




johnsanc
Members
-
Joined
-
Last visited
Everything posted by johnsanc
-
Wow this is fantastic to see someone made a docker container for RomVault. You may want to join the RomVault discord as well for issues with Linux or any other general questions about app usage. Although RV was not specifically created for Linux, many users do use it in various Linux VMs.
-
I have a SMB issue that keeps coming up. Basically I am compressing a file which is streaming out a temp file over the SMB share writing directly to the array. Sometimes I get an error in my log.smbd file that says. smb2_sendfile_send_data: sendfile failed for file XXXXXXXX.zip (Broken pipe) for client ptr=0x5609e59ceec0, id=1, addr:xxx.xxx.x.xxx:xxxxx. Terminating This seems to occur in the middle of compressing, not at the end when the temp file should be renamed to the final name. When this error occurs I cannot delete the temp file from Windows. If i delete the file from the /user/ share on unraid it deletes without issue. However Windows can then no longer write a temp file by the same name. It attempts to and it shows in explorer with 0 size and the modified time of when the last file failed. Shutting down my VM and restarting also does not work. The only thing I found that resolves this issue is to completely restart samba. What is going on here and is there a way to tune SMB to prevent this error?
-
It’s related to memoryBacking. I can reproduce with just that setting and nothing else related to virtiofs
-
No. Something else is the issue then. In my case I formatted the disk on 6.11.5 as NTFS and it could not be read by a Windows PC. Likewise, a Windows PC formatted NTFS drive could not be read by UD on 6.11.5 until it was formatted.
-
I just wanted to add a +1 for the issues related to NTFS drives. I had an 18TB Exos drive formatted as NTFS with Windows that would not display as mountable in UD. Since it was basically empty I formatted as NTFS with UD and copied a bunch of data to it as a backup. This drive mounts and works perfectly fine with Unraid, but when I try to connect it to a Windows PC it appears blank like there is no filesystem. Considering I am the 4th person in the past month to mention this issue with NTFS, it really deserves a closer look to see what is going on with this IMO.
-
Have there been any updates on the freeze issue several people are having whenever memoryBacking is enabled?
-
snolly's freezing issue was clearly unrelated the the freeze issue most of the people in this thread have. Again the freeze that shows no errors, blue screens, or other indication that anything is wrong is related to the presence of memoryBacking in the config XML. It likely has nothing to do with virtio drivers. Hopefully we hear some kind of a response about this on where to go from here, but for now virtio-fs is not feasible for a lot of people simply because it requires memoryBacking.
-
I tried Q35 and i440fx snd the results are exactly the same. If memoryBacking is included a freeze will occur within a few hours.
-
225 solves no relevant issues. According to GitHub 227 should solve permissions problem. I mentioned this in the other topic with a link to the developer comment. I want to reiterate that the freeze occurs for me with every memoryBacking configuration I’ve tried, and has no relation to the presence of the virtiofs configuration in the XML. The freeze occurs even when virtiofs is not used at all. On the windows side everything is perfectly stable and there’s no errors. With the exact same windows setup the freeze will occur whenever memoryBacking is defined. i have no idea what causes this and the logs are useless. If someone has instructions how to turn on better logging I’ll do it. To me this sounds like s lower level bug and isn’t related to virtiofs at all.
-
Just a quick update, the 225 drivers do NOT resolve the permissions issues if the Virtio-FS service is restarted or started manually. It must still be set to automatic to work properly.
-
Confirmed 225 is messed up. I think its related to qemupciserial. I was able to install if I deselected that component. Attempting a manual install errors on that component. I suspect it may be using a self-signed certificate or something. Either way I'm giving it a shot. We shall see shortly if the VM freezes... fingers crossed. EDIT: No luck. 225 drivers have the exact same issue and the VM freezes after about 2 hours if memoryBacking is included.
-
I would suggest a separate post for your issues specifically. This thread is focused on Windows VMs completely freezing (not stuttering) after a few hours on 6.11.1 when trying to use Virtio-FS. Based on my findings so far these freezes are directly related to `memoryBacking` configuration... but no solution yet. Hopefully @SimonF or another developer can help to get this issue into the correct hands.
-
The fix for now is to automatically start the service and do not restart it. Sounds like there's some pretty complicated logic for determining the user that should be ironed out in the next driver release. https://github.com/virtio-win/kvm-guest-drivers-windows/issues/839
-
@SimonF - I was able to get the VM to freeze again with just the memoryBacking config in place. I've attached new diagnostics and my VM XML as well. According to the Windows lock screen the freeze occurred around 1:47 PM ET today. The only thing I see in the logs is something like: 2022-10-16 18:16:12.052+0000: Domain id=5 is tainted: custom-ga-command 2022-10-16 18:17:02.245+0000: Domain id=5 is tainted: custom-ga-command 2022-10-16 18:38:28.779+0000: Domain id=5 is tainted: custom-ga-command Each line only appears when trying to view the log from the VMs tab, or trying to shut down the VM normally. As previously mentioned, the only thing that you can do at this point is force stop the VM. If there is a way to enable better logging I am happy to do so to help troubleshoot. tower-diagnostics-20221016-1438.zip johnsanc_win10vm_q35.xml
-
I'm at my wits end trying to find the best setup for surfacing my shares to my Windows VM. I feel like I've tried everything and every solution falls short. SMB - This works just fine, but the performance is atrocious when working with large directories and many tiny files (which is common for my use case) NFS v3 - This works great and the performance for large directories accessing many small files is orders of magnitude faster than SMB... but does not appear to have UTF-8 support so many of my filenames with Unicode characters can be mangled. NFS v4 - Windows simply doesn't officially support this at all, and I cannot find any client that has decent performance. I tried the one here and it worked, but the performance for large directories was terrible, worse than SMB: http://www.citi.umich.edu/projects/nfsv4/windows/ Virtio-FS - This is apparently bleeding edge and the performance is fantastic, but the memory backing configuration required keeps freezing my VM and no one seems to have a solution for that yet so I can't do much with this until the larger VM freeze issue people are having is resolved. So basically... what do others use and what is the best way to get as much performance as possible for smaller files and large directories?
-
@SimonF - I will try to reproduce that and provide the logs, however they look the same as the ones I provided in my diagnostics. There is nothing useful in the logs when the freeze occurs at all. Is there any way to enable better debug logging to capture info about the freeze? Also can others following this thread also please try just leaving in the memory backing config and NOT any of the virtiofs stuff to see if you also still observe the freeze? <memoryBacking> <source type='memfd'/> <access mode='shared'/> </memoryBacking>
-
i tested with VNC only. Same freeze issue if the standard memory backing portion for virtiofs is included.
-
Virtiofs is CASE SENSITIVE and there is no case insensitive option to use with Windows yet to my knowledge. This could cause issues if code in a game is referring to something.dll, but the file you actually have is something.DLL. Its possible that's what you are running into.
-
I tried that but I cannot even start the VM with that setting. I get the following error in the popup: Unable to write to file /var/log/libvirt/qemu/Windows 10.log: No space left on device It looks like that config instantly filled up all of the space allocated for logs since the dashboard shows Logs: 100%, yet there isn't much in /var/log at all. Had to reboot because I have no idea how to clear out that memory.
-
Well my test seems to narrow the issue down to memory backing. I left this in without any references to the virtiofs and it still froze the exact same way in a similar timeframe. Any ideas on why this would be the case? Or what to try next? <memoryBacking> <source type='memfd'/> <access mode='shared'/> </memoryBacking>
-
I did the same, at the time of the freeze there is no indication anything is awry within Windows. Everything is simply completely frozen. No mouse or keyboard input, but the screen is still with the image of whatever was present at the time of the freeze. Just for the hell of it Im trying to leave memory backing config in place but without any virtio-fs references in the XML. Considering how many people have the exact same issue with this already there must be a pretty big issue somewhere.
-
I spoke too soon. Froze again and CPUs pegged. Also the 0/12 CPU is not allocated to the VM...
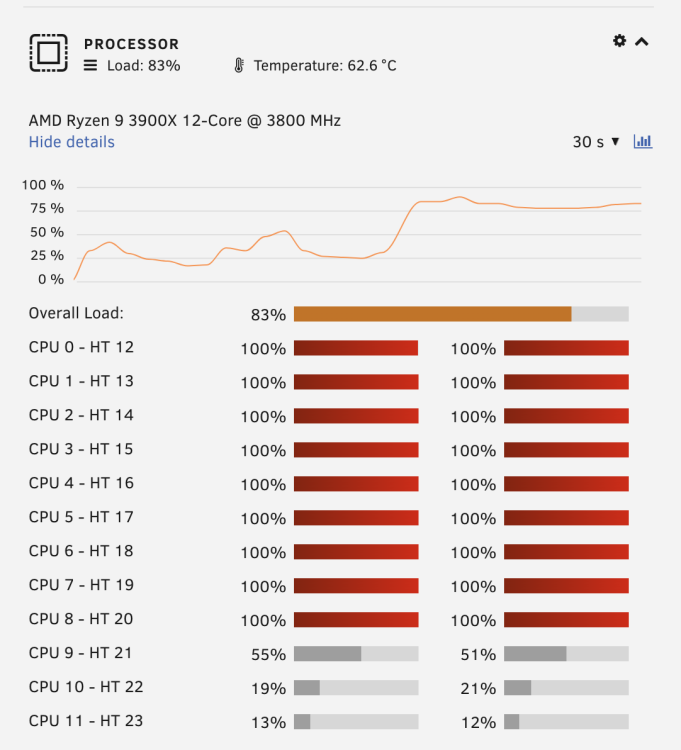
-
Just a quick update - So far so good with 16GB allocated to the VM (25% of my total RAM in the system). The VM has been up longer than it ever has been so far with using virtiofs. @VegChan - Can you share your setup and findings as well so far? I'm curious if you were also using either 32GB+ and/or 50%+ of your system RAM allocated to VM.
-
Here's the basic info of the host machine: M/B: ASRock X570 Creator Version BIOS: American Megatrends Inc. Version P2.40. Dated: 04/13/2020 CPU: AMD Ryzen 9 3900X 12-Core @ 3800 MHz HVM: Enabled IOMMU: Enabled Cache: 768 KiB, 6 MB, 64 MB Memory: 64 GiB DDR4 Multi-bit ECC (max. installable capacity 128 GiB) Network: eth0: 1000 Mbps, full duplex, mtu 1500 Kernel: Linux 5.19.14-Unraid x86_64 And I've attached my VM XML to this post. Note I changed my memory from 32gb down to 16gb because someone else I was chatting with recently mentioned they were having stability issues with anything 32gb and above. So far the VM has been running for about an hour and half with 16gb without any issues yet. I'll let you know how it goes. johnsanc-win10vm.xml
-
Posting here for visibility since it seems like a few people are having issues with VirtioFS and Windows VMs... It looks like the inclusion of virtiofs configuration in the VM XML may result in Windows 10 VM freezes. When this occurs the VM is completely unresponsive and frozen, there is nothing useful in any logs, and all CPUs allocated to the VM become pegged at 100%. Usually this occurs within 30 minutes to 2 hours of the VM being started. I've confirmed that disabling the VirioFS service in windows has no impact on the freezing, nor does I/O load seem to have any impact. Not sure if it matters, but I initially had 32GB of the 64GB of memory I have allocated to the VM.




