




tj80
Members
-
Joined
-
Last visited
Everything posted by tj80
-
I believe it is but confess I don't really understand the balance or scrub options? This is what it shows when both cache drives are working:
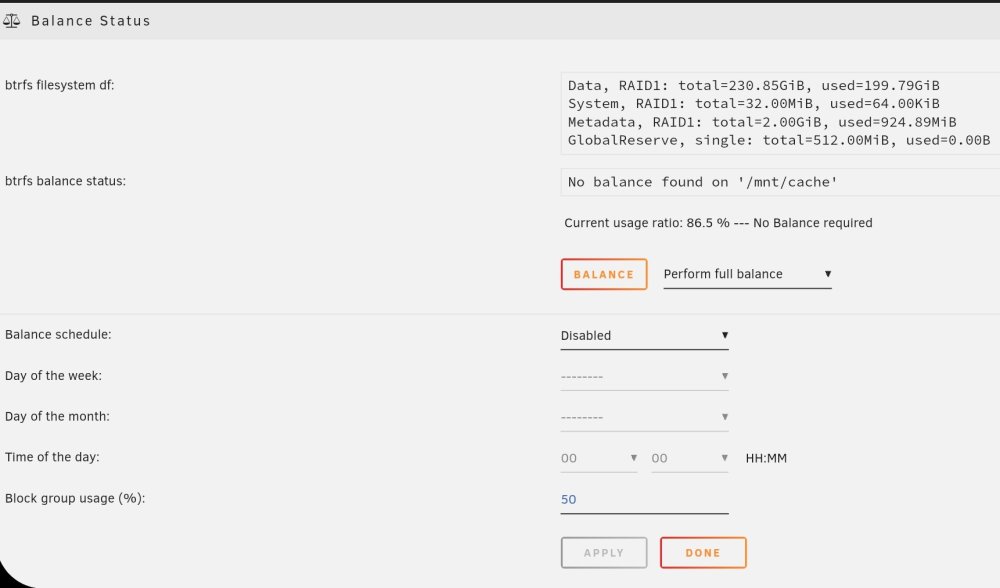
-
Thanks. And is replacing a failed drive just a case of reallocating the slot to the new drive?
-
Hi, I have a cache pool consisting of two SSDs and I think one of them is on the way out. The server is starting to freeze up and on reboot one of the SSDs is not always detected. This is a big problem as none of my VMs or dockers are working! Two questions: - Is there a way to temporarily start the server using the one good SSD until I obtain a new drive? If an array drive fails we can still start it but I cannot see a way to do that with the cache pool? - Is replacing the failed drive the same as if it were an array drive - ie. Just selecting it as the appropriate slot and letting it rebuild from the good drive? Many thanks, Tim
-
Excellent, thank you both!
-
Hi, I have a fully operational UnRAID installation running on a Basic license with several dockers and VMs as well as an unassigned drive, cache drive and 4 disk array. This means I have reached the maximum 6 devices for a Basic license. I would like to move this existing system to a Plus license so I can add a second cache drive - however I would also like to build a second UnRAID server. I could upgrade the existing license and buy a new Basic license for the new server, but it would be cheaper if I bought a new Plus license, moved my existing server to this new license, and then used the old Basic license to build the new server. Can anyone advise how to do this? Many thanks, Tim
-
Thanks, Jonathan!
-
Hi, I've been using UnRAID for many years - since the 4.7 days. I have a Basic license and am considering building a second UnRAID server - I recall when I bought my license years ago there was an option to buy two licenses at a slightly reduced price. Does this option still exist, and does it apply to existing licenses? Many thanks, Tim
-
I now get this happening regularly on a Lenovo Thinkstation E31 (Xeon E3-1225v2), never happened in 8 years continuous running on my old HP Microserver N36L. Have been running unraid 24x7 since 2011 (originally version 4.7, currently 6.8.3 on a Basic license) and never had the problem until moving to the new hardware about 4 months ago. Same installation - I just moved the USB drive and all the disks across to the Thinkstation and the problem started and has been recurring since then. Stopping then restarting the array fixes it for a few days or weeks, then it comes back again.
-
Hi, Apologies for the simple question, but can anyone tell me how to backup a docker and then roll back to that version in case of a bad docker update? Specifically I'm running HomeAssistant, which often introduces changes which break things in updates. These are always fixable, but take effort and time to resolve. I'd like to be able to update the docker, but have the option of rolling that update back to the previous working version in case the update breaks too many things! I can then choose to upgrade at a more convenient time when I can fix the problems. Many thanks, Tim
-
Unfortunately I have a whole load of MQTT devices set up manually in configurations.yaml already and haven't used discovery previously - maybe it's the mix and match it doesn't like. Do you happen to have an example of a standard sensor which should be available if it's working? Then I could just set that up manually as a test. Thanks, Tim
-
Yep, HomeAssistant and Mosquitto are both running as Dockers on my unraid server. Does this look about right? 192.168.0.206 is the IP of Mosquitto and it's running on the standard port 1883: Then in my HA configuration.yaml I have:
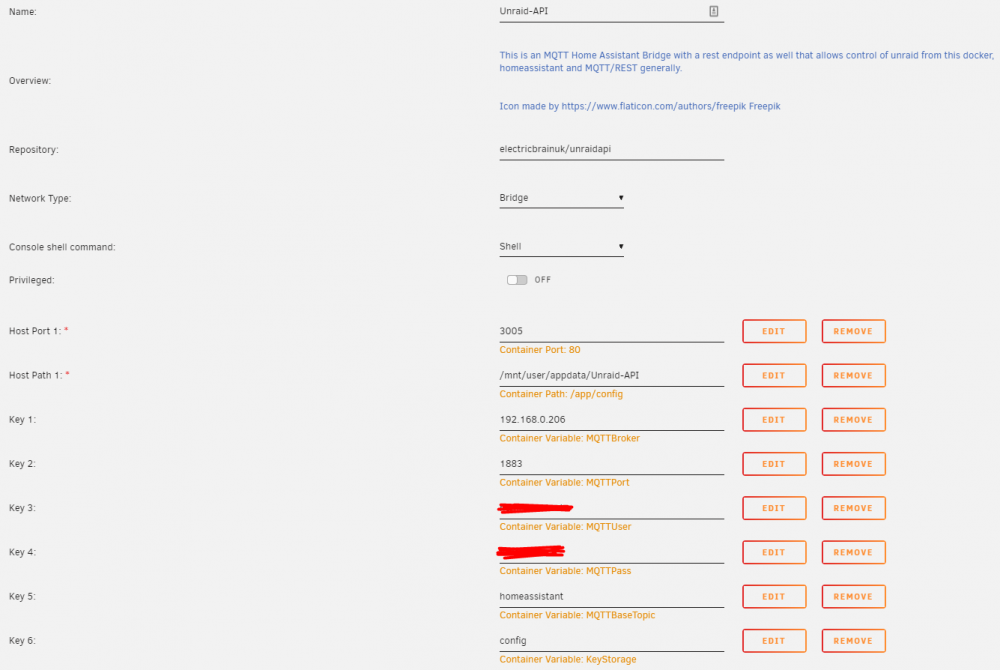
-
Thanks. MQTT is definitely OK - running Mosquitto with about 20 Tasmota devices talking to HA quite happily. I've installed Glances as you suggested, that's working fine in HA now as well - but still nothing from UnRAID-API! It's not showing up on the Integrations page even with discovery enabled, so I wonder if I have misconfigured something and UnRAID-API can't actually talk to the MQTT broker for some reason? Any idea how to check that? I can just about configure devices but delving further into MQTT is a bit beyond me I'm afraid. Cheers, Tim
-
I was really excited to find this as I've been looking for a way to pull UnRAID data into HA for a long time! Many thanks, @ElectroBrainUK! However - I can't get anything to appear in HA! I have installed UnRAID-API as a Docker and if I go into the web UI it correctly shows a whole load of data about my UnRAID server. If I click on the "MQTT devices" option in the UnRAID-API web UI I get this in the log - not sure what any of it means though: > [email protected] start /app > cross-env NUXT_HOST=0.0.0.0 NUXT_PORT=80 NODE_ENV=production node --max-old-space-size=4096 server/index.js READY Server listening on http://0.0.0.0:80 (node:26) UnhandledPromiseRejectionWarning: Error: ENOENT: no such file or directory, open 'config/mqttDisabledDevices.json' at Object.openSync (fs.js:447:3) at Proxy.readFileSync (fs.js:349:35) at IncomingMessage.<anonymous> (/app/api/mqttDevices.js:19:19) at IncomingMessage.emit (events.js:205:15) at IncomingMessage.EventEmitter.emit (domain.js:471:20) at endReadableNT (_stream_readable.js:1154:12) at processTicksAndRejections (internal/process/task_queues.js:84:9) (node:26) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). (rejection id: 1) (node:26) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code. (node:26) UnhandledPromiseRejectionWarning: Error: ENOENT: no such file or directory, open 'config/mqttDisabledDevices.json' Any help would be very much appreciated! Thanks, Tim

