

Howboys
-
Posts
105 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Howboys
-
-
Okay I've disabled EPC and Low Current Profile on the 3 drives matching that model. After a reboot, disk error count is back to 0. Hopefully this doesn't happen again. Thanks!
-
1 hour ago, JorgeB said:
the errors happened just after spin up.
Oh interesting. For me knowledge, where in the logs do you see that?
Separately, is there any indication that the drive is failing or data on drive is corrupted/at risk? Are the reported errors (78) just a red herring?
-
26 minutes ago, JorgeB said:
See here:
Thanks. Before I try that, I'm curious why you think it's the same issue. My drives don't disappear. Just this one has read errors but unRAID doesn't seem to show what exactly the errors are.
I'm also not sure how/if to rest the error counter.
-
10 hours ago, trurl said:
Run an extended SMART self-test on disk5.
What are all those SSH key exchange errors from WAN IP in your syslog about?
Completed without error.
-
Okay starting a smart test now.
Those errors I think are from tailscale, but I'm not sure exactly why. They're annoying but I've learned to ignore them.
-
Got a notification 2 days ago that disk 5 has 78 read errors. But SMART shows no errors and parity check succeeded finding 0 errors.
Any help please?
-
Fixed by running a balance on cache. Btrfs is a giant pita
-
For the last day or two I've been seeing "No space left on device" in nzbget and qbittorrent (but other containers are working just fine). What happens is that the nzb downloads fully but then fails due to "No space left on device". Or in qbit, part of files download and then Error due to "No space left on device"
I have previously had this happen when my cache was full and re-creating docker.img fixed that. In that case, no docker containers would work. My containers (plex etc) work just fine.
Set up:
- system and appdata are set to use cache_nvme
- Media is set to use cache_ssd
- cache_nvme has never been full
- cache_ssd got 100% full a few days ago
Things I've tried:
- I ran scrub on my disk (nvme cache disk where docker.img is, and cache_ssd where downloads would go first) and it found 0 errors.
- I've re-created docker.img from scratch. No luck.
- I completely removed and then re-installed nzbget (restored settings conf file only). No luck.
- Made sure docker.img is nowhere near full: `/dev/loop2 20G 10G 9.8G 51% /var/lib/docker`
- Made sure downloads directory is not full. Running `df -h` inside the nzbget container shows that `/downloads` has plenty of space left: `shfs 34T 26T 7.7T 77% /downloads`
- nzbget is able to download the files but fails on unrar. So clearly the "No space left on device" is transient.
I'm at a total loss here and would appreciate any help.
Thanks
-
On 9/19/2022 at 10:35 PM, jbartlett said:
Pushed version 2.9.5 to the docker hub. @Howboys - let me know if it resolves your issues with the EOL notice. It's using the latest build of the Lucee app server.
I'm starting to use tagged versions. 2.9.5/latest resolves issues with funky partition output from the "parted" utility. Well, hopefully resolves it as I couldn't duplicate.
If you have issues with the version 2.9.5, change the repository to "jbartlett777/diskspeed:2.9.4" to roll back to the previous version.
Updated and now there's a few more vulns ("HIGH"):
Description The version of Tomcat installed on the remote host is prior to 9.0.43. It is, therefore, affected by multiple vulnerabilities as referenced in the vendor advisory. - When using Apache Tomcat versions 10.0.0-M1 to 10.0.0-M4, 9.0.0.M1 to 9.0.34, 8.5.0 to 8.5.54 and 7.0.0 to 7.0.103 if a) an attacker is able to control the contents and name of a file on the server; and b) the server is configured to use the PersistenceManager with a FileStore; and c) the PersistenceManager is configured with sessionAttributeValueClassNameFilter=null (the default unless a SecurityManager is used) or a sufficiently lax filter to allow the attacker provided object to be deserialized; and d) the attacker knows the relative file path from the storage location used by FileStore to the file the attacker has control over; then, using a specifically crafted request, the attacker will be able to trigger remote code execution via deserialization of the file under their control. Note that all of conditions a) to d) must be true for the attack to succeed. (CVE-2020-9484) - An information disclosure vulnerability exists when responding to new h2c connection requests, Apache Tomcat versions 9.0.0.M1 to 9.0.41 could duplicate request headers and a limited amount of request body from one request to another meaning user A and user B could both see the results of user A's request. (CVE-2021-25122) - when using Apache Tomcat 10.0.0-M1 to 10.0.0, 9.0.0.M1 to 9.0.41, 8.5.0 to 8.5.61 or 7.0.0. to 7.0.107 with a configuration edge case that was highly unlikely to be used, the Tomcat instance was still vulnerable to CVE-2020-9494. Note that both the previously published prerequisites for CVE-2020-9484 and the previously published mitigations for CVE-2020-9484 also apply to this issue. (CVE-2021-25329) - A remote code execution vulnerability via deserialization exists when using Apache Tomcat 9.0.0.M1 to 9.0.41 with a configuration edge case that was highly unlikely to be used, the Tomcat instance was still vulnerable to CVE-2020-9494. Note that both the previously published prerequisites for CVE-2020-9484 and the previously published mitigations for CVE-2020-9484 also apply to this issue. (CVE-2021-25329) Note that Nessus has not tested for this issue but has instead relied only on the application's self-reported version number. Solution Upgrade to Apache Tomcat version 9.0.43 or later. ----------------------- Description The version of Tomcat installed on the remote host is prior to 9.0.63. It is, therefore, affected by a vulnerability as referenced in the fixed_in_apache_tomcat_9.0.63_security-9 advisory. - The documentation of Apache Tomcat 10.1.0-M1 to 10.1.0-M14, 10.0.0-M1 to 10.0.20, 9.0.13 to 9.0.62 and 8.5.38 to 8.5.78 for the EncryptInterceptor incorrectly stated it enabled Tomcat clustering to run over an untrusted network. This was not correct. While the EncryptInterceptor does provide confidentiality and integrity protection, it does not protect against all risks associated with running over any untrusted network, particularly DoS risks. (CVE-2022-29885) Note that Nessus has not tested for this issue but has instead relied only on the application's self-reported version number. Solution Upgrade to Apache Tomcat version 9.0.63 or later. ----------------------- Description The version of Tomcat installed on the remote host is prior to 9.0.40. It is, therefore, affected by multiple vulnerabilities as referenced in the fixed_in_apache_tomcat_9.0.40_security-9 advisory. - When serving resources from a network location using the NTFS file system, Apache Tomcat versions 10.0.0-M1 to 10.0.0-M9, 9.0.0.M1 to 9.0.39, 8.5.0 to 8.5.59 and 7.0.0 to 7.0.106 were susceptible to JSP source code disclosure in some configurations. The root cause was the unexpected behaviour of the JRE API File.getCanonicalPath() which in turn was caused by the inconsistent behaviour of the Windows API (FindFirstFileW) in some circumstances. (CVE-2021-24122) - While investigating bug 64830 it was discovered that Apache Tomcat 10.0.0-M1 to 10.0.0-M9, 9.0.0-M1 to 9.0.39 and 8.5.0 to 8.5.59 could re-use an HTTP request header value from the previous stream received on an HTTP/2 connection for the request associated with the subsequent stream. While this would most likely lead to an error and the closure of the HTTP/2 connection, it is possible that information could leak between requests. (CVE-2020-17527) Note that Nessus has not tested for this issue but has instead relied only on the application's self-reported version number. Solution Upgrade to Apache Tomcat version 9.0.40 or later. ----------------------- Description The version of Tomcat installed on the remote host is prior to 9.0.65. It is, therefore, affected by a vulnerability as referenced in the fixed_in_apache_tomcat_9.0.65_security-9 advisory. - In Apache Tomcat 10.1.0-M1 to 10.1.0-M16, 10.0.0-M1 to 10.0.22, 9.0.30 to 9.0.64 and 8.5.50 to 8.5.81 the Form authentication example in the examples web application displayed user provided data without filtering, exposing a XSS vulnerability. (CVE-2022-34305) Note that Nessus has not tested for this issue but has instead relied only on the application's self-reported version number. Solution Upgrade to Apache Tomcat version 9.0.65 or later.There's more but it seems like these are still present.
-
Just skimming https://www.samba.org/samba/docs/4.15/man-html/smb.conf.5.html, the config in OP should continue to work as in 4.12.
-
M vulnerability scanner just popped up with this for DiskSpeed:
Description
According to its version, the remote web server is obsolete and no longer maintained by its vendor or provider.
Lack of support implies that no new security patches for the product will be released by the vendor. As a result, it may contain security vulnerabilities.Solution
Remove the web server if it is no longer needed. Otherwise, upgrade to a supported version if possible or switch to another server.
Output
Product : Tomcat Installed version : 8.0.53 Support ended : 2018-06-30 Supported versions : 8.5.x / 9.x / 10.x Additional information : http://tomcat.apache.org/tomcat-80-eol.htmlSeems like maybe it's time to upgrade Tomcat?
-
12 hours ago, JorgeB said:
Looks like the first device was still in use when it was disconnected, hence the following problems, rebooting will fix it.
(unrelated to this issue but) I think that might have happened because preclear on USB3 ports seems to not work properly (-110 error code as you can probably see in the diagnostics I attached above). The pre-read happens for a couple of minutes at high speeds and then the device is just disconnected. Doesn't happen on USB2 so it's not the enclosure.
-
2 hours ago, JonathanM said:
Reboot.
That's the only way?
(I'll consider maybe doing preclears on my non-unraid server in the future as well)
-
7 minutes ago, trurl said:
Not recommended to preclear SSDs
Sep 10 04:38:50 Tower sshd[31172]: error: kex_exchange_identification: Connection closed by remote host Sep 10 04:38:50 Tower sshd[31172]: Connection closed by 100.85.179.103 port 39774
Your syslog is spammed with these, any idea what that is about?
sdj doesn't seem to be connected now. Can you connect it some other way?
I believe that's my tailscale network ip.
And I removed sdj. I can connect it through SATA but the whole point of my USB enclosure is to check disk health before I open up my server.
Is there a way to make unRAID "forget" sdj?
-
So I just got a USB enclosure to pre-clear and test drives before I put them in my unraid system. However, I have been unable to get it to work properly of late (the first 2-3 times I used it a month ago, I had no issues).
I tried with a Samsung SSD first:
Sep 11 11:51:56 Tower kernel: usb 4-2: new SuperSpeed USB device number 7 using xhci_hcd Sep 11 11:51:56 Tower kernel: usb-storage 4-2:1.0: USB Mass Storage device detected Sep 11 11:51:56 Tower kernel: usb-storage 4-2:1.0: Quirks match for vid 174c pid 55aa: 400000 Sep 11 11:51:56 Tower kernel: scsi host11: usb-storage 4-2:1.0 Sep 11 11:51:57 Tower kernel: scsi 11:0:0:0: Direct-Access ASMT ASMT105x 0 PQ: 0 ANSI: 6 Sep 11 11:51:57 Tower kernel: sd 11:0:0:0: Attached scsi generic sg9 type 0 Sep 11 11:51:57 Tower kernel: sd 11:0:0:0: [sdj] 937703088 512-byte logical blocks: (480 GB/447 GiB) Sep 11 11:51:57 Tower kernel: sd 11:0:0:0: [sdj] Write Protect is off Sep 11 11:51:57 Tower kernel: sd 11:0:0:0: [sdj] Mode Sense: 43 00 00 00 Sep 11 11:51:57 Tower kernel: sd 11:0:0:0: [sdj] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Sep 11 11:51:57 Tower kernel: sdj: sdj1 sdj2 Sep 11 11:51:57 Tower kernel: sd 11:0:0:0: [sdj] Attached SCSI disk Sep 11 11:52:06 Tower emhttpd: device /dev/sdj problem getting idAnd then a different SSD:
Sep 11 11:56:56 Tower kernel: usb 4-2: new SuperSpeed USB device number 8 using xhci_hcd Sep 11 11:56:56 Tower kernel: usb-storage 4-2:1.0: USB Mass Storage device detected Sep 11 11:56:56 Tower kernel: usb-storage 4-2:1.0: Quirks match for vid 174c pid 55aa: 400000 Sep 11 11:56:56 Tower kernel: scsi host11: usb-storage 4-2:1.0 Sep 11 11:56:57 Tower kernel: scsi 11:0:0:0: Direct-Access ASMT ASMT105x 0 PQ: 0 ANSI: 6 Sep 11 11:56:57 Tower kernel: sd 11:0:0:0: Attached scsi generic sg9 type 0 Sep 11 11:56:57 Tower kernel: sd 11:0:0:0: [sdj] Spinning up disk... Sep 11 11:56:58 Tower kernel: .ready Sep 11 11:56:58 Tower kernel: sd 11:0:0:0: [sdj] 488397168 512-byte logical blocks: (250 GB/233 GiB) Sep 11 11:56:58 Tower kernel: sd 11:0:0:0: [sdj] Write Protect is off Sep 11 11:56:58 Tower kernel: sd 11:0:0:0: [sdj] Mode Sense: 43 00 00 00 Sep 11 11:56:58 Tower kernel: sd 11:0:0:0: [sdj] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Sep 11 11:56:58 Tower kernel: sd 11:0:0:0: [sdj] Attached SCSI disk Sep 11 11:57:02 Tower emhttpd: device /dev/sdj problem getting idI think the problem is that both drives are getting sdj but I'm not sure. Again, I've used this same enclosure with different drives in the past with no issues.
-
Did you ever figure it out? I also can't seem to get USB 3 ports on my mobo working right with the unraid flash drive, keyboard/mouse or a USB 3 HDD enclosure. USB 2 works fine but it's soooo slow.
-
Do i need the `/mnt/fuse/:mnt/borg` mount for the container? Fix Common Problems says borg should not exist in /mnt.
These are the mounts I have:

-
1 hour ago, trurl said:
Sep 5 13:55:38 Tower emhttpd: unclean shutdown detected
Wow didn't know about this. Alright time to tweak shutdown settings (most likely it's just a ssh session that was open from one of my remote cron jobs).
-
Oh weird because I rebooted from the GUI. Should've been clean.
-
Alright rebooting the server has worked (though it started a parity check).
-
That's odd because the disk looks fine from smart. Here's the diagnostics.
I won't reboot for a few more hours in case someone wants me to grab other logs.
-
2 hours ago, trurl said:
Post a screenshot of Main - Array Devices
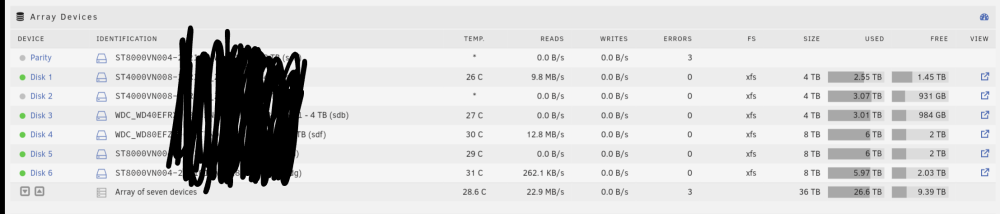
-
Nothing happens when I click the "Clear Stats" button.

-
On the Main page, I see that my parity drive has 3 errors. So I can a parity check with write corrections. It did it and fixed the 3 errors.
Then I ran the party check again, and this time it shows 0 errors.
But the drive still shows the 3 errors on the Main page. Are these actual errors or just leftover state?
How do I get rid of it?


[Plugin] CA Appdata Backup / Restore v2.5
in Plugin Support
Posted
Would love the ability to exclude files based on patterns (like https://github.com/TRaSH-/userScripts-and-Configs/blob/main/scripts/3.Backup-Appdata_Drazzilb/exclude-file.txt).