




Overtaxed
Members
-
Joined
-
Last visited
-
Yes, client was online and connected. It's a real disk (NVME unassigned device). Do you know what that error means? I was thinking maybe MTU on the network?
-
Well, something went wrong last night and I'm trying to figure out what it is. UnRAID went down hard; just froze. I didn't see the console, I just kicked off a reboot and I see a lot of these messages in syslog. Not sure if this has anything to do with iSCSI or not? I've never had UnRAID crash before, so I may be making an association that doesn't exist, I've added a lot to this server, NVME, unassigned devices, a 10Gb NIC.. No way can I point at iSCSI, but since this thread is already rolling, figured I'd start here and see if this might be a place to look: Apr 8 08:41:33 unraid kernel: WRITE_SAME sectors: 2048 exceeds max_write_same_len: 1025
-
Upgrade to 6.9.1 went without a hitch. I was living dangerously and left a server up on the ESX host to see what would happen during the reboot. Froze when UnRAID went down (as expected) and then recovered gracefully as soon as it came back. No loss of state, no reboot on the server, just a freeze and recovery, exactly what VMware should do when it "loses" a LUN. Very nice!
-
See 6.9.1 is out, any specific considerations/concerns about doing an upgrade with the great iSCSI work you guys have done? Just want to make sure I don't blow it up, obviously spin down the VMs and I'll need a reboot, just want to make sure I'm not going to lose the LUNs or iSCSI configuration. BTW, in case anyone is keeping track, running perfectly now for ~2 weeks. Not a hiccup. vMotion works great, and I recently moved everything to 10G, it's rocket fast coming off the NVME in my UnRAID server to the VMware hosts via iSCSI. Works fantastic! Thank you again for the great work on this!
-
So, doing a little more testing, things are still working very well. Not a single blip to my ESX servers, and, even better, I've rebooted UnRAID while a VM was up, using iSCSI and it recovered from that gracefully (VM froze until storage came back, which is what it should do). One thing I've noticed, it appears that the iSCSI traffic all runs on CPU 0. Here's what I'm seeing running an FIO from the VM using an iSCSI disk; 93% utilized on CPU0, everything else pretty much flatlined. Now, the good news, this is pushing 3-4Gb/s of traffic down that iSCSI pipe, not too shabby! Is iSCSI bound to dom0 or restricted from the rest of CPUs (either by design, or perhaps by something I did)?
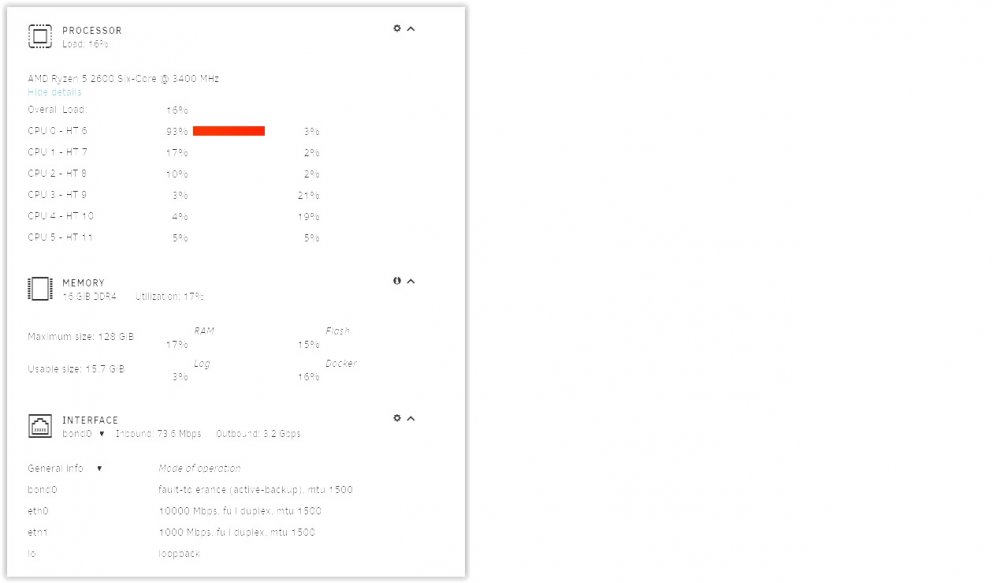
-
Well, the support I'm getting here is lightyears beyond what I get for commercial software, so, while it might be a good idea, you guys are killing it. And thank you for that and this contribution to the UnRAID community! Even if it breaks and takes all the VMs with it, you guys have shown it's doable and I'm sure this functionality will wind up mainstream in the future, that's a huge step forward for all of us idiots doing stuff like running ESX clusters at home.
-
Thanks Simon, looks like that's the one: 0x4d (LOG SENSE), presumably because the Solaris initiator is trying to check for disk errors. Fortunately we are already doing that on the iSCSI backends (well, usually). Not sure exactly how or why ESX is trying to 'check for errors', but I suspect that's what it is. Good news though, despite those errors/warning messages, going into 24 hours with rock solid connection via iSCSI. No drops, vMotion is working fine, VM itself has nothing troubling reported at all. Working very well!
-
Getting a strange message in syslog, any ideas on this one? unraid kernel: iSCSI/iqn.1998-01.com.vmware:esx1-5b059529: Unsupported SCSI Opcode 0x4d, sending CHECK_CONDITION.
-
Honestly, I think your plug-in looks great! The thing I found confusing is what needs to be built in/added to get it working (because this thread goes back to a time before it was in the kernel). It was really dead simple, install 6.9, install plug in, configure, done. That said, I used to admin a large (Netapp) based iSCSI environment, so.. I'm pretty familiar with how all the pieces fit together, target/initiator, LUN, mapping, etc. Certainly would have been harder if I didn't have that experience. I'm running the iSCSI LUN to VMware, and, when I tried this with an RC, I had some issues with disconnects. File based LUN on my cache pool (2 drives) would get random disconnects/freeze ups. I'll see it I have the same issue this time, but, so far, it's rock solid and fast.
-
Seems to be working, and was pretty darn simple (as said, just install the plugin and configure). I'm sure people who want it will figure it out.
-
Now that 6.9 is out in the wild, any chance we can get a walkthrough of setting up iSCSI on it? I did play with iSCSI using an RC, but I saw a few RC's back that iSCSI was now in the kernel, so I'm not sure what actually needs to be done with your plugin vs what's native in UnRAID now. Thank you again, awesome upgrade and add to the community here!
-
I'd love to have this functionality too. I have found it's just not reliable enough, dropped datastores and locked up VMs. No idea if this is VMware's problem or UnRAIDs, but whatever it is, it's not very usable as it sits today for me. I'd be fine with iSCSI or NFS. My concern isn't really speed, but I'd be storing my VMFS/NFS partitions on an SSD mirror cache pool, so I don't really need the speed of multi-disk, a single drive will produce plenty of IOPS for what I need. Any plans/progress on looking at this use case?
-
Unbalancing appdata and system shares away from the user (parity) drives as we speak. I'll update with success/failure after I've had a little time to test.
-
Well, not trying to make this my issue, but hopefully it's related and my diagnostics will lead to a solution for both me and OP. I just pulled this bundle down, mover is running right now. unraid-diagnostics-20190730-1822.zip
-
Overtaxed joined the community
-
Similar problem here (and totally unrelated to Plex). Mover currently running, array CPU is very high and browsing shares very slow. It's moving data around 10MB/s (I've used the CA plugin to lower the priority of mover, which had a major impact on this). However, something still doesn't seem right, it's taking 70-80% of 8 cores to do a move at 10MB/s but I can copy to the array at 150MB/s (directly to the array, no cache drive, turbowrite on) and the CPU usually won't spike above 10%. Putting it another way, I suspect I could put 2 shares on the array, one on the cache drive and one on the protected (no cache) destination and do a copy at 10X the speed with 1/10th the CPU. That makes no sense, because copying from the cache drive (which I can do at 150MB/s) and then back to the array (where I can also write at 150MB/s with turbowrite on) via the network stack should be more costly than doing the same operation internal to the array (it's got to move all the same data, but also do all the TCP work/NFS handles/etc). No reason that should be 100X more computationally intensive to copy internally than to do the same copy over the network. It's no big deal for me, I rarely use this functionality, I just copied in tons of data yesterday and wanted to stage it on the cache drive because I was streaming tons of data in the other direction from the protected shares at the time. But something doesn't feel right about whatever process the mover is using to pick up files from the cache to the protected array. Anyone try copying a huge file to the cache drive and then logging into the array and doing a simple "cp" command into a parity protected user mount point? That would be interesting.

