




jkBuckethead
Members
-
Joined
-
Last visited
-
Adding my credentials manually seems to have worked. I've never done this before, I've always clicked to access a network resource, waited till the login box opened, then entered my credentials and checking for them to be saved. For anyone the reads this in the future, it does not need to be specifically "smbuser" as the forum post seems to say. I just added my normal login for my server as a windows credential and it worked.
-
When I attempt to access shares using the IP address, I get exactly the same result. I didn't think it was the problem but I also wiped my credentials clean. This is a new clean install so I didn't have many. This is not an issue of me entering the wrong login info - I'm not even given the chance to try and login. My windows login is a MS account. My unraid server does show up under NETWORK in Explorer, but when I click on it I immediately get the network error. What's really weird is that if I browse for a folder in my backup software, I can select the server, login, and navigate to a share. I did more digging, and I found out that this is not the first time this has happened to me. When I first built my unraid server back in 2018, I could not connect from one of my 3 computers. (Link to relevant 2018 forum post.) Apparently after much searching I discovered a post that led me to discover that windows was apparently checking to see if my shares were secure or guest. At the time I had only created one share and it was public. The computer that could not connect just happened to be a windows pro machine that required me to change a registry key to allow guest access. I changed the key and my problem was solved. Interestingly, when I checked that computer's registry tonight, it was still on that key. Apparently in 7-1/2 years later, I have not had the need for any other edits. There was also a potentially related key on my windows home machines "AuditSmbAccess" that was already set to 0, which may have contributed to them working. I tried adding both registry keys from 2018 to the new machine but they did not help. Apparently that was a fix for a temporary problem. It seems the keys have no bearing on the current problem. I checked a slightly newer laptop for confirmation. Neither key exists on the laptop but it has no problems accessing the unraid shares.
-
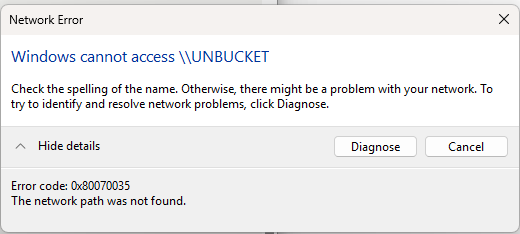
I just completed a clean windows 11 install. For various reasons, this is my first clean windows install in many years, and definitely my first windows 11 install. For at least 10 years, I've been riding the same original install, cloning it from HDD to SATA SSD, then to NVME SSD and finally to larger SSDs. The original install may have been Windows 7 and of course a years or so back I upgraded in place from 10 to 11. I say this just to make it clear that I don't have recent experience with setting up a new windows install. So far the new install has gone well except for when I try and connect to my unraid server using windows explorer. I can see the server in the Network section of explorer, but when I try to open it it fails saying 'Windows cannot access \\SERVER. When I click diagnose, it returns error code 0x80070035 and 'The network path was not found." I googled the error and it suggested disabled File and Printer Sharing, improper network configuration, or SMB 1.0 protocol issues. F&P Sharing is enabled, improper network config is less than enlightening so that leaves SMBV1. I checked SMB settings in unraid and did not see this as an option. I also saw references to SMBV1 being insecure so I hope that isn't my solution. Of course the Microsoft AI added its two cents, but the references were generally very old so even implementing what I could find was difficult due to new menu structures. One thing is interesting is that I was able to access the server, enter credentials and select a sub-folder from within my EaseUS backup software. This success did not carry over to general file access using windows explorer. Regarding my network setup as a whole, there's nothing crazy going on. Several months back I bought a new laptop and I didn't have to do anything special to get it to connect to my unraid shares. I have no idea what is different with this one. I have Windows 11 Home (Version 25H2) installed. Any ideas on what to change would be appreciated. unbucket-diagnostics-20260216-0909.zip
-
It appears it may in fact have been a power problem. Eventually the PSU died and all the drives went down. I'm thinking that my random failures may have been warnings of the ultimate failure. I wanted to replace the PSU, which looks like a modified SFX power supply with just two drive power cables and a super short 24-pin. For a short time I did run it with a standard PSU sitting outside of the case, but I could not make a permanent PSU swap. The enclosure was built such that the PSU cannot be removed without significantly disassembling the case. The case is 100% riveted so tearing it apart and trying to put it back together would have been way more trouble than I care to bother with. Instead, I bought a QNAP TL-D800S. I connected it to my existing LSI HBA and it worked perfectly. I did not try the HBA that came with the enclosure. The enclosure is expensive but seems well-built. Toolless trays are always appreciated. The only downside is the cost, which increased $100 shortly after my purchase. The SATA version is $100 more than the USB-C version, presumably because of the HBA card and cables that are included. I wish they offered a bare version of the enclosure without these extras but no such luck.
-
Yes, I did post the wrong file. Here is the newer one. unbucket-diagnostics-20251220-1943.zip
-
Unfortunately, errors popped up during the rebuild so I got another chance at catching the diagnostics. Two drives showed errors, both have been in place for some time. This is after it rebuilt without any errors for over 16 hours, and nearly 10TB restored. Oddly, the disabled drive has only 1024 errors. The other drive showing errors, but not disabled, has many more at 34,816 but was not disabled. I'm most confused how everything works fine for 16 hours solid, then goes to pot. As I mentioned above, I'd appreciate any guidance about whether I might be pushing the limits of SATA with 2 cables plus a pass-thru. unbucket-diagnostics-20251220-0117.zip
-
I've had this problem for some time. Everything will work fine, often for months at a time, and then out of the blue the MAIN tab will show errors for one or more drives and 1 or 2 of them will be disabled. Oddly, the disabled drives aren't always the ones with the most errors. I still have no idea what causes this. Tonight had a slightly different problem. I had a power outage due to repairs at my neighbor's house. Fortunately I have a UPS with auto shutdown so I had a clean shutdown. However, after rebooting one of the array drives is disabled. Again, there is no indication of why the drive is disabled. There are no errors shown, although there might have been before the system shutdown. The drive attributes do show 47K UDMA CRC error count so maybe there were communication issues, but I still don't understand how that would happen out of the blue. I know SATA can be sketchy but how does it work fine for months then suddenly can't talk to the drive without being touched. The drive is still working and I was able to run a SMART test, which is passed. I'm pretty certain that nothing is really wrong with the drive. Is there any way re-enable the drive without have to create a new config and rebuilding parity? I'm guessing the answer is no, because I have no way of knowing if it still matches its emulated form. I guess that means a new config and rebuilding parity or replacing the drive and rebuilding it. At least if I replace it, then I can set aside the existing drive in case anything happens during the rebuild. Also, I can run additional tests after the rebuild to confirm that the drive is still working okay. Most of the drives that have been giving me trouble are located in an external enclosure. The enclosure is connected to an LSI HBA with mini SAS cables that are 1M long. The enclosure has a dual SAS pass-thru on the back with SAS to SATA breakout cables inside. I have swapped the HBA and all the cables, and still I have problems. The only thing I haven't replaced is the SAS pass-thru because I can't find a suitable replacement. The one I have is a dual port, mounted to a centronics style plate. The only ones I can find are singles, mounted to PCIe brackets. I have a second unused mounting hole but no easy way to mount a PCIe bracket. I've wondered if 1M SAS cables, plus the pass-thru and breakout cables are pushing the distance limits for SAS. I can purchase 1M mini-SAS to SATA breakout cables that would reduce the overall length and eliminate the extra connections to the pass-thru plate. I'd run them through back openings and zip tie them in place. I may do that and see if reliability improves. I included diagnostics just in case, although they are from after the power outage and restart. unbucket-diagnostics-20251220-0117.zip
-
Tonight I was unable to copy a file to my array. When I checked the server, I had two drives offline, and there were 7 or 8 drives showing errors. I rebooted and when it restarted a 3rd drive was shown as missing, along with the other two offline. This is a problem I've experienced randomly throughout the many years that I have been using Unraid. My system will work flawlessly for many months and then out of the blue some number of drives will show errors and go offline. The number of errors can be as low as a few dozen or tens or hundreds of thousands of errors. Sometimes only the offline drives show errors, in other cases additional drives show errors but are not offline. My drives are located in a tower case where some drives are connected to motherboard SATA connectors plus an LSI HBA. Additional drives are located in a cheap external 8-bay drive enclosure connected to another LSI HBA card. The most recent errors have occurred in the external enclosure. Trying to solve the problems, I have replaced the HBA, the cables to the enclosure, and the internal breakout cables. The only thing I haven't changed is the mini-SAS pass-through connector on the enclosure because I haven't been able to find a compatible replacement. Every time I've had drives go offline, I have never been able to find any problems with the offline drives. I usually just replace the drives and rebuild without issue. In a few cases I've had to recreate the parity disks and then copy files from the "failed" drives. Fortunately, I haven't lost any data. (Yes, I know I should have a true backup, until recently I haven't had the means to build a backup box, but I am working on it.) Any tips for tracking down the cause and preventing it in the future? unbucket-diagnostics-20251201-2306.zip
-
Thanks, rebooted and everything looks good. Currently rebuilding. Ironically, I started building a second box to use as backup but haven't finished it. Hopefully this scare will motivate me to get off my butt and finish this weekend.
-
A couple of days ago, I was performing a periodic parity check when I noticed that a drive was disabled. It showing 2000+ errors. I have 2 parity drives so I left the server on until I could deal with it. So, I got home from work tonight and noticed that a 2nd drive was disabled, this time with a whopping 2 errors. Other than the disabled drives things still looked okay. I shutdown and replaced both drives. When I rebooted, the array started with the missing drives emulated. This seemed unusual to me, I thought it usually booted into maintenance mode when drives have been replaced. Anyway, I shut down the array, assigned the new drives and started the array. Of course this started the rebuild, but when I looked at the drive list, I saw that ALL of my data drives indicated Unmountable. I paused the rebuild and came here for help. Obviously I would like to fix the file system on the old drives and continue the rebuild. I know I don't want to format 15 drives full of data. Any ideas what might have happened? I have experienced this type of error in the past with mystery errors leading to drives being disable. I haven't checked yet, but experience tells me that the drives that "failed" are just fine and the data intact. If worst come to worst, I could rebuild the array from scratch if I can at least recover the file system on each drive. All help is appreciated. unbucket-diagnostics-20251104-2103.zip
-
I recently started experiencing random interruptions between my server and different players. I have not made any recent changes to plex or networking, in fact I’ve been away on vacation. I don’t install unraid or plex updates automatically, but the players are updated automatically. I know the roku app recently updated for the new GUI, but I don’t know about google TV. I first became aware of the interruptions when my brother and niece, with whom I share my server, both contacted me because they were unable to see me server. This led me to check my own devices. All my devices are hardwired to my home LAN along with the Unraid server that hosts my Plex server. The first time I checked, both my roku and google tv apps were disconnected from the server. At the same time I could access plex by direct connection from my PC and the plex.tv page. I also checked and confirmed that plex remote access was enabled. I could connect using plex (android) on my phone using wifi and cellular (i.e. remote) connections. A few hours later that same day, my google TV was connected but my roku was not. I had not changed any plex or network settings, the only thing had done was restart the plex docker container. A few hours later, I noticed that both my roku and google TV were again connected. The next day my brother reported that he was able to connect to my server with his roku and laptop. However, when I checked my devices, my roku and google TV were again unable to connect. At this point I checked a few more devices connected to a different TV. Again my 2nd roku and a chromecast with google TV were unable to connect. However, my apple TV was able to connect. Later in the day, my roku and google tv were again connected. The most frustrating part of this is the random nature of the disconnections. How can a roku work one time I check it and then not work in the morning. If it were just the roku devices I might chalk it up to the recent update, but that wouldn’t explain why the google TV devices are also having a problem. It’s also a bit strange that the android-based google TVs are struggling when my android phone has not. Any suggestions will be appreciated. Thanks. Server Version#:1.43.0.10162 Plexinc Docker container Player Version#: Roku 8.6.5.10604-ea6e6ca15-Plex Apple TV 8.45 Google TV 10.30.4.4092
-
I recently experienced two array drive failures while I was out of town for several days. Upon my return home, there were two drive offline. Fortunately I had 2 parity disks so I swapped in some replacements and started a rebuild. During the rebuild I noticed that the two new drives were not being emulated and it said that they needed to be formatted. At this point I suspected the drives hadn't physically failed but both had some sort of file system error. Since the rebuild was already started, I let it proceed while I plugged the drives into a USB port and looked at them further. As unassigned devices, I ran the file check which did indicate there were file system errors of some sort. The array HDDs are formatted with XFS. When I mounted the drives I could read the files fine so I just copied them back to the shares. It took a bit of time but seemed the safest route. After moving the files from the failed disks back to the array, I tried to play them using plex and received the following... Playback Error: An error occurred loading items to play. I rescanned the libraries and got the same error. I also tried playing a file that I confirmed was NOT located on one of the affected drives. Still, I received the same error. The same video file plays just fine through explorer and VLC . I also tried a music file, which is located on another system entirely but accessed by Plex as a remote share. This also would not play. At this point it seems pretty clear the problem is with plex. It might have (or not) been caused by the drive failure, but that seems unlikely. The appdata folder is located on a solid state cache the was not directly affected by the HDD failures. I tried restoring plex from my appdata backup, and still no luck. Any tips for repairing the plex database short of starting from scratch?
-
Apologies in advance for yet another plex transcoding thread. I read a bunch of them and didn't find anything that addresses my issue. I just recently added a P2000 to my system, primarily to provide additional horsepower while processing A LOT of files using TDARR. TDARR setup went fine. I added the Nvidia driver plugin, added the Nvidia variables, selected the Nvidia plugin within TDARR. It has been chugging for over a week and has already saved me over a terabyte. Up till now, the iGPU in my i5-12500 has been more than adequate for my modest plex transcoding needs. In fact, I still plan on using the iGPU with plex, but I thought I would try setting up the P2000 just so I have the option. First, I tried selecting the P2000 in Plex transcoder settings without any additional config changes to the plex docker. In this case, Plex continued playback normally but it did revert to CPU transcoding. This was somewhat expected as I hadn't added any of the nvidia specific variables to my Plex config. I then completed the Nvidia config for the Plex docker, adding the extra parameter, both variables, and checking for spaces... basically everything I read in all the other threads. After this I tried to force another transcode and playback simply stopped. Cycling the play/pause button in the playback did nothing, and after a few minutes the title disappears from the dashboard. Of course I tried with several other files all with the same result. Again, playback just stopped. In the dashboard, network and CPU dropped off immediately as if I had stopped playback. Plex was not frozen as I could still navigate the UI and even play direct play files. All I have to do is select the iGPU inside plex and it takes over the HW transcoding just fine. Clearly something changed when I added the nvidia variables to the plex docker since it didn't revert to CPU transcoding as before. Any idea why the P2000 isn't picking up the transcode as it should? Don't know if it is significant, but I am using the Plex Official docker container.
-
Yes, I was able to enable the iGPU in BIOS so that both are available within unraid and plex. To the original poster's question, there was no need for me to determine which card/renderer represented which GPU. Since I was already configured for transcoding with the iGPU, my plex config includes a Device pointing to /dev/dri/, a folder which now includes two cards and two renderers. In the plex transcoder settings, I have options for Auto, Quadro P2000, and Alder Lake UHD 770. I selected the Alder Lake option and I am able to HW transcode with the iGPU. Plex reverts to CPU transcoding if I choose the P2000. This is likely because I haven't added the Nvidia variables or extra parameter usually required. I may experiment with that later so I have the option, should the need arise. Honestly, this is not a priority for me since I have the P2000 churning through files with TDARR, and the iGPU for my modest plex transcoding needs.
-
I have been working on the very same problem, but with a twist. I added a P2000 to add horsepower to TDARR, but doing so disabled my Plex hardware transcoding via QSV on my i5-12500. Interestingly, I don't even seem to have two cards to choose from. With the iGPU and the P2000 installed, I only see Card0 and renderD128. root@UNBUCKET:~# ls -l /dev/dri/by-path/ total 0 lrwxrwxrwx 1 root root 8 Apr 21 20:13 pci-0000:01:00.0-card -> ../card0 lrwxrwxrwx 1 root root 13 Apr 21 20:13 pci-0000:01:00.0-render -> ../renderD128 root@UNBUCKET:~# I'm wondering if maybe this is a motherboard thing where it disables the iGPU when another GPU is installed. I haven't yet attached a monitor to check the BIOS for a setting that might disable the feature, if it exists. I also might try not installing the P2000 in the first slot and see what happens. If I can get the iGPU and the P2000 to coexist, I would be fine using the iGPU for my modest Plex transcoding needs while I leave the P2000 for TDARR. Down the road when TDARR is finished with existing files, and I only have new files to process, I might use the P2000 for Plex or simply remove it.


