimpi. Looks like you are correct, searching for "ata1" and "ata6" in the logs did point me to the parity drives. I'll swap out those cables and keep an eye on the syslog. Thanks again!
-
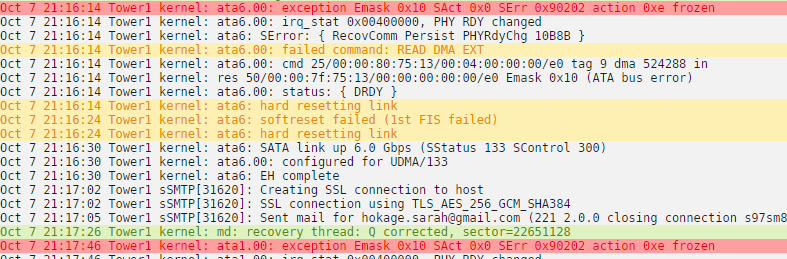
I randomly see this error in the logs "Tower1 kernel: ata1.00: exception Emask 0x10 SAct 0x0 SErr 0x90202 action 0xe frozen" and when I tried running the parity check earlier, it was crawling. I've read in past threads that this is usually due to a bad sata cable but need a little help figuring out which one to replace. I've attached the full diagnostics. Is it disk1 and disk6 or do I need to count the parity drives too? tower1-diagnostics-20191008-0422.zip
-
Thanks @Squid
-
I noticed something unusual in the last 2 builds. I keep getting notifications that there's an update but when I update, it shows 0 B pulled and it still shows update available. It doesn't matter whether I use docker, latest or public in VERSION, it still thinks there's an update avail. I also tried a couple of commands from a terminal but it looks like its running on the latest build. Other than this, everything is running fine. Does anyone have any suggestions?



