micokeman
Members
-
Joined
-
Last visited
Everything posted by micokeman
-
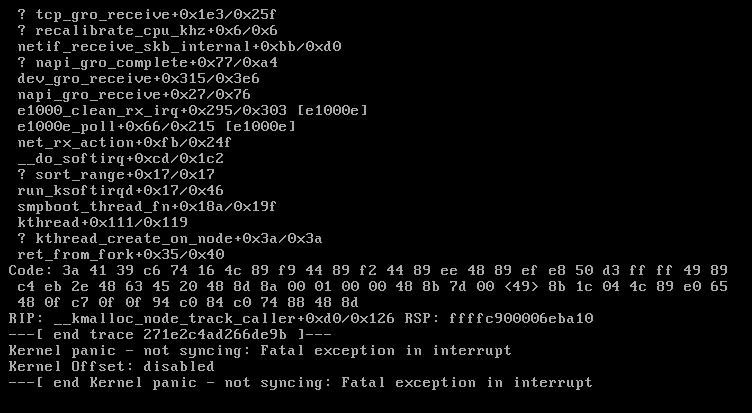
Hello, Not sure if anyone can help, but I just updated to the latest build. (I believe I was on the build 5.1.0). I was able to transfer 4TB from one drive to another on 3 days ago, but after the update, transferring no longer seems to be happening. I select one drive in the 'FROM' column and one drive in the 'TO' column and then select all the folders. I go to the next stage and the page loads with all the stats, but transferring does not seem to be happening. It has no 'end-time'. Last time I did this I immediately saw '28 hours' to go. Now when I try to go to the UnRAID main page or the UnBalance page ("https://10.10.10.201:6237" or "https://10.10.10.201") I get "The connection has timed out". This has happened twice already. This last time was after a server reboot.