




johnsanc
Members
-
Joined
-
Last visited
-
Any chance of updating this to 3.14.x? zstd support with 3.14 is super useful.
-
I am trying to move stuff around to upgrade XFS v4 to v5. I think there is a flaw in the formulas used for allocation since I sometimes get results like this, which will cause the move to fail and disk to fill up beyond its capacity. I have no idea what causes this, but the only way I've found to mitigate it is to select different destination disks or choose more granular selections (which is a ton of clicking)

-
Ah excellent! That is a great solution. Thanks for the quick enhancement!
-
I upgraded to 7.2.0 and got the notification that a few of my drives are XFS v4. I followed the migration guide to start the migration to v5 with the WebUI. I started mover manually and started seeing disk reads for the disk I chose to empty. So far so good. However, then I starting browsing around my user share and noticed a bunch of files missing. Apparently all of the data from the disk I chose to empty was completely omitted form user shares. This just about gave me a heart attack because I thought data was being moved into the abyss. Is this how its supposed to work or is this a bug? If this is intentional the documentation and UI really needs to be updated to tell the user thats expected. If this is expected it really limits the utility of this feature... I don't understand why data for the entire disk is completely inaccessible by user shares during the entire move operation when this isn't the case for regular movements of data. https://docs.unraid.net/unraid-os/using-unraid-to/manage-storage/file-systems/#converting-to-a-new-file-system-type
-
Yes for now i set "Move Now button follows plugin filters" to "no" to get the empty disk function to work.
-
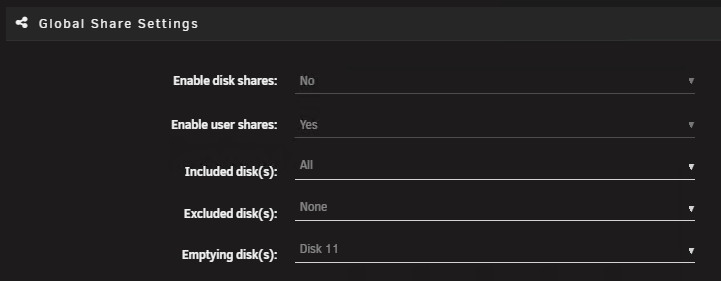
Yes its a very weird design choice to put it there... but that feature is available in UI shoved under Global Share settings as shown in my previous screenshot
-
You can also configure that in UI now. Its listed in the documentation for how to migrate fileystems. I have to do that for XFS v4 to v5 for a few disks. I basically have to disable Mover Tuning for this type of move since it doesn't seem to support that feature.
-
Is it possible to update the plugin to support the new "emptying disk(s)" feature in Global Share settings? This is very useful for moving data off of disks to change the filesystem without having to use something like unbalance which is extremely slow for me.
-
Quick update... I tried replacing my key to a new flash drive, and in the process of the key validation using the web replacement method it failed and threw an error saying there was an issue communicating with the flash device. I manually replaced the key and it booted fine... but then after a few minutes the flash was completely dropped again. I tried one more time in safe mode, and the same thing happened. I tried switching USB ports and so far so good... Maybe I have a USB port that has gone bad. I'll monitor to see if that fixed the issue.
-
So one thing I've noticed is this most commonly seems to happen in the middle of the night, sometime after the trim jobs happen at 5:30 AM. No idea if its related, but I may try changing the schedule to see if the crashes start to align with a different time.
-
Darn. Well, perhaps an enhancement request would be to save diagnostics on the "forced shutdown" scenario like my photos above. Don't know why its only saved on clean shutdown. Perhaps there are clues in other logs outside of syslog.
-
Yeah I suspected the ATA2 could be an issue so I moved that drive to a totally different controller. The latest crash yesterday was after that move so I suspect its unrelated. I have no idea what the "Spurious native interrupt" errors are. Based on the syslog i provided those are present all the way back in August. I never had this crash issue until after upgrading to 6.12.14 which was end of November. Is there anything else I can do to enable better logging when the issue happens again? I saw literally nothing captured around the time of the crash. Does mirroring to flash include more info than if I were just writing to `system` on cache drive?
-
Thanks @JorgeB. Syslog server was on, just not mirrored to flash. A copy of logs are also not saved to flash in this shutdown scenario. I've attached the syslog from the system folder which resides on my cache drive. I wasn't aware that that diagnostics didn't include this. syslog-johnsanc.zip
-
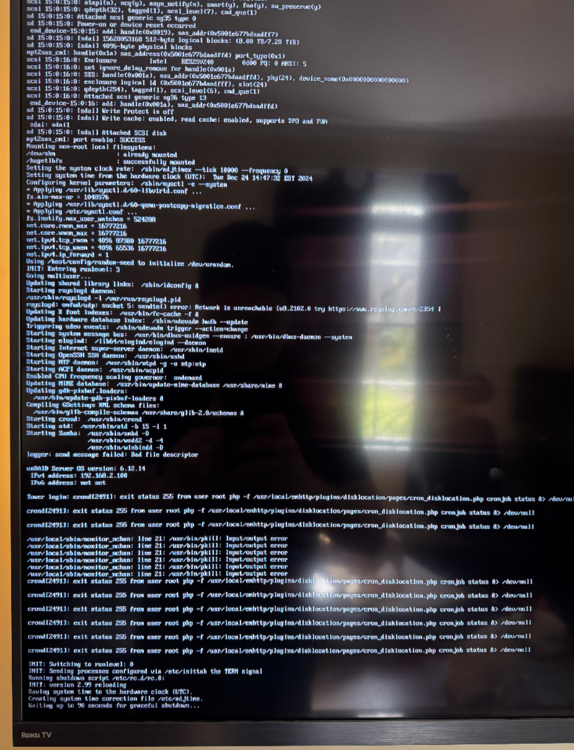
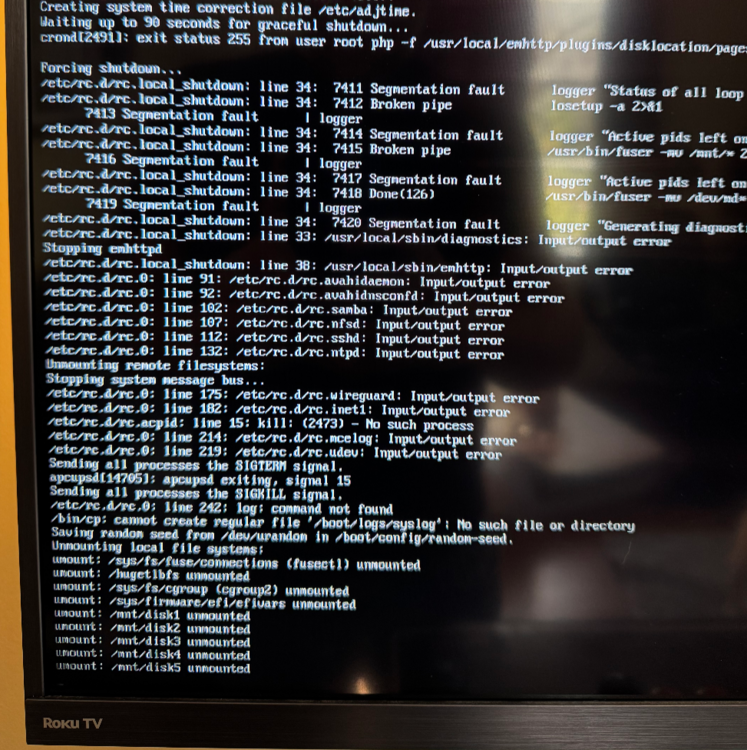
Lately I've been having stability issues with unraid after upgrading to 6.12.14. Its sporadic and seems to occur every few days. Basically the entire server becomes unresponsive. VMs and dockers are killed, web access no longer works, and SSH also doesn't work. However, If I hit the power button on my server, I can see in the console with a connected monitor that the server does shut down after the scripts execute. The screenshot shows the console and the shutdown process. I see some errors but I do not know what they mean. Also, it never gracefully shuts down. After 90 seconds it goes into forced shutdown. I couldn't find anything in the logs that aligns with the timing of the issue. The most recent occurrence was around 8:00 PM ET 12/29. The photos are from a few days ago, but the behavior seems to be the same every time. Diagnostics attached. The only thing I can think of is a failing USB drive since its very old and I ran into another issue a few weeks ago where it said there was no USB device connected but the server was still running from RAM. I haven't been able to reproduce that issue, but I havent tried transferring my license to a new device yet. Anyone have any ideas? tower-diagnostics-20241229-2013.zip
-
OK one more update... this is definitely an unraid bug. Whenever I try to move a single file with a super long name over SMB to the share that uses the cache (ZFS), it fails and all the offending files are ghosted again like my original screenshot. Once again if I delete the empty directory from cache, the files reappear on disk27 (XFS). If I disable the cache completely, I can write the file directly to the array without any issues or impact to any other files on that disk.. This should be enough info for others to try to reproduce the issue. Note the files I was using have Korean and/or Japanese characters in them. I also confirmed that a cache disk with XFS does NOT exhibit this issue. So whatever the issue is, it has something to do with ZFS.





