

Howboys
-
Posts
105 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Howboys
-
-
-
If `/var/log/notify_Discord`, I see failed attempts to send notification but not actual errors or reasons why. Snippet:
Mon Aug 22 06:52:01 PDT 2022 attempt 1 of 4 failed {"embeds": ["0"]}I also don't see further attempts in logs - just 1 of 4 as above for different notifications.
I can do a quick test just fine:
bash /boot/config/plugins/dynamix/notifications/agents/Discord.shAnd I see the notification in Discord.
But when I do a full test:
/usr/local/emhttp/webGui/scripts/notify -e "My Event" -s "My Subject" -d "My Description" -m "My Message" -i "alert" -l "/Dashboard"I only see the notification in the UI and NOT in Discord. Here's the log for that:
Mon Aug 22 07:18:13 PDT 2022 attempt 1 of 4 failed {"embeds": ["0"]} { "content": "<@1234>", "embeds": [ { "title": "My Event", "description": "My Subject", "url": "http://Tower/Dashboard", "timestamp": "2022-08-22T14:18:12.000Z", "color": "14821416", "author": { "icon_url": "https://craftassets.unraid.net/uploads/logos/[email protected]", "name": "Tower" }, "thumbnail": { "url": "https://craftassets.unraid.net/uploads/discord/notify-alert.png" }, "fields": [ { "name": "Description", "value": "My Description\n\nMy Message" }, { "name": "Priority", "value": "alert", "inline": true } ] } ] } -
I'm setting up a discord server for my homelab and with unraid, I'm having some issues.
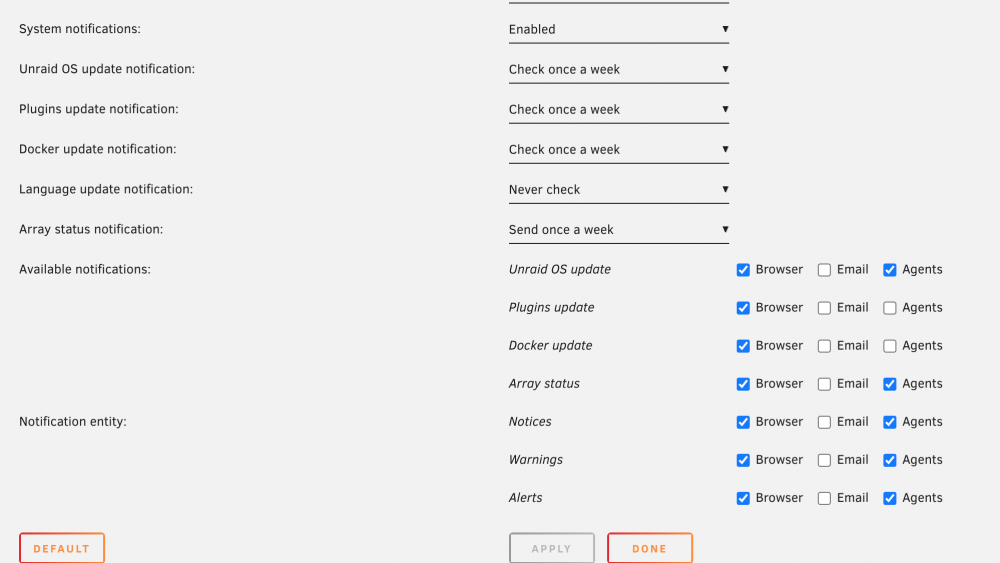
And here's how I've set the Discord agent:
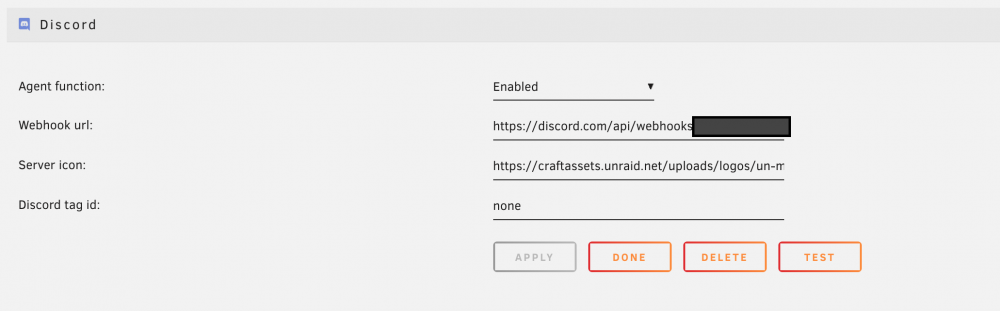
Now, I can receive the test notifications just fine:
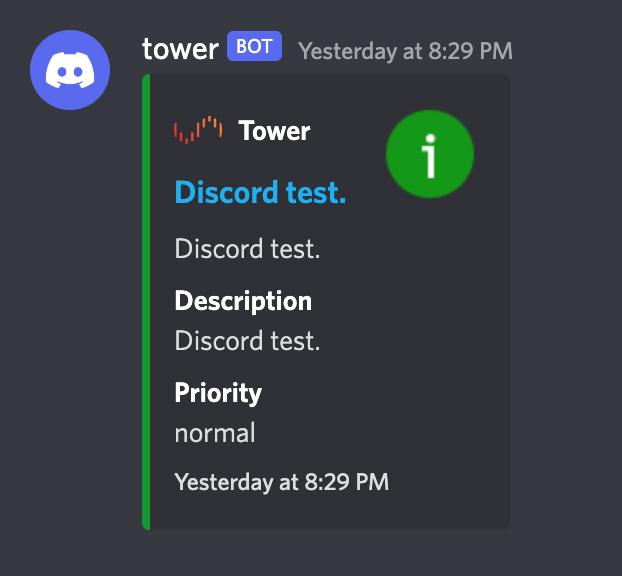
But I'm not receiving any other notifications. I only see notifications in the unraid web ui. Even adding my tag id (the numbers) doesn't work. All I see in syslog is
Aug 22 06:52:01 Tower Discord.sh: Failed sending notificationIs there any way to turn up verbosity of Discord.sh or see why it failed?
-
I think I may have this solved.
I bought a new PSU and new RAM and when I went to replace the PSU, I noticed that my one of my current RAM sticks was not all the way seated. I also noticed that the ATX 24-pin cable was a teeny-bit loose. Anyways, after plugging them in right, my current uptime has been almost 2 days with no hiccups.
If the server stays up for a few more days, I'll upgrade to a bigger case so my SATA power cables aren't pushing against the ATX port (which is what seems to be happening).
Consider this solved (I'll post if I notice issues again).
-
 1
1
-
-
1 hour ago, ich777 said:
Good boot time…
May I ask how often do you reboot your server? I reboot my server very little and even if I do so it is not of a huge deal because I know exactly how long it would take.
No, not by default.
Also please keep in mind that if you are creating such an image you with the drivers preloaded you should be on the version that you want to create a custom image, then you have to pull down the drivers, maybe some build dependencies, compile everything, pack the image again move it to your USB boot device (, hope everything went well so that your system is able to boot) and revoot afterwards.
This process would take about 15 to 20 minutes (<- with recent hardware) depending on the speed of your server.
Also keep in mind that the boot will also take longer, not that much longer as if you create a custom image but I think it will be around 20 to 30 seconds more, because the boot image is bogger and takes longer to load.
Hope that makes all sense to you.
That's all fair and good points.
I don't usually reboot often but when I'm debugging issues (which I've had lately), rebooting a few times a day is common.
Yeah so best case scenario I save 20-30 seconds even if a custom image were possible so perhaps what we have is the best we'll get.
-
1
-
-
10 minutes ago, ich777 said:
The driver is about 300MB in terms of size…
I think one minute for a driver installation is not bad especially on Linux where you have usually have to reboot twice to install it if use the proprietary driver.
Not really, the only way is to not install it. 😅
May I ask why?
It's not a huge deal but without the plugin, my boot is less than a minute. So 2-3x high boot up seems like.. something not ideal.
I know with normal Linux, I could create a preloaded image but idk if unRAID has that option.
-
At boot, it takes nearly a minute for the driver to install:
Aug 18 16:08:45 Tower root: --------------------Nvidia driver v515.57 found locally--------------------- Aug 18 16:08:45 Tower root: Aug 18 16:08:45 Tower root: -----------------Installing Nvidia Driver Package v515.57------------------- Aug 18 16:09:36 Tower kernel: nvidia: loading out-of-tree module taints kernel. Aug 18 16:09:36 Tower kernel: nvidia: module license 'NVIDIA' taints kernel. Aug 18 16:09:36 Tower kernel: Disabling lock debugging due to kernel taint Aug 18 16:09:36 Tower kernel: nvidia-nvlink: Nvlink Core is being initialized, major device number 243 Aug 18 16:09:36 Tower kernel: Aug 18 16:09:36 Tower kernel: nvidia 0000:06:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=io+mem Aug 18 16:09:36 Tower kernel: NVRM: loading NVIDIA UNIX x86_64 Kernel Module 515.57 Wed Jun 22 22:44:07 UTC 2022 Aug 18 16:09:36 Tower root:Is there any way to speed this up?
-
On 8/15/2022 at 7:49 AM, JorgeB said:
Then and since nothing relevant was logged it's likely some hardware issue, one thing you can try is to boot the server in safe mode with all docker/VMs disable, let it run as a basic NAS for a few days, if it still crashes it's likely a hardware problem, if it doesn't start turning on the other services one by one.
So I'm now in basically a crash loop - every 20 minutes or so the server just crashes and restarts (though the original symptom of the nvme SSD missing is not present anymore).
Do you have any idea what hardware might be the issue? Could it be the RAM or the CPU or something else given the symptoms?
-
Did you ever figure this out @unRaide?
-
From
> "Share cache full" means the share to where you are transferring his hitting the minimum free space setting, for that share, not cache, so the transfer would bypass your cache device and go directly to the array
That does seem to be the case. One of my shares has "Minimum free space" set to 200GB:

I don't understand what the logic is here for cache and cache bypass, and why it would cause a server crash.
-
It happened again and here's the logs:
Aug 16 19:51:52 Tower shfs: share cache full Aug 16 19:51:53 Tower shfs: share cache full Aug 16 19:51:53 Tower shfs: share cache full Aug 16 19:51:53 Tower shfs: share cache full Aug 16 19:51:53 Tower shfs: share cache full Aug 16 19:51:53 Tower shfs: share cache full Aug 16 19:51:55 Tower shfs: share cache full Aug 16 19:51:55 Tower shfs: share cache full Aug 16 19:51:55 Tower shfs: share cache full Aug 16 19:51:55 Tower shfs: share cache full Aug 16 19:51:55 Tower shfs: share cache full Aug 16 19:53:03 Tower kernel: Linux version 5.15.46-Unraid (root@Develop) (gcc (GCC) 11.2.0, GNU ld version 2.37-slack15) #1 SMP Fri Jun 10 11:08:41 PDT 2022 Aug 16 19:53:03 Tower kernel: Command line: BOOT_IMAGE=/bzimage rcu_nocbs=0-15 initrd=/bzroot Aug 16 19:53:03 Tower kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers' Aug 16 19:53:03 Tower kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers' Aug 16 19:53:03 Tower kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers' Aug 16 19:53:03 Tower kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256Cache is definitely not full (which seems to have caused the crash?):

Attaching diagnostics.
-
So I was just double checking my config for unraid and noticed that I had not added `rcu_nocbs=0-15` to the append line but instead on a new line. I've now added it to the append line, so hopefully that fixes it?

The other change I've made is to enable global C-states but disable C6 using zenstates in /config/go.

If after all that the server crashes, I'll disable global C-states and see if that does it.
I'm pretty confident that correctly applying `rcu_nocbs=0-15` will resolve this but only time can tell.
-
Hey. Did this permanently resolve your issue? Even with c-states disabled, mine crashes. So now I'm testing it with c-states enabled.
-
I guess it could be my memory though I'm not sure.
According to BIOS it's running at 2133Mhz (though it is 3000Mhz) and I've got 2 sticks in the 2nd and 4th slot away from the CPU. According to the Internet, that should be the right configuration?



-
Just to check in - has it been stable since?
-
I should've mentioned I've already done all that when I built the server.
-
Ok it happened just now. Here's the syslog around the time of the crash (11:36 local time).
What's not in the file attached is what's right before:
Aug 14 11:28:52 Tower kernel: docker0: port 1(veth63b1366) entered blocking state Aug 14 11:28:52 Tower kernel: docker0: port 1(veth63b1366) entered disabled state Aug 14 11:28:52 Tower kernel: device veth63b1366 entered promiscuous mode Aug 14 11:28:53 Tower kernel: eth0: renamed from veth2a1387c Aug 14 11:28:53 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth63b1366: link becomes ready Aug 14 11:28:53 Tower kernel: docker0: port 1(veth63b1366) entered blocking state Aug 14 11:28:53 Tower kernel: docker0: port 1(veth63b1366) entered forwarding state Aug 14 11:29:19 Tower sshd[27775]: Connection from $ANOTHER_LOCAL_MACHINE_IP port 34804 on $UNRAID_IP port 22 rdomain "" Aug 14 11:29:19 Tower sshd[27775]: error: kex_exchange_identification: Connection closed by remote host Aug 14 11:29:19 Tower sshd[27775]: Connection closed by $ANOTHER_LOCAL_MACHINE_IP port 34804 Aug 14 11:30:19 Tower sshd[29895]: Connection from $ANOTHER_LOCAL_MACHINE_IP port 35046 on $UNRAID_IP port 22 rdomain "" Aug 14 11:30:19 Tower sshd[29895]: error: kex_exchange_identification: Connection closed by remote host Aug 14 11:30:19 Tower sshd[29895]: Connection closed by $ANOTHER_LOCAL_MACHINE_IP port 35046 Aug 14 11:31:19 Tower sshd[31937]: Connection from $ANOTHER_LOCAL_MACHINE_IP port 35272 on $UNRAID_IP port 22 rdomain "" Aug 14 11:31:19 Tower sshd[31937]: error: kex_exchange_identification: Connection closed by remote host Aug 14 11:31:19 Tower sshd[31937]: Connection closed by $ANOTHER_LOCAL_MACHINE_IP port 35272 Aug 14 11:32:19 Tower sshd[1650]: Connection from $ANOTHER_LOCAL_MACHINE_IP port 35494 on $UNRAID_IP port 22 rdomain "" Aug 14 11:32:19 Tower sshd[1650]: error: kex_exchange_identification: Connection closed by remote host Aug 14 11:32:19 Tower sshd[1650]: Connection closed by $ANOTHER_LOCAL_MACHINE_IP port 35494 Aug 14 11:33:19 Tower sshd[3711]: Connection from $ANOTHER_LOCAL_MACHINE_IP port 35720 on $UNRAID_IP port 22 rdomain "" Aug 14 11:33:19 Tower sshd[3711]: error: kex_exchange_identification: Connection closed by remote host Aug 14 11:33:19 Tower sshd[3711]: Connection closed by $ANOTHER_LOCAL_MACHINE_IP port 35720 Aug 14 11:36:19 Tower kernel: Linux version 5.15.46-Unraid (root@Develop) (gcc (GCC) 11.2.0, GNU ld version 2.37-slack15) #1 SMP Fri Jun 10 11:08:41 PDT 2022 Aug 14 11:36:19 Tower kernel: Command line: BOOT_IMAGE=/bzimage initrd=/bzrootFrom what I can tell, there's basically no logs preceeding the crash that are useful. The logs I've attached seem to be corresponding to the server re-boot after the crash.
So, what else can I provide or enable for more visibility?
Just to provide more info:
- My build is Gigabyte B450 Aorus M (Bios F63a), Ryzen 7 1700X
- I've already run memtest and made sure the memory is okay (did the memtest when I got the RAM a month or so ago)
- I have `rcu_nocbs=0-15` added to my flash config (https://forums.unraid.net/topic/61129-ryzen-freezes/)
- I'm not running any VMs, just Docker container and storage shares
- There's no significant load on the server at the time of the crash. In fact, things are totally fine any time I do a cpu or GPU stress test.
-
Ok it happened again last night but I didn't have syslog server enabled then (the server didn't restart itself though the PC's power light was on, and disks were spinning. No output/signal on the monitor).
I've enabled syslog server now.
-
So over the last 24 hours or so, it seems like my server is just crashing.
I have no idea why. Once it crashed and rebooted in the middle of the night, and once just a few mins ago.
In both cases, when it started back up, the nvme cache drive was missing (probably due to it being in a bad state after an unclean shutdown). Rebooting didn't help but clean shutdown + start up does. When it crashed a few mins ago and restarted back up, I grabbed the attached diagnostic report (but didn't do a shutdown so my cache only has one SSD now).
I'm not really pushing the limits of my server or anything, so idk why it's been restarting.
-
On 7/14/2022 at 10:17 AM, bdillahu said:
I've been using the new tailscale ssh feature (works great), and ran into something with the docker on unRaid that I don't quite understand.
If I start tailscale up with the ssh flag, it starts. But when I connect to the IP for my unRaid server (where the docker is running), I am put in a session "inside" the docker, not inside the unRaid OS.
I kind of see why, but I'm not sure how to change things so that I get more of what I'm expected.
Anybody have a suggestion?
Thanks!
Wondering the same. I doubt a container allowing full unrestricted access to the host system is a good idea though because that could easily be abused and might be a pretty bad CVE.
In that case, maybe we should install tailscale on the host in unRAID? Maybe with user scripts or something?
-
1
-
-
19 hours ago, JonathanM said:
How long are you waiting after the container is started? I've noticed an extended startup time needed, sometimes close to a minute or more.
Just tried again and waited 7 minutes and same result. This is all I see in the logs:
2022-07-18 22:07:36.185241 [info] System information Linux 757f3f29298e 5.15.46-Unraid #1 SMP Fri Jun 10 11:08:41 PDT 2022 x86_64 GNU/Linux 2022-07-18 22:07:36.213199 [info] OS_ARCH defined as 'x86-64' 2022-07-18 22:07:36.244516 [info] PUID defined as '99'EDIT: I let the container sit overnight and now the UI works fine. So it takes somewhere between 7 minutes and 9 hours for the container to be fully functional.
")
-
On 7/15/2022 at 10:03 PM, ich777 said:
These are two times the same things that you‘ve wrote…
This is the first time that I hear from such an issue that is related to TPM in general.
I know that CSM disabled and booting with UEFI can cause issues with the Nvidia driver but never heard of TPM causing such issues.
EDIT: From what I saw from your syslog it seems like it never did load the module, but I think the Diagnostics from a boot with UEFI instead of a Legacy boot (CSM)?
Yup. The first time I tried it, I may not have deleted the driver entirely. The next time I tried it with a fresh install, it ended up working.
However, then I took my new build and tried to boot up with my main server's boot USB and it wouldn't do it. So I had to enable CSM Support (Secure Boot, TPM, fTPM disabled though, didn't try enabling them).
-
I'm trying to set this up and after 2 clean installs, I just cannot seem to make this work. There are no errors or logs that would be useful but I can't connect using WebUI button:
```
This site can’t be reached
<internal IP? refused to connect.
```
None of my other containers are using 6080 port.
Anyone else seen this and how do I fix this?
-
I'm setting up a new unraid instance with this plugin and can't seem to fix this issue: on server reboot, the GPU doesn't show up in the plugin (but it does show up in system devices).


Attached diagnostics.
On boot, I see the following in the logs on screen (but not in syslog -- so this may be a red-herring):
```
modprobe: FATAL: Module nvidia not found in directory /lib/modules/5.15.46-Unraid
```
I have uninstalled and re-installed the plugin three times now because it keeps breaking on reboot.
While I do use pihole for DNS, it's not blocking github:

In fact, no DNS queries from `testtower` are blocked.
For my BIOS, I have CSM disabled, Secure Boot disabled, fTPM disabled, TPM 2.0 disabled. I've tried with all combinations of enabling these (except secure boot of course) with no luck.
Any help would be appreciated.
UPDATE:
I tried once more after deleting the plugin, restarting and ensuring the following: CSM disabled, Secure Boot disabled, fTPM disabled, TPM 2.0 disabled. It seems to have worked now. Do I really need to keep TPM and fTPM disabled for this plugin?














Not sending Discord notifications (Test works)
in General Support
Posted
Ah that fixed it! I actually have Fix Common Problems plugin installed already but I didn't see it there (or get notified of it).