




johnsanc
Members
-
Joined
-
Last visited
Everything posted by johnsanc
-
Any chance of updating this to 3.14.x? zstd support with 3.14 is super useful.
-
I am trying to move stuff around to upgrade XFS v4 to v5. I think there is a flaw in the formulas used for allocation since I sometimes get results like this, which will cause the move to fail and disk to fill up beyond its capacity. I have no idea what causes this, but the only way I've found to mitigate it is to select different destination disks or choose more granular selections (which is a ton of clicking)

-
Ah excellent! That is a great solution. Thanks for the quick enhancement!
-
I upgraded to 7.2.0 and got the notification that a few of my drives are XFS v4. I followed the migration guide to start the migration to v5 with the WebUI. I started mover manually and started seeing disk reads for the disk I chose to empty. So far so good. However, then I starting browsing around my user share and noticed a bunch of files missing. Apparently all of the data from the disk I chose to empty was completely omitted form user shares. This just about gave me a heart attack because I thought data was being moved into the abyss. Is this how its supposed to work or is this a bug? If this is intentional the documentation and UI really needs to be updated to tell the user thats expected. If this is expected it really limits the utility of this feature... I don't understand why data for the entire disk is completely inaccessible by user shares during the entire move operation when this isn't the case for regular movements of data. https://docs.unraid.net/unraid-os/using-unraid-to/manage-storage/file-systems/#converting-to-a-new-file-system-type
-
Yes for now i set "Move Now button follows plugin filters" to "no" to get the empty disk function to work.
-
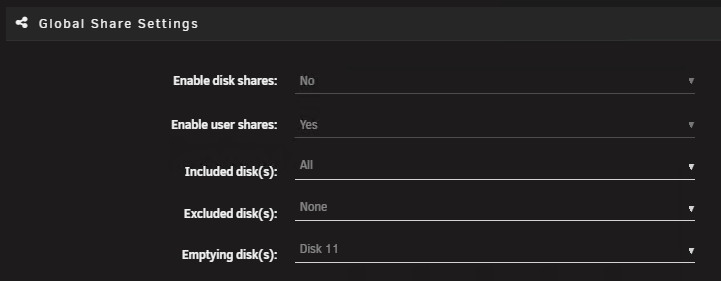
Yes its a very weird design choice to put it there... but that feature is available in UI shoved under Global Share settings as shown in my previous screenshot
-
You can also configure that in UI now. Its listed in the documentation for how to migrate fileystems. I have to do that for XFS v4 to v5 for a few disks. I basically have to disable Mover Tuning for this type of move since it doesn't seem to support that feature.
-
Is it possible to update the plugin to support the new "emptying disk(s)" feature in Global Share settings? This is very useful for moving data off of disks to change the filesystem without having to use something like unbalance which is extremely slow for me.
-
Quick update... I tried replacing my key to a new flash drive, and in the process of the key validation using the web replacement method it failed and threw an error saying there was an issue communicating with the flash device. I manually replaced the key and it booted fine... but then after a few minutes the flash was completely dropped again. I tried one more time in safe mode, and the same thing happened. I tried switching USB ports and so far so good... Maybe I have a USB port that has gone bad. I'll monitor to see if that fixed the issue.
-
So one thing I've noticed is this most commonly seems to happen in the middle of the night, sometime after the trim jobs happen at 5:30 AM. No idea if its related, but I may try changing the schedule to see if the crashes start to align with a different time.
-
Darn. Well, perhaps an enhancement request would be to save diagnostics on the "forced shutdown" scenario like my photos above. Don't know why its only saved on clean shutdown. Perhaps there are clues in other logs outside of syslog.
-
Yeah I suspected the ATA2 could be an issue so I moved that drive to a totally different controller. The latest crash yesterday was after that move so I suspect its unrelated. I have no idea what the "Spurious native interrupt" errors are. Based on the syslog i provided those are present all the way back in August. I never had this crash issue until after upgrading to 6.12.14 which was end of November. Is there anything else I can do to enable better logging when the issue happens again? I saw literally nothing captured around the time of the crash. Does mirroring to flash include more info than if I were just writing to `system` on cache drive?
-
Thanks @JorgeB. Syslog server was on, just not mirrored to flash. A copy of logs are also not saved to flash in this shutdown scenario. I've attached the syslog from the system folder which resides on my cache drive. I wasn't aware that that diagnostics didn't include this. syslog-johnsanc.zip
-
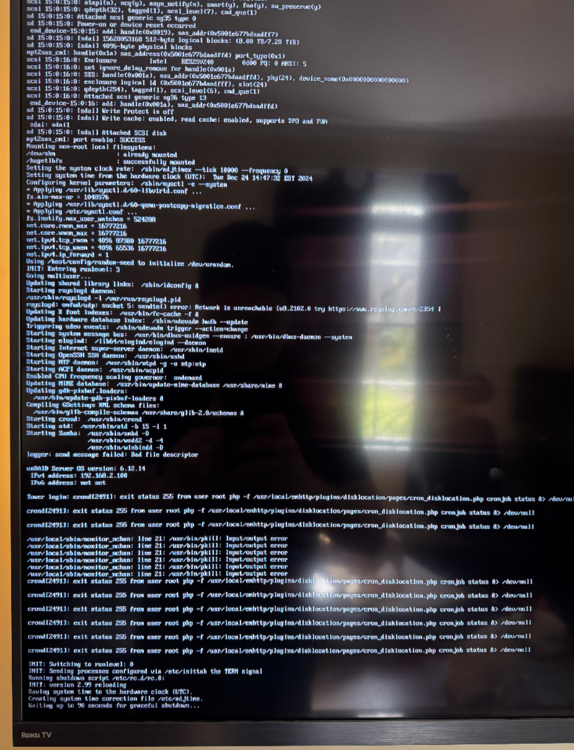
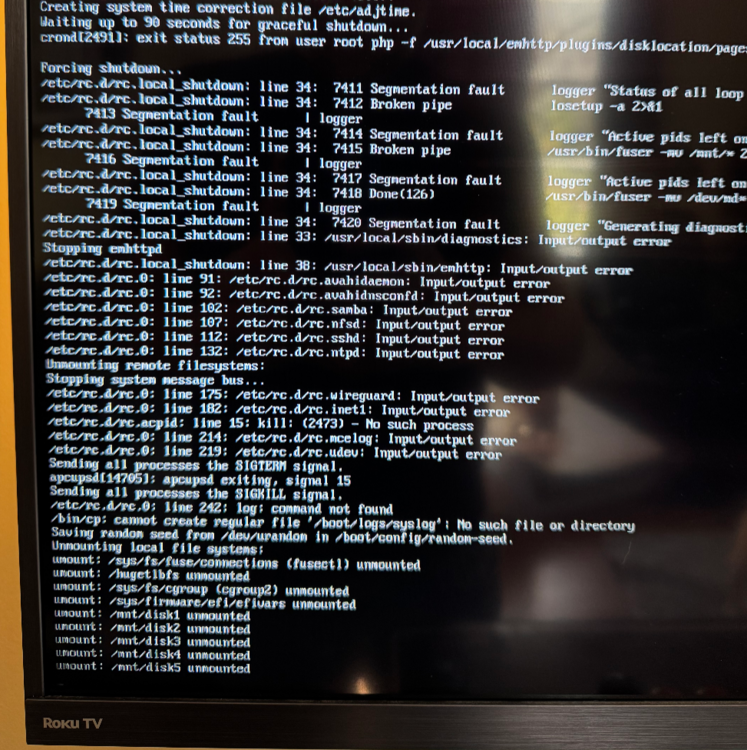
Lately I've been having stability issues with unraid after upgrading to 6.12.14. Its sporadic and seems to occur every few days. Basically the entire server becomes unresponsive. VMs and dockers are killed, web access no longer works, and SSH also doesn't work. However, If I hit the power button on my server, I can see in the console with a connected monitor that the server does shut down after the scripts execute. The screenshot shows the console and the shutdown process. I see some errors but I do not know what they mean. Also, it never gracefully shuts down. After 90 seconds it goes into forced shutdown. I couldn't find anything in the logs that aligns with the timing of the issue. The most recent occurrence was around 8:00 PM ET 12/29. The photos are from a few days ago, but the behavior seems to be the same every time. Diagnostics attached. The only thing I can think of is a failing USB drive since its very old and I ran into another issue a few weeks ago where it said there was no USB device connected but the server was still running from RAM. I haven't been able to reproduce that issue, but I havent tried transferring my license to a new device yet. Anyone have any ideas? tower-diagnostics-20241229-2013.zip
-
OK one more update... this is definitely an unraid bug. Whenever I try to move a single file with a super long name over SMB to the share that uses the cache (ZFS), it fails and all the offending files are ghosted again like my original screenshot. Once again if I delete the empty directory from cache, the files reappear on disk27 (XFS). If I disable the cache completely, I can write the file directly to the array without any issues or impact to any other files on that disk.. This should be enough info for others to try to reproduce the issue. Note the files I was using have Korean and/or Japanese characters in them. I also confirmed that a cache disk with XFS does NOT exhibit this issue. So whatever the issue is, it has something to do with ZFS.
-
OK so this is really weird... after a bit of digging I noticed that the ghost files show up on the user share, but NOT user0. So I checked my cache drive and I noticed that that there was an empty folder for where the offending files would be. I deleted this folder and then the ghost files went away from the user share. Any idea what happened here? This clearly looks like some kind of bug with the unraid fuse. Not sure if it matters... but my cache drive is zfs and my array drives are xfs. EDIT: Even weirder.... Once I deleted the empty folder from the cache drive the original good files magically appeared on disk27!!
-
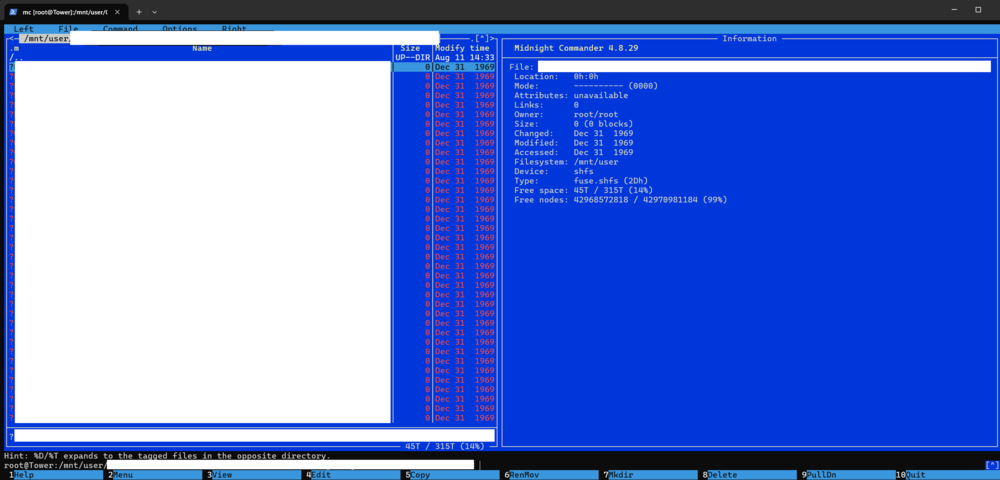
I recently upgraded to 6.12.14 from 6.12.11 and I'm not sure if its a coincidence that I just noticed or if its an issue with the upgrade... but I have some files that have very long names due to doublebyte characters. I noticed that some of these files show up in my user share when browsing with midnight commander, but they do not appear to be present on any disk according to the file browser UI. They are searchable but there's no disk number associated with them. In MC they are all prefixed with a ? character, have no permissions, no size, and no valid date. I also cannot delete or rename these files. In MC i get an error: "cannot stat: 'xxxxxxxxxx' unsupported operation (95)" Any idea how to fix this? Stopping and restarting the array did not resolve the issue. I know these files existed before, but now they are just... gone, and only these references remain. The only common thing I've found is that they are all long filenames with doublebyte characters, approximately 140 to 254 bytes.
-
The latter. New config to reenable the disk. There was nothing in my control writing to array since everything is setup to use the cache pool. I really have no idea what these random write attempts are when the errors occur during spinup, spindown, array shutdown. Frankly I'm leaning more toward only ever rebuilding disks if there's a complete disk failure. Situations like this seem like a disk rebuild from parity would do more harm than good.
-
Not yet, I tried all the other suggested solutions from past threads like firmware updates and disabling EPC. I am in the middle of a correcting parity check, and the concerning thing is that I have some random sync corrections, 92 so far and about 25% complete. They are strewn about and not all in one place. The areas where the write errors occurred had no sync issues when I tested with Parity Problems Assistant with a sector range. Is that expected? If unraid detects an error and kicks the disks offline why would i have sync issues in these other places? I am doing a correcting parity check instead of disk rebuilds because frankly I am more confident in the data on the disks than I am with the parity. Last time this happened I did a new config and revalidated all my files with File Integrity exports, and not a single file had an issue.
-
Well unfortunately the issue is not resolved, but it does seem to be related to spinup / spindown. After the last time I ran into this issue I did a new config and i think my disk settings were reset to never spin down. Just a few days ago I changed my settings to spindown disks after about an hour. Shortly thereafter I ran into the issue again with 2 disks being disabled within the span of a day or so. Now I see errors like this whenever the issue occurs: (Diagnostics also attached...) Oct 18 01:50:48 Tower emhttpd: spinning down /dev/sdae Oct 18 01:56:42 Tower emhttpd: spinning down /dev/sdw Oct 18 02:00:52 Tower emhttpd: read SMART /dev/sdx Oct 18 02:02:45 Tower emhttpd: read SMART /dev/sdi Oct 18 03:02:15 Tower emhttpd: spinning down /dev/sdag Oct 18 03:03:02 Tower emhttpd: spinning down /dev/sdx Oct 18 03:06:30 Tower kernel: sd 15:0:12:0: attempting task abort!scmd(0x00000000aaca4222), outstanding for 15276 ms & timeout 15000 ms Oct 18 03:06:30 Tower kernel: sd 15:0:12:0: [sdae] tag#374 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00 Oct 18 03:06:30 Tower kernel: scsi target15:0:12: handle(0x0016), sas_address(0x5001e677bdaadff4), phy(20) Oct 18 03:06:30 Tower kernel: scsi target15:0:12: enclosure logical id(0x5001e677bdaadfff), slot(20) Oct 18 03:06:30 Tower kernel: sd 15:0:12:0: device_block, handle(0x0016) Oct 18 03:06:33 Tower kernel: sd 15:0:12:0: device_unblock and setting to running, handle(0x0016) Oct 18 03:06:33 Tower kernel: sd 15:0:12:0: [sdae] tag#373 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=DRIVER_OK cmd_age=18s Oct 18 03:06:33 Tower kernel: sd 15:0:12:0: [sdae] tag#373 CDB: opcode=0x88 88 00 00 00 00 03 7c 27 10 28 00 00 00 08 00 00 Oct 18 03:06:33 Tower kernel: md: disk1 read error, sector=14967836648 Oct 18 03:06:33 Tower kernel: sd 15:0:12:0: task abort: SUCCESS scmd(0x00000000aaca4222) Oct 18 03:06:33 Tower kernel: sd 15:0:12:0: [sdae] Synchronizing SCSI cache Oct 18 03:06:33 Tower kernel: sd 15:0:12:0: [sdae] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=DRIVER_OK Oct 18 03:06:33 Tower kernel: mpt2sas_cm1: mpt3sas_transport_port_remove: removed: sas_addr(0x5001e677bdaadff4) Oct 18 03:06:33 Tower kernel: mpt2sas_cm1: removing handle(0x0016), sas_addr(0x5001e677bdaadff4) Oct 18 03:06:33 Tower kernel: mpt2sas_cm1: enclosure logical id(0x5001e677bdaadfff), slot(20) Oct 18 03:06:33 Tower kernel: mpt2sas_cm1: handle(0x16) sas_address(0x5001e677bdaadff4) port_type(0x1) Oct 18 03:06:34 Tower kernel: md: disk1 write error, sector=14967836648 Oct 18 03:06:34 Tower kernel: scsi 15:0:18:0: Direct-Access ATA ST18000NM002J-2T PAL9 PQ: 0 ANSI: 6 Oct 18 03:06:34 Tower kernel: scsi 15:0:18:0: SATA: handle(0x0016), sas_addr(0x5001e677bdaadff4), phy(20), device_name(0x0000000000000000) Oct 18 03:06:34 Tower kernel: scsi 15:0:18:0: enclosure logical id (0x5001e677bdaadfff), slot(20) Oct 18 03:06:34 Tower kernel: scsi 15:0:18:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) Oct 18 03:06:34 Tower kernel: scsi 15:0:18:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) Oct 18 03:06:34 Tower kernel: sd 15:0:18:0: Power-on or device reset occurred Oct 18 03:06:34 Tower kernel: sd 15:0:18:0: Attached scsi generic sg31 type 0 Oct 18 03:06:34 Tower kernel: end_device-15:0:18: add: handle(0x0016), sas_addr(0x5001e677bdaadff4) Oct 18 03:06:34 Tower kernel: sd 15:0:18:0: [sdaj] 35156656128 512-byte logical blocks: (18.0 TB/16.4 TiB) Oct 18 03:06:34 Tower kernel: sd 15:0:18:0: [sdaj] 4096-byte physical blocks Oct 18 03:06:34 Tower kernel: sd 15:0:18:0: [sdaj] Write Protect is off Oct 18 03:06:34 Tower kernel: sd 15:0:18:0: [sdaj] Mode Sense: 7f 00 10 08 Oct 18 03:06:34 Tower kernel: sd 15:0:18:0: [sdaj] Write cache: enabled, read cache: enabled, supports DPO and FUA Oct 18 03:06:34 Tower kernel: sdaj: sdaj1 Oct 18 03:06:34 Tower kernel: sd 15:0:18:0: [sdaj] Attached SCSI disk tower-diagnostics-20241018-2242.zip
-
I'm not sure how feasible this would be... but is it possible to have an "Opportunistic Mover" mode? Basically instead of scheduling things based on time or age or free space on cache, why not move things after array disks have spun down for a certain period of time? You could maybe even get creative and move certain shares based on the disks they have in scope. For example if my Movies share occupies disks 1,2,3 and all 3 of those have been spundown for at least 30 minutes... then kick on mover and move stuff to those disks. If lets say disk 2 is active and spun up, then don't move anything for shares that have disk2 in scope.
-
AMD user here. Looks like I should have searched harder before posting my thread about the same issue. I also am capped about nearly the same speed. Granted my hardware isn't as good as OP, but still I think there may be something in common here. Difference with mine is that i don't see a specific core maxed out at 100%, but I do see unraidd0 sitting at 95% cpu according to top. Is that normal?
-
I think the issue may be CPU related due to single-threaded nature of parity checks. After my sync was complete I added 2 more data disks and the check was only going at about 90-95 MB/s. I noticed that unraidd0 process was using 95% cpu according to top. I rebooted, tried a check again and now its going at 105-110 MB/s steady which is an improvement. I suppose its not a high priority, but has there been any consideration to multithread the parity sync/check?
-
Sorry, I probably wasn't clear. A picture is always better: I can see its ordered by Parity, then data, then pools. But the data disks are sorted as strings instead of by disk number. I think it should be Data 1, Data 2, Data 3, etc. instead of Data 1, Data 10, Data 11, etc.

-
Couple other suggestions: Disk numbers should probably be in ascending order everywhere in the UI (graphs, checkbox selections). Today it looks like its all sorted as strings which puts things out of order and makes things more difficult to find. It would be really nice to be able to filter the graph with all the drives by model number. I find myself having to cross reference disk numbers with models on the left to be able to filter what I need. This would also be nice for seeing relative performance between drive models.








