




joebot
Members
-
Joined
-
Last visited
-
I couldn't get the xlinix reset to work. I think that might be just for really old devices maybe. Do you think this could somehow be the result of my pihole? Does the radio communicate differently than the other devices for some reason?
-
no, not in a long time. I'll have to check if my credentials are in the server. the radios don't want to connect to that either, but I haven't really tried to connect to it. I'll look into disabling it and I'll also try that reset you mentioned. Thanks guys!!
-
i just noticed that the device doesn't disconnect from the network. It still has an IP and it reports the server's address. However, in the diagnostics menu, it says that it can't connect or ping the servers ports (9000 and the other one). I know that the ports are setup right in the docker and are visible on the network because all my other players can connect just fine. Keep in mind that my SB touch devices are also on wifi and they connect and play just fine, too - so it's not a problem with the AP. It's something specific to the SB radios and their ability to access the ports. also, this is what my AP reports when the radio stops working: Also my AP is on the LTS branch of the ubiquity thingy, hence the older version.

-
Thanks Jademonkey - here's what my settings panel looks like: Only thing that seems interesting is that the tooltip seems to indicate that I should keep the multicast and broadband filtering option disabled:
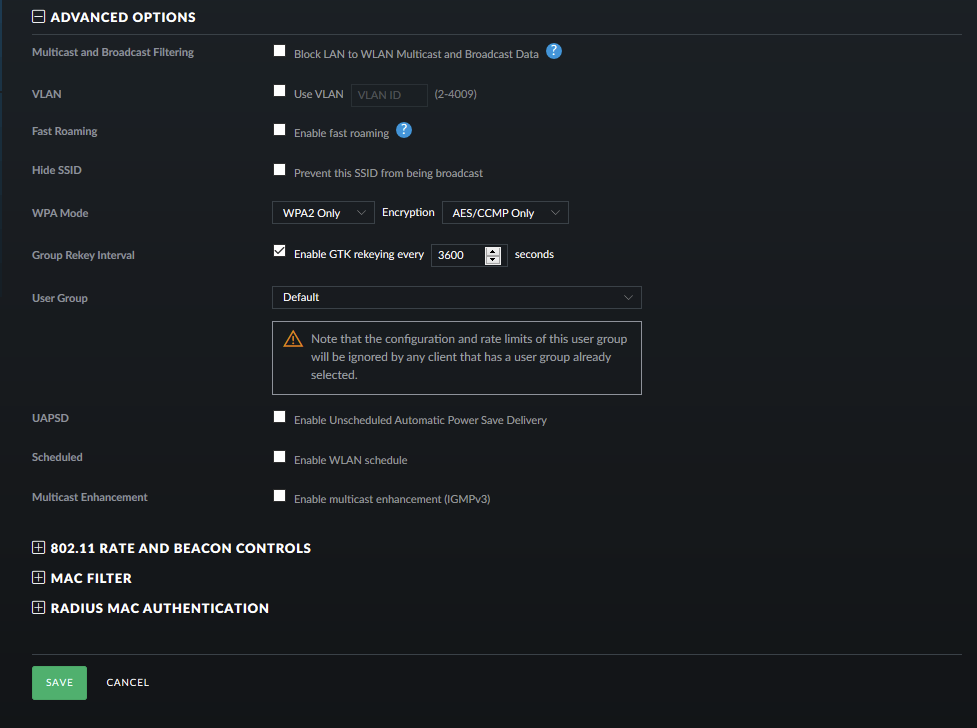
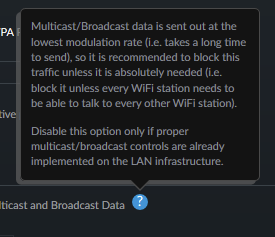
-
Nothing else on my network has an issue like this. I have a lot of wifi and ethernet gadgets that are connected 24/7. Im using a ubiquity unifi AP with a ubiquity router.
-
Both radios are on WIFI. I tried putting one on Ethernet and it worked just fine (for many days without a problem). Turning my radio off and then back on again is the only way to get it to reconnect. After reconnecting, I can get it to play through about half an album's worth of music before the wifi icon turns red and it disconnects. We use one of the radios as a white noise machine for our baby (via the sound effects app). If I power cycle the radio, I can connect to the server long enough for it to let us play the white noise. It plays the noise all the way through the night, but it disconnects at some point. In the morning, I have to power cycle the radio to reconnect for nap time white noise. I think the sound effect app works differently than streaming music, so that's why it plays all night. Not sure if that helps, but I figure that i'd mention it just in case... Im pretty sure this started with an update to the container about two months ago. I have no idea what changed in the update.
-
FWIW, I've confirmed that the Radios are gracefully disconnecting from my network, at least from my AP's point of view. It's like they are happy and cheerfully play music and connect to the server, and then they just decide that they don't like it anymore and leave.
-
No not lately. We recently let Microsoft's time server through pihole... But that's about it. The thing is that our two Logitech Touches and (the one player that is headless but comes with a remote - I forget the name) work just fine. It's only our two Logitech Radios that stop connecting. They will connect just fine for about five minutes after reboot, but then they disconnect. It's making me crazy! I've been trying to get them to work for three weeks now...
-
I've been using this docker for a long time now. I have a bunch of different players. I'm not sure what's changed - maybe a new version of this docker - but all of a sudden my squeezebox radios started disconnecting from my server after about 5 minutes. It seems to only happen with this particular device and only with WiFi. The devices won't reconnect unless I reboot them, and then they connect for about five minutes and stop. I've installed the version checking patch, but that didn't help (maybe I did it wrong?) Just wondering if anyone else has had this problem? Any clues as to what might be going on? If anyone is willing to help me, I will dig my logs out next time I have access and share them.
-
I managed to get my gpu passed through without breaking the web gui, however one of my cpu cores is pegged. Is there a way to force the computations to be GPU-only? My server only has four cores, and I'd rather not impact its primary functionality. Here's my configuration: Thanks for your help!


