




wishie
Members
-
Joined
-
Last visited
Everything posted by wishie
-
I will update this post with the solution when I get home this evening.
-
Ive managed to figure it out, and it is indeed special chars in filenames that was causing the issues. Freestyle\ -\ �gon\ som\ Glittrarn\ 98.mp3 Me\'Shell\ Ndeg�Ocello\ -\ * La\ Cream\ -\ Chate�u\ d\'Amour.mp3 and a few others.. but about 9 files in total caused the issue
-
I will have to get an external drive big enough and give that a go.. maybe this afternoon.
-
Yes, the 59 files over SMB, in that MP3s folder, are exactly the same. And yes, all 59 files seen on the SMB share are also visible on the NFS share of the same folder.
-
Disk Share for disk2 (MP3s folder) over SMB = 59 files Disk Share for disk2 (MP3s folder) over NFS = 6375 files User Share for Music (MP3s folder) over SMB = 59 files User Share for Music (MP3s folder) over NFS = 6375 files
-
No, the disk share shows the exact same files as the user share. There is also no symlink that I am aware of.
-
Disk Share of 'Disk 2' shows the same 59 files that the User Share shows.
-
I started to go through them, but 6000ish files are on 'Disk2'.. basically ~400GB of the 600GB of data. So its not like just those 59 files are on a different disk. Besides, NFS is working fine.. it has to be some issue with SAMBA. EDIT: The ENTIRE contents of the 'MP3s' folder, is on disk2.
-
Exiting from 'more' is a simple 'q'. Anyway, permissions for files and folders are perfectly fine. Here is an excerpt -rw-rw-rw- 1 nobody users 2.0M May 3 2008 Dead\ Kennedys\ -\ Winnebego\ Warior.mp3 -rw-rw-rw- 1 nobody users 5.4M May 3 2008 Death\ In\ Vegas\ -\ Dirt.mp3 -rw-rw-rw- 1 nobody users 3.4M May 3 2008 Debelah\ Morgan_-_Dance\ With\ Me.mp3 -rw-rw-rw- 1 nobody users 3.9M May 3 2008 Deborah\ Cox\ -\ Nobody's\ Suppose\ to\ Be\ Here\ (Dance\ Mix).mp3 -rw-rw-rw- 1 nobody users 4.0M May 3 2008 Deborah\ Cox\ -\ Nobodys\ Supposed\ To\ Be\ Here.mp3 drwxrwxrwx 1 nobody users 90 Jan 5 2016 Decades/ -rw-rw-rw- 1 nobody users 3.6M May 3 2008 Dee\ Lite\ -\ groove\ is\ in\ the\ heart.mp3 -rw-rw-rw- 1 nobody users 3.6M May 3 2008 Dee\ Lite,\ Groove\ Is\ In\ The\ Heart.mp3 -rw-rw-rw- 1 nobody users 5.5M May 3 2008 Deep\ Forest\ -\ Sweet\ Lullaby\ [\ Round\ The\ World\ Mix\ ].mp3
-
Just confirmed that my Windows 10 and Windows 11 laptops only see the 59 files that I see on macOS. So its definitely an issue on the unRAID side of things, and its not specific to macOS.
-
I'm pretty sure I have looked at it with Windows over the years. I will boot into Windows to confirm shortly, and also test with one of my Windows laptops.
-
Look at the file counts in the original post screenshot. SMB shows 59 files. NFS over 6000. NFS is correct.
-
As run on the unRAID machine itself: root@wishie:~# ls -lah /mnt/user/Music/ total 580K drwxrwxrwx 1 nobody users 6 Jan 9 06:57 ./ drwxrwxrwx 1 nobody users 48 Jan 9 06:48 ../ -rw-rw-rw- 1 nobody users 250 Nov 5 2011 .apdisk drwxrwxrwx 1 nobody users 36K Sep 16 2011 701\ Greatest\ 1980's\ Singles\ [FLAC]/ drwxrwxrwx 1 nobody users 68K Jan 9 06:35 Albums/ drwxrwxrwx 1 nobody users 356K Jan 9 06:35 MP3s/
-
As an example.. if I run ls -lah 2\ Unlimited\ -\ * on my Mac via Terminal, I get the following: wishie@Mac-Pro MP3s % ls -lah 2\ Unlimited\ -\ * -rwx------ 1 wishie staff 5.0M 3 May 2008 2 Unlimited - Get Ready For 1This.mp3 -rwx------ 1 wishie staff 4.2M 3 May 2008 2 Unlimited - Never Surrender.mp3 -rwx------ 1 wishie staff 3.8M 3 May 2008 2 Unlimited - The Edge of Heaven.mp3 -rwx------ 1 wishie staff 3.4M 3 May 2008 2 Unlimited - Tribal Dance (Rap Edit).mp3 but the same command, issued in terminal on the unRAID machine itself gives the following: root@wishie:/mnt/user/Music/MP3s# ls -lah 2\ Unlimited\ -\ * -rw-rw-rw- 1 nobody users 3.2M May 3 2008 2\ Unlimited\ -\ Get\ Ready\ 4\ This\ (Hockey\ Mix).mp3 -rw-rw-rw- 1 nobody users 5.1M May 3 2008 2\ Unlimited\ -\ Get\ Ready\ For\ 1This.mp3 -rw-rw-rw- 1 nobody users 5.5M May 3 2008 2\ Unlimited\ -\ Get\ Ready\ For\ This\ (Wild\ Mix).mp3 -rw-rw-rw- 1 nobody users 4.2M May 3 2008 2\ Unlimited\ -\ Never\ Surrender.mp3 -rw-rw-rw- 1 nobody users 3.8M May 3 2008 2\ Unlimited\ -\ The\ Edge\ of\ Heaven.mp3 -rw-rw-rw- 1 nobody users 3.4M May 3 2008 2\ Unlimited\ -\ Tribal\ Dance\ (Rap\ Edit).mp3 -rw-rw-rw- 1 nobody users 3.9M May 3 2008 2\ Unlimited\ -\ Twilight\ Zone.mp3 -rw-rw-rw- 1 nobody users 3.9M May 3 2008 2\ Unlimited\ -\ Workaholic.mp3
-
Yes, I have.
-
My "Music" share. Specifically the "MP3s" folder within that share.
-
wishie-diagnostics-20240107-0807.zip As requested.
-
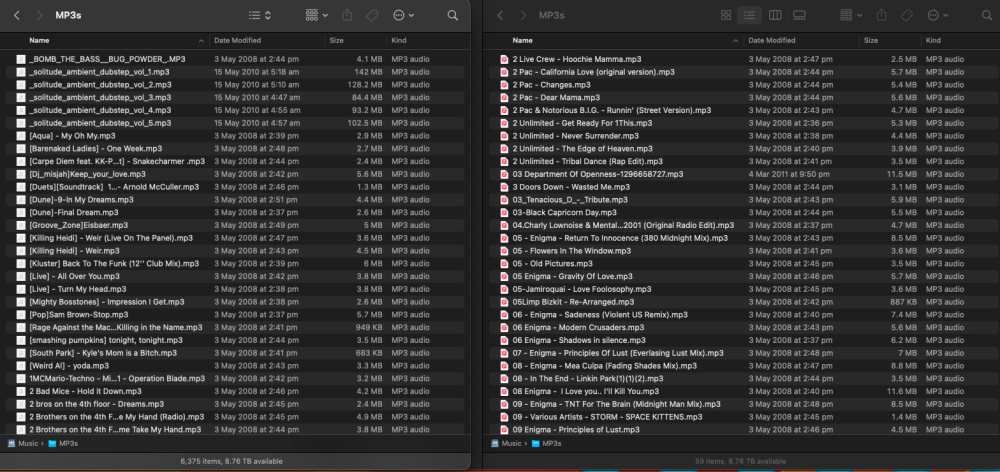
As the title suggests, I have an SMB share that does not show all files. The same share exported by NFS is fine, however. I have already checked file permissions etc. All I can think is that it may be files with invalid chars making SAMBA unhappy? This has been an issue for quite a few years now, but the files in that share aren't critical, so I've just lived with it. Now I would like to get to the bottom of it and fix it. Please dont judge me on the files lol. I collected anything and everything. NFS on the left. SMB on the right. Notice the total file count (bottom of each window).
-
Oh well, im pointing out my experience. Ive update unRAID versions for years without issue. I did nothing different this time, and that was the result. Apparently others have reported they needed to make the USB image again using the unRAID USB Creator, so maybe that was the reason?
-
I understand that.. but I had a working USB, labelled "UNRAID" and then I did the "Update OS" from within the unRAID GUI, so I dont understand why/how it changed the volume label. There must be some quirk with the update from 6.6.7 to 6.7.
-
So, a bit of an update.. I re-imaged my USB stick using the UnRAID USB Creator tool thing, and it booted.. so I've then copied my config/ folder over, and I'm successfully on 6.7 now. What I did notice is, when I was doing the 'update' from 6.6.7 to 6.7, it seems the USB label was 'UnRaid' instead of 'UNRAID'. Perhaps this was the issue? When I made the USB with the creator tool, its 'UNRAID' again.
-
It's been suggested that it might be the USB, but that doesnt explain why it boots fine with every other version of unRAID ive used, and even reverting back to 6.6.7 works perfectly. I suspect its something to do with the USB drivers or something related in 6.7
-
This (6.7) is the first unRAID version that I've had major issues... When I try to boot, everything seems to be going fine, until it tries to mount the UNRAID labelled USB to /boot... I get the following: waiting for /dev/disk/by-label/UNRAID (will check for 30 sec)... and then of course it fails, so /boot isn't mounted, therefore no modules etc are available and network doesn't work. For now, I've had to revert back to 6.6.7
-
Worked perfectly. Thanks again, have a good Christmas.
-
That's better.. 140MB/sec roughly.. Thanks!

