nwootton
Members
-
Joined
-
Last visited
Everything posted by nwootton
-
Ended up rolling back to 6.12.4 until the new Dell PERC card was installed. System remained stable with no further issues for the following 2 weeks (29th Feb). Yesterday I installed the new HBA card. Still running 6.12.4 without issues
-
Just ordered Dell PERC H310 for £20. Hoping it will fit my motherboard and can be stop gap until I can source a couple of LSI cards. Probably 9211-8i or later. Will have to see if that solves the issue.
-
Same cards have run for the past x years without an issue - never once dropping a disk. What would cause them to start now? Spin down was turned on after the third failure - though maybe the constant running of disks might be the cause. Was off after the update and subsequent failures. What are the currently recommended alternatives?
-
Going a little nuts here, getting multiple repeating failure scenarios with same disk number, but no actual errors when disks are checked. Background. Recently upgraded to latest version (6.12.6 at time of writing). As part of this I also installed the Fix Common Problems plugin. It flagged 2 issues. I still had 4 reisferfs formatted disks in my box (cache & 3 array drives) Some of my dockers were pointing at a non-array disk (unassigned device). Nothing significant, so upgrade is done. I do need to get rid of the reiserfs before the capability gets removed from the kernel. After some research I followed this method to move data from the reiserfs disks. Using a brand new 4Tb disk, I followed the procedure (rsync in tmux session with web ui to see read & write numbers changing) and got the first disk migrated without issue. I then left the array to ‘settle’ for a couple of days to make sure everything was ok. Went back to do the same with the next disk. At some point the web ui stopped responding and although I could switch between tabs, nothing updated. In the tmux session the rsync was proceeding and after it completed, the web ui still failed to act on commands. Eg I’d request disk spin down and it would indicate it was doing it but then the disk wouldn’t change. Stop array, reboot and shutdown all produced the correct dialogues, but the event wouldn’t happen. I left the web ui open but unused for a while and it remained unhelpful. Opening it in other browsers, forcing cache clear all failed to allow control. Eventually as a last resort I did a shutdown via ssh. I checked all the connections and then rebooted. Server came up and informed me that I no longer had a license key. After multiple reboots the system now agrees that I do still have a valid license and began to work as expected. This leaves me with 2 remaining reiserfs disks I want to migrate. Issue I left the server running for several days and it appeared fine. Then I get a failure in disk4. Array is emulated warning, so I check SMART status and there are no errors. Put the array into maintenance mode and run check disk on the xfs drive. No issues. Run fix anyway. In fact nothing I do indicates an issue with the disk. Swap the disk out for another, parity rebuild takes place (12 hrs) and the new disk is running. Array appears ok. Turn on Docker containers. Next morning, disk4 is in an error state, array is emulated. Run the same SMART and xfs routines and no issues found. Swap the disk out for a third, parity rebuild takes place and array is happy again. Turn on minimum Dockers to keep family happy. Next day, disk4 is again in an error state. No errors in SMART. Check xfs disk, no errors. Run xfs fix anyway again just in case. Nothing done. Replace disk with original disk. Parity rebuild takes place, arrays says it’s happy. Leave all Dockers off. I looked at the ‘failed’ disks on another laptop and still find no errors on them. I’ve run parity read-check to make sure everything agrees. This morning. I get another message that Disk4 is in error state. Logs show read & write errors on disk4 about the time the error message got sent about the array state: ``` .... Feb 14 21:27:16 Tower kernel: md: disk4 read error, sector=1381277744 Feb 14 21:27:16 Tower kernel: md: disk4 read error, sector=1381277752 Feb 14 21:27:16 Tower kernel: md: disk4 read error, sector=1381277760 Feb 14 21:27:16 Tower kernel: md: disk4 read error, sector=1381277768 Feb 14 21:27:16 Tower kernel: md: disk4 read error, sector=1381277776 Feb 14 21:27:16 Tower kernel: md: disk4 read error, sector=1381277784 ... Feb 14 21:27:26 Tower kernel: md: disk4 write error, sector=1381277744 Feb 14 21:27:26 Tower kernel: md: disk4 write error, sector=1381277752 Feb 14 21:27:26 Tower kernel: md: disk4 write error, sector=1381277760 Feb 14 21:27:26 Tower kernel: md: disk4 write error, sector=1381277768 Feb 14 21:27:26 Tower kernel: md: disk4 write error, sector=1381277776 Feb 14 21:27:26 Tower kernel: md: disk4 write error, sector=1381277784 ``` Can anyone suggest something that could explain the repeated failure of different disks in the same allocation? Did the migration process do something that is causing a conflict? Is it something in the current version? Been running unRAID since about version 4 and prior to this all I’ve had is the odd disk failure - something that has been easy to handle. I’ve spent more time dealing with issues in the last 2 weeks than I have in the previous blah years. Now completely out of my depth with an array that no longer works. Update: Hard drives are all 4Tb in size. Original disk4 was WD Red, replaced by Seagate Baracuda, then by Seagate IronWolf. tmux installed via NerdTools tower-diagnostics-20240215-0819.zip
-
@yayitazale Just installed the getting started parrot model detection routine onto my Mac and it runs fine, so it looks like the TPU hasn't failed. https://coral.ai/docs/accelerator/get-started/
-
@yayitazale Power shouldn't be an issue, it's been running fine up until now. No other devices on the USB except the OS - and that is direct onto the motherboard. Neither USB2 or USB3 make any difference to this. I guess it's an issue internal to the docker, rather than unRAID -> docker. Thanks for your help. I'll chase Blake via GitHub/HomeAssistant.
-
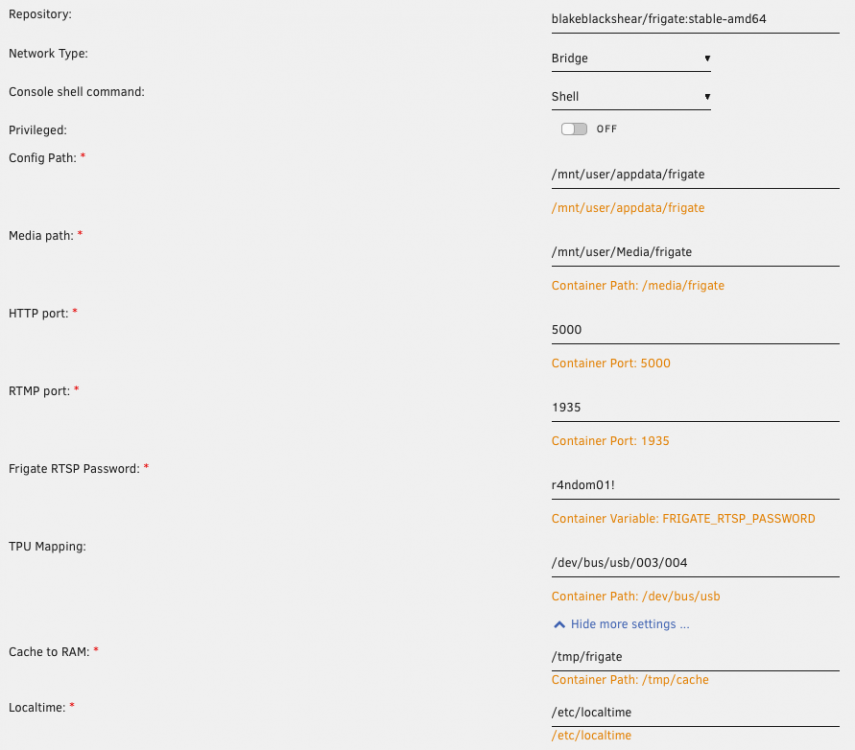
@yayitazale Thanks for that. Changing to privileged made no difference, neither did amending the USB path to use the ' /dev/bus/usb' path. The docker still fails with a python error Fatal Python error: Aborted and this is generally proceeded by this line: F :1150] HandleQueuedBulkIn transfer in failed. Unknown: USB transfer error 1 [LibUsbDataInCallback] The system tells me that the TPU has been detected: detector.coral INFO : Starting detection process: 36 frigate.app INFO : Camera processor started for drive: 39 frigate.app INFO : Capture process started for drive: 40 frigate.edgetpu INFO : Attempting to load TPU as usb frigate.edgetpu INFO : TPU found I've also changed the port that the TPU is plugged into and checked that the LED on it is on.
-
So I've had Frigate running on my unRAID for ages without any issues. Home Assistant on a separate box was connected and working as expected. System is happily using a Corel USB adapter and a single camera. At some point last week, I noticed that the container had stopped and was erroring on re-start. I've made sure that the correct USB is selected for the Corel device, that no GPU has snuck back into the settings and that there's space available. I've now completely wiped the image and settings and started again, but I am still getting the same situation. Frigate starts up, runs for a few minutes and then aborts and shuts down with a python error. Anyone advise? Frigate.log config.yml