slofiend
Members
-
Joined
-
Last visited
-
How do I completely remove the plexpass Docker? I keep trying to do a clean re-install but each time I, Remove (and delete image), and then re-install Plex inherits old config info...I want to wipe out all former traces...any steps on how to do this? I've also gone in through FileZilla and manually deleted the whole binhex-plexpass folder from my appdata, but this didn't seem to help either. Thanks
-
No luck swapping out Prefences files, I'll try a fresh install and see if backing up my PMS folder structure and swapping it back in will work. Thanks.
-
Hello and thanks. I already tried to reinstall. No luck. Editing the container didn't seem to provide any changes either. Unless there is something specific I should edit that I missed. Can you share what your preferences. Xml file looks like? Id like to try and recreate mine.
-
Hello. I had a power outage and my Preferences.xml file was wiped out to 0Kb. I don't have a backup for it (whap waaa, I know). I can't find the format it should be in to rebuild it, or seem to generate a new one. I don't actually know what all is usually contained within it. Can someone share an example of theirs or point me to what I should do to make a new one? Thanks
-
Thanks for the support. I'll mark this as solved for now.
-
Ah good test idea. So the memory issue no longer occurs on 6.9.2, but I think that's becuase the mce errors seem to get logged at a lower verbosity level than in 6.10. Though I still have them. I've attached updated log if that helps at all. May 20 08:23:15 Tower kernel: rcu: Hierarchical SRCU implementation. May 20 08:23:15 Tower kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 6: 8c40004000041152 May 20 08:23:15 Tower kernel: mce: [Hardware Error]: TSC 1bf8e2f6d6 ADDR 43a00c0 MISC 3020034086 May 20 08:23:15 Tower kernel: mce: [Hardware Error]: PROCESSOR 0:506e3 TIME 1653060177 SOCKET 0 APIC 0 microcode e2 May 20 08:23:15 Tower kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 6: 8c40004000041152 May 20 08:23:15 Tower kernel: mce: [Hardware Error]: TSC 1bf8e5b88f ADDR 3347cc0 MISC 3020034086 May 20 08:23:15 Tower kernel: mce: [Hardware Error]: PROCESSOR 0:506e3 TIME 1653060177 SOCKET 0 APIC 0 microcode e2 I don't have another CPU to swap out to see if that fixes it, but it doesn't read to me like a memory error where I just need to move some DIMMs around, so I'm not sure the best way to A/B test this to confirm a fix. Thanks for the help. tower-diagnostics-20220520-0828.zip
-
Thanks for the help, and posting correction. Fair enough. So far as I know, power is fine, the server has been up for months. It's also running through a battery backup and power regulator so it should be quite stable. And I agree it seems like hardware, I'm just not sure how to diagnose which/what hardware is the issue aside from just replacing the CPU (if that is the issue).
-
I have attached diagnostics. I know there are mce errors in the log, but after an upgrade my log memory is maxed out, that didn't happen before. I don't know what to do about the mce errors, if anyone can help me narrow down what the issue might be, I'd be really grateful. I'm hoping correcting that will help reduce the memory utilization. syslog.1.txt tower-diagnostics-20220519-1214.zip
-
Here is the latest output....my log memory is not pinged at 100%... Tower kernel: smpboot: CPU0: Intel(R) Core(TM) i7-6700K CPU @ 4.00GHz (family: 0x6, model: 0x5e, stepping: 0x3) May 18 09:14:57 Tower kernel: mce: [Hardware Error]: Machine check events logged May 18 09:14:57 Tower kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 6: cc44dec000041136 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: TSC 0 ADDR 100190ac0 MISC 3000034086 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: PROCESSOR 0:506e3 TIME 1652890472 SOCKET 0 APIC 0 microcode f0 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: Machine check events logged May 18 09:14:57 Tower kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 6: 8c40004000041152 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: TSC 1bd2a07240 ADDR 302bcc0 MISC 3020034086 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: PROCESSOR 0:506e3 TIME 1652890472 SOCKET 0 APIC 0 microcode f0 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 6: 8c4000400004117a May 18 09:14:57 Tower kernel: mce: [Hardware Error]: TSC 1bd2ace75e ADDR 83e0d8c0 MISC 3936e034086 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: PROCESSOR 0:506e3 TIME 1652890472 SOCKET 0 APIC 0 microcode f0 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 6: 8c40004000041136 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: TSC 1bd2b5632c ADDR 48034c0 MISC 3040034086 May 18 09:14:57 Tower kernel: mce: [Hardware Error]: PROCESSOR 0:506e3 TIME 1652890472 SOCKET 0 APIC 0 microcode f0 This goes on and on....is this a bad CPU maybe?
-
Hello. I have been trying to troubleshoot some mce errors in my logs, while my server seems to be running okay, I would like to fix whatever issue is being identified here. After updating to 6.10 I got some more details now. My log is full of repeating versions of this: May 18 10:07:29 Tower mcelog: Trigger `cache-error-trigger' exited with status 1 May 18 10:07:30 Tower mcelog: CPU 0 on socket 0 has large number of corrected cache errors in Level-3 Instruction May 18 10:07:30 Tower mcelog: System operating correctly, but might lead to uncorrected cache errors soon May 18 10:07:30 Tower mcelog: Running trigger `cache-error-trigger' (reporter: yellow) May 18 10:07:30 Tower mcelog: Offlining CPU 0 due to cache error threshold May 18 10:07:30 Tower mcelog: Offlining CPU 0 failed May 18 10:07:30 Tower mcelog: Offlining CPU 1 due to cache error threshold May 18 10:07:30 Tower mcelog: Offlining CPU 2 due to cache error threshold May 18 10:07:30 Tower mcelog: Offlining CPU 3 due to cache error threshold May 18 10:07:30 Tower mcelog: Offlining CPU 4 due to cache error threshold May 18 10:07:30 Tower mcelog: Offlining CPU 5 due to cache error threshold May 18 10:07:30 Tower mcelog: Offlining CPU 6 due to cache error threshold May 18 10:07:30 Tower mcelog: Offlining CPU 7 due to cache error threshold Thanks for any suggestions! tower-diagnostics-20220518-1008.zip
-
I have attached my diagnostics too. I'd appreciate any suggestions or help. tower-diagnostics-20220517-2057.zip
-
This error has been ongoing for months, it's not new per se. But I is about the only thing in my logs now that's something other then good.
-
No apparant issues with unRaid performance but I would like to find and fix the error. Looking over the log I can't tell what the problem might be. Posting output for any suggestions, thanks in advance. mcelog.txt
-
Diagnostics attached, thanks for the help. tower-diagnostics-20210824-0933.zip
-
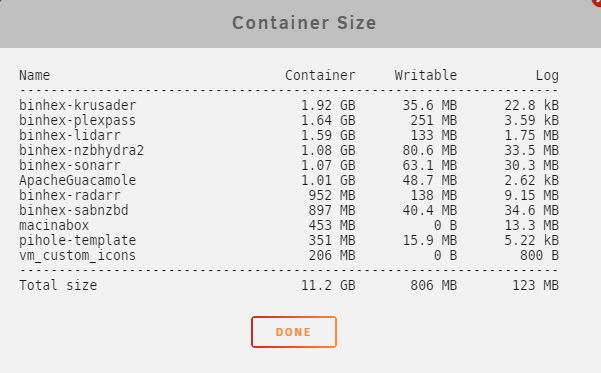
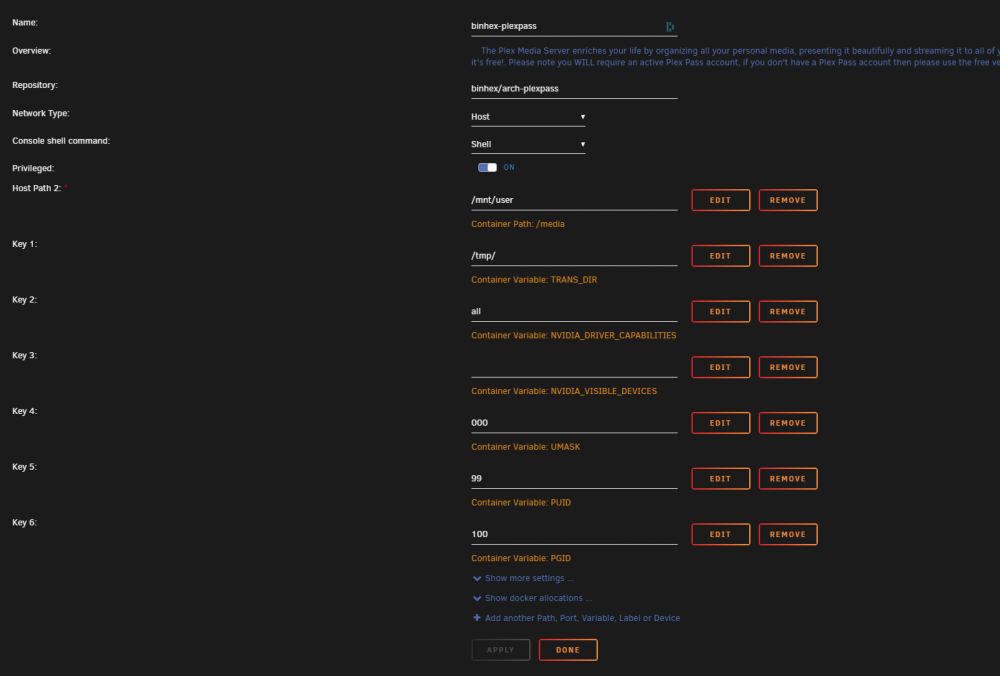
I don't know how to check how big I made the Docker image, but right now it is at 11.2GB. The only Docker I have adjusted recently was Plex, and I think the disk utilization issue might have been with the Key 1 value in Plex. I saw that it can be better to transcode to /tmp so I added the Key 1, but didn't include a forward slash after the /tmp, I updated it now to read /tmp/ maybe that was the issue with the warning?