




snolly
Members
-
Joined
-
Last visited
Everything posted by snolly
-
I am going to leave that here. Legrand KEOR SP works out of the box with Unraid without the need of any plugins or third party drivers.
-
You should treat it as it will do. The documentation does not mention anything and ChatGPT also did not give a definitive answer.
-
Hello, can an existing VM be converted to use SCSI? Reinstalling everything would be a huge pain.
-
Mine fixed itself after editing the VM config because I changed some hardware. After saving it with the new config (new SSD direct pass through) it fixed this annoying bug.
-
Nope this still happens
-
what is the exact command that you used?
-
Same issue in 6.12.4 - Windows 11 VM with direct pass through of an RTX3080ti and an NVME disk. It takes a couple of minute for the unraid boot logo to show up (in this time log gets filled with this exact error) but then the VM boots and works properly.
-
I got the 13600. I have assigned all except the last 2 E-Cores to my gaming VM and it runs flawlessly.

-
please see this post if you need further help and maybe you want to update the affected drives from within unraid itself
-
So, firmware M3CR046 that solves the issue is not available from Crucial in a direct download. You need to use Windows and Crucial Executive software which is crappy and some people are mentioning that in order to update the firmware this way you need to be able to write to it and actually have something being written to the disk while updating otherwise the process will fail - which is totally ridiculous. So I made a bootable portable Win11 usb stick which took 3 hours to do and the Crucial software does not launch in there (crashes). I then combed the interwebs and I found a user who contacted Crucial and they gave him the firmware file. Thread here and I also attached the FW on this post. You need to unzip the zip file and use the .bin file in there. I had a BTRFS cache with 2 affected MX500 drives in there. Stopped the array Removed one if the MX500. Started the array and waited for it to rebuild the BTRFS cache. Now one of the MX500 was listed as unassigned device. Copied the FW .bin file somewhere in Unraid run this command hdparm --fwdownload /mnt/user/athens/temp/mx500/1.bin --yes-i-know-what-i-am-doing --please-destroy-my-drive /dev/sdb where first argument is the path to the .bin file and the second one is the name of the drive I need to update. In this case /dev/sdb rebooted the server and I checked that the drive has been updated to M3CR046 (click on the drive's name and go to identity tab) stopped the array and added the updated drive back to the cache. started the array and wait for the cache rebuilt. stopped the array removed the other drive and then do steps 3 to 9 for the second drive. I hope this helps anyone who faces the same issue. Hopefully I will not face the same problems again. M3CR046.zip
-
I will remove one by one from the array and direct pass through to one windows vm I have and try to update them there. I just realised that I cannot passthrough sata devices.
-
Hmmm, thanks for the tip. Both my MX500 are on M3CR045. I will try to update them to at least M3CR046 that got the issue resolved. Can I do that with Unraid or do I have to plug them in a windows machine?
-
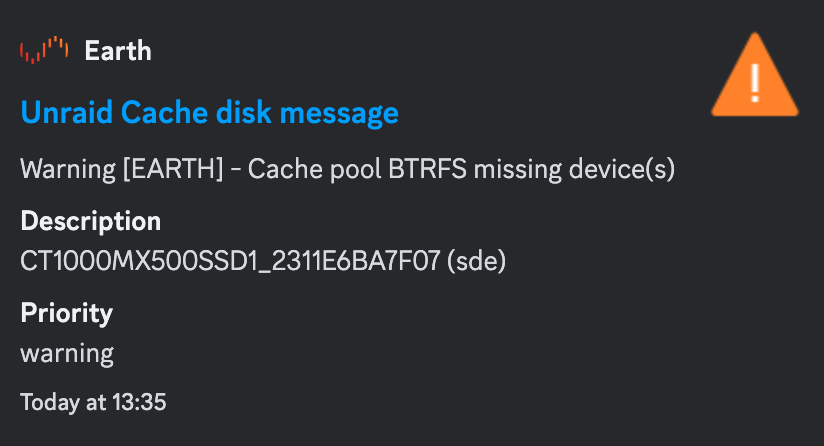
Unfortunately even after replacing the (what I thought) faulty new SSD - the issue is still here. At some point I get a warning about my log being full and I know what this means. Cache issues that flood the logs. Issues are like this: May 25 17:22:05 Earth kernel: BTRFS info (device sdb1): read error corrected: ino 0 off 7569215369216 (dev /dev/sde1 sector 255824472) May 25 19:07:10 Earth kernel: I/O error, dev sdb, sector 517930272 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 If I go and perform a Scrub I get millions of uncorrected errors. If I restart the array then one of the 2 cache disks is usually gone (this time it didn't) After the restart docker.img is corrupt and docker cannot start. Previous times libvirt.img was also corrupt. This time it didn't. I changes sata ports, cables, replaced the 1 SSD that was gone after errors and restarts. This is the log I kept CT1000MX500SSD1_2302E69B81B5 (sde) - red cable ------> this one I got replaced CT1000MX500SSD1_2311E6BA7F07 (sde) - red cable / ------> this one is the new ssd in place of the what I thought faulty one CT1000MX500SSD1_2302E69B81AF (sdb) - black cable This is which drive went missing after restarting the array after getting all the BTRFS errors. 10/4 CT1000MX500SSD1_2302E69B81B5 12/4 CT1000MX500SSD1_2302E69B81B5 12/4 CT1000MX500SSD1_2302E69B81AF (pre-clear errors) 22/4 CT1000MX500SSD1_2302E69B81B5 29/4 CT1000MX500SSD1_2302E69B81B5 27/5 CT1000MX500SSD1_2311E6BA7F07 (sde) This is the error I get after I restart the array after syslog is flooded with errors Also attached are diagnostics. So this happens every couple of days and I have to rebuild my docker.img and possibly the libvirt.img. I am lost here, If BTRFS is to blame I could go with an XFS single drive cache but what about redundancy? Any help would be greatly appreciated. Cheers earth-diagnostics-20230527-1332.zip
-
Nevermind I managed, created a system-new share with copy on write set to auto. stopped docker and vm moved everything from system to system-new renamed system to system-old renamed system-new to system restarted docker and vm again thanks
-
Thanks. I have no idea on how to do that. If I create a new system share it would have a different name and paths, and even if I copy data from old system to new system how would I make the new system share the active one that unraid uses?
-
You mean this link right? Also forgive my ignorance, I did not set anything in the system share, so maybe NOCOW is the default? Should I change this to Auto now?
-
I removed the faulty SSD from the cache pool and it automatically run balance and scrub which both succeeded with no errors. I then tried to preclear the faulty SSD and even that fails. So I guess that was the issue all along. Just for the shake of knowledge, what is the point of mirroring / redundancy if when we face situations like this (one faulty disk) we also get corruptions and data loss? Shouldn't this be avoided and have the system mark the faulty drive as failed instead of all this mess? Thanks again for all the help
-
I think one of the two new SSDs is faulty. It's the one you said that it went missing at some point and I can see in the logs that there are IO errors on it. I will remove it from the pool and leave the pool with one SSD and then run scrub again.
-
second scrub reported zero errors up until halfway were it aborted. third scrub reported zero errors and it aborted half way as well. I do not know what to do at this point.
-
first scrub finished with thousands of uncorrectable errors and zero corrected. second scrub that runs now shows 0 errors so far. I am quite stumbled, if first pass had uncorrectable errors how come second pass has none?
-
ok, thanks, never knew there were options for scrubs and scheduled scrubs in the UI. running that and reverting with results.
-
wow, thanks for the reply. can you point to some documentation on how to run a correcting scrub?
-
Hello all, I was on a 9th gen Intel System (that worked perfectly fine for years) and I decided to upgrade to a 13th gen one. My cache lived on 2x500GB Crucial SSDs in a BTRFS mirroring pool. Along with the new hardware I bought 2x1TB Crucial SSDs to replace the 500GB ones. I did that 2 nights ago by removing the 1st 500GB and putting the 1TB in its place, let the rebuilding process finish and then did the same with the 2nd SSD. That completed without any issues. Last night I replaced the motherboard/cpu/ram and rebooted the system. The array started just fine but both docker and VMs were unavailable due to docker.img and libvirt.img corruption errors. So I deleted both docker.img and libvirt.img, recreated them and the Docker and VM services started (and work) correctly. I have not restored any VMs (I am using the community backup plugin and that doesn't seem to have a restore functionality - if someone can enlighten me I would appreciate it). Now I get a plethora of BTRFS errors in the logs and I am not sure what needs to be done. Is one or both of the new 1TB SSDs faulty? Can I remove one of the two from the array and stay with one SSD while waiting for the faulty one to be replaced? How do I know if other stuff that lives in the cache is not corrupted (like appdata - docker apps seem to work fine btw). Any help for course of action would be greatly appreciated. Attaching diagnostics for more info on the system. Thanks earth-diagnostics-20230412-0039.zip
-
FYI. Using 225.2 seems to have fixed freezing issues. Win11 VM is up and running for 24h straight.
-
I am having lockups without having memoryBacking in my XML




