




rtho782
Members
-
Joined
-
Last visited
-
I will test converting images to a zvol, I had been meaning to do that anyway. The pool does have compression on as well. I have 1TiB of RAM allocated to ARC so the ARC hit rate is very high and you would think it would get a bit faster after a while given that most of the reads will come from RAM.....
-
I run a number of Virtual Machines on my server, mostly Windows Server 2022 and 2025. General remote desktop performance of these VMs is poor. The stat menu has a significant amount of lag, for example. The main VM I use in this way is SR1VDI01, which has 24 passthrough vCPUs (the server has 2x28c Skylake-SP Xeon CPUs). The Cores are not pinned. 64GB RAM, the server has 1536GB. It is using Q35-9.2 and OVMF TPM. VHD is stored in .img format on NVMe storage, using ZFS over LUKS, via VirtIO. I have accessed this pool directly, without FUSE. I am not sure what I can do to improve this? tacgnol-core-diagnostics-20260527-1219.zip
-
Interesting, strange that it doesn't seem to want to actually use it all in practice. Thanks.
-
Attached, sorry :) tacgnol-core-diagnostics-20250920-1239.zip
-
I have a system with 1536GiB of RAM, but Unraid only seems to want to use around 1TiB. Obviously the "1536TiB" is incorrect, but the system happily supports this much RAM with these Skylake M-suffix CPUs. Unraid however reports 1TiB usable in various places, although others I see the full 1.5TiB. The above screenshot I just told the live memory tester plugin to test 800GB, and it evicted almost all of my ZFS cache to achieve that, keeping ~500GiB sat idle. Docker advanced view shows as though it has the full amount of memory: ARC cache is set as: options zfs zfs_arc_max=824633720832
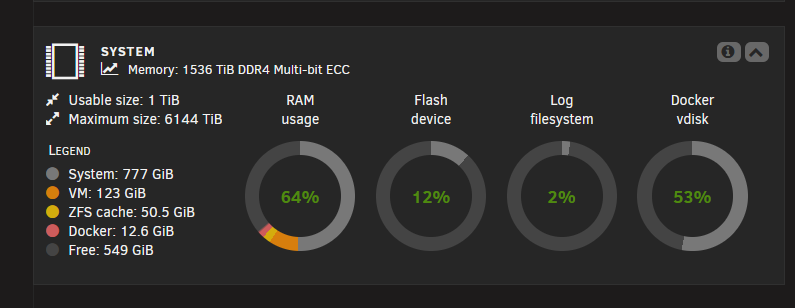
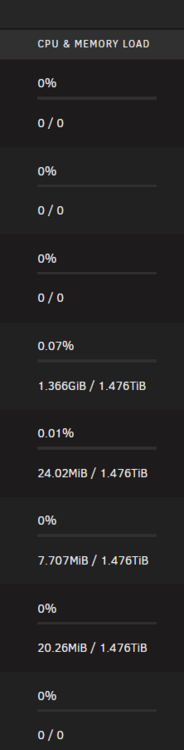
-
I have 1536GiB in my server. This is reflected incorrectly in the UI, which states "1536 TiB" (I wish) and 1TiB usable. I believe it is all usable, as containers can see it all: So likely just a display issue, or rounding etc. Version 7.1.4/
-
Unraid 7 adds the option to set mover between two pools, which is excellent. In my setup I have an SSD pool as cache, then a raidZ1 tier of 6x14tb drives, saving me spinning up the 27 array drives for normal writes. I've been migrating my array drives to zfs, so had some array drives excluded from mover in share settings. When I updated to 7, I set mover to move from Cache to the ZFS tier, and the option for excluded drives obviously vanished. I have an rsync script that moves the oldest files from the zfs tier to /mnt/user0 (the array, without cache). This is so that it correctly distributes the files across the array drives based on my settings. This mount point seems to obey (the now invisible) excluded disks settings. The workaround is to switch mover back to moving to the array, remove the exclusions, and then set it back to the pool as target. It feels like the drive exclusions should be in another section and always visible if they still retain some function when the array is not selected in the share?
-
It might be worth shutting down all your containers and VMs while you migrate all of the data off the cache, or more will be created while mover is running. You can stop mover with the command mover stop at the command line. You can then start it again.
-
Server hardware means ECC ram, which imo is well worth it. You can get some older servers pretty cheaply, and they have lots of PCIe and RAM slots, and potentially more cores. They are however louder, and more power hungry. You lose quicksync for plex transcoding (although you can add a GPU, I'm about to add an ARC A40 to mine). I'm running a DL380g10 with 2x28 cores and 1TB of ram, and am very happy with it.
-
In case anyone ever has a similar issue, I moved the disk to the IOM6 shelf and removed the interposer (so I can see the SMART data), which showed no issues. Pulling one drive from the ds4243 apparently made the fans ramp down quite a bit so I've left an empty slot in that. Rebooted server and it's gone through a rebuild on that drive without issue.
-
Add the new drive as an additional cache pool and use rsync or unbalanced to migrate stuff. I would suggest using zfs for cache myself as then you can make each app data a dataset and snapshot them.
-
The Iom12 won't detect sata disks at all, I had a Dell 6gbps controller in there before which was fine, and the other shelf (which still has the dell controller) is fine. I will move the disk to the 2nd shelf when I can pull it to get smart data from it, but unbalanced is currently running to clear off some pool drives for me to swap into the array. I assumed the lack of SATA support was just a limitation of the iom12 to be honest. Strange for it to be a power issue, as no other drive in that shelf had an issue and the shelf has 4 power supplies! I will look to swap the drive for a 14tb spare and put it in the other shelf amd run preclear on it a couple of times.
-
One of my array disks, disk17/sdz, seems to have dropped out of the array. 8 errors are shown in the error column. The array disks are all on an LSI 9300-16e card, and on one of two disk shelves. This one is on a ds4243 with an IOM12 controller, and because the IOM12 doesn't seem to like SATA disks, is using a SAS interposer which annoyingly prevents me seeing SMART data. Diagnostics attached, is anyone able to give me any sort of clue as to what has gone wrong? Not sure if I should swap the disk out or reboot and let it rebuild. tacgnol-core-diagnostics-20240616-0843.zip
-
Thanks..... Does that mean it might come in 6.13 or it likely will? If not, I need to look at virtualising unraid in proxmox I guess.
-
https://support.hpe.com/connect/s/product?language=en_US&kmpmoid=1010203200&tab=driversAndSoftware&driversAndSoftwareFilter=8000113 There are drivers for it here, but unlike RHEL/SUSE or whatever else, no idea how I can add drivers to unraid.

