




raf802
Members
-
Joined
-
Last visited
-
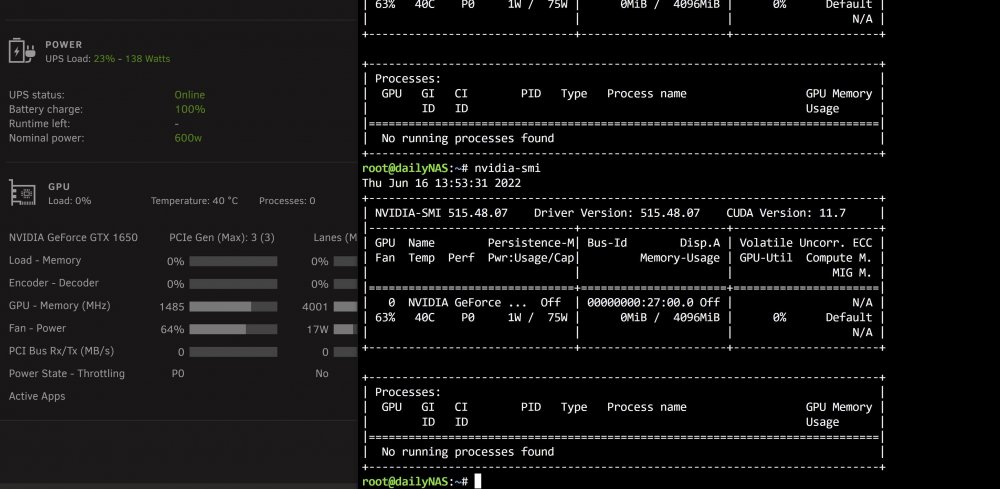
As a "start from scratch" approach. I removed the nvidia-persistenced command from the go file. The docker containers all start up correctly with the GPU. Of course, they are in powestate P0, and I am trying to save power. Do you mind elaborating on the following code? nvidia-persistenced sleep 5 kill $(pidof nvidia-persistenced) Would this also put the container GPU into the P8 powerstate? Can it also go into P0 when needed and back to P8? Some observations I have noticed with power save off (no commands run): GPU is in P0 state. Both nvidia-smi & GPU statistics plugin state the same. nvidia-smi states power usage of 1W, GPU statistics reports 17W. Is this discrepancy normal? Could nvidia-smi be reporting the incorrect power usage for P0, and hence P8 is <1W and causes an error? For reference, when in P8, the GPU uses 7W according to GPU statistics. When I run the nvidia-persistenced command from the cli, the nvidia-smi power usage reports correctly for P0 and then reports the correct P8 state too. dailynas-diagnostics-20220616-1206.zip
-
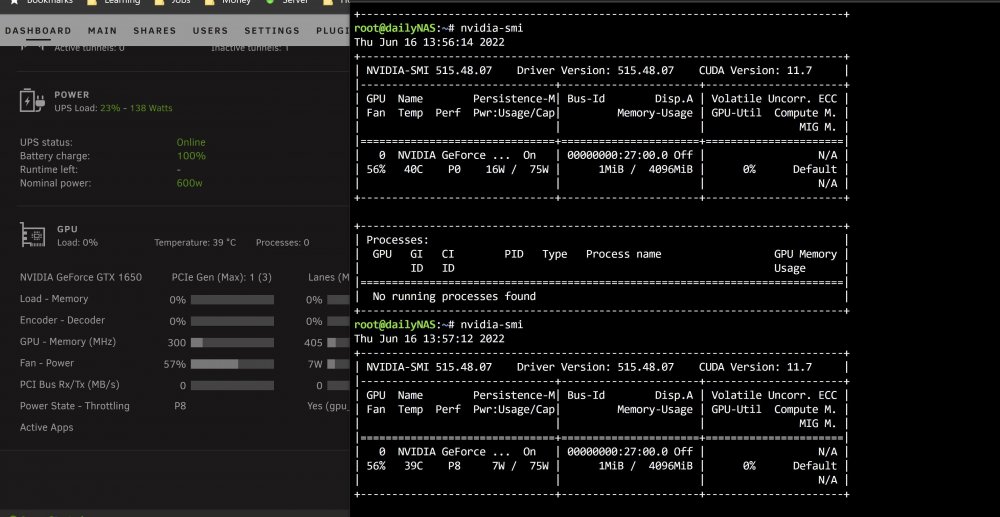
I think I spoke too soon.... I noticed today that the issue has come back. Again, plex was working fine and used the GPU for transcoding. I only noticed the issue because another docker container that was to use the GPU failed to compile / run. In the attached setup, I have "nvidia-persistenced" in the go file and no custom scripts running. Here is the diagnostics file. dailynas-diagnostics-20220616-1206.zip
-
Thanks. I have bound the second card to vfio. Can't remember why it wasn't to begin with tbh. Is there a way of putting the VM GPU in a low power P8 state when not in use (VM on) and when the VM is off? I have also updated the OS to 6.10.3, which upgraded the GPU drivers to v515 automatically. They are working fine still and my issue is resolved. Thank you ich777!
-
I have a second GPU set to be used in the VM. Nothing is bound to vfio on boot and these VMs are off. In short, no it is not used by VMs. Ok, I'll do that, thank you.
-
Thank you again Ich. I disabled that powersave script and everything is working after the reboot. The GPUs are idling in power state P0. When I was getting the issue, their power state was P8. I will upgrade the OS and drivers to see if the GPUs keep working.
-
Thank you for your quick reply! This is the script from Spaceinvader One. I added after the issue originally occurred. Here are the contents: #!/bin/bash # check for driver command -v nvidia-smi &> /dev/null || { echo >&2 "nvidia driver is not installed you will need to install this from community applications ... exiting."; exit 1; } echo "Nvidia drivers are installed" echo echo "I can see these Nvidia gpus in your server" echo nvidia-smi --list-gpus echo echo "-------------------------------------------------------------" # set persistence mode for gpus ( When persistence mode is enabled the NVIDIA driver remains loaded even when no active processes, # stops modules being unloaded therefore stops settings changing when modules are reloaded nvidia-smi --persistence-mode=1 #query power state gpu_pstate=$(nvidia-smi --query-gpu="pstate" --format=csv,noheader); #query running processes by pid using gpu gpupid=$(nvidia-smi --query-compute-apps="pid" --format=csv,noheader); #check if pstate is zero and no processes are running by checking if any pid is in string if [ "$gpu_pstate" == "P0" ] && [ -z "$gpupid" ]; then echo "No pid in string so no processes are running" fuser -kv /dev/nvidia* echo "Power state is" echo "$gpu_pstate" # show what power state is else echo "Power state is" echo "$gpu_pstate" # show what power state is fi echo echo "-------------------------------------------------------------" echo echo "Power draw is now" # Check current power draw of GPU nvidia-smi --query-gpu=power.draw --format=csv exit It affects any container that I try to pass a GPU to. I have tried other plex/emby/jellyfin containers which I have never used and they too had the issue. Please see attached
-
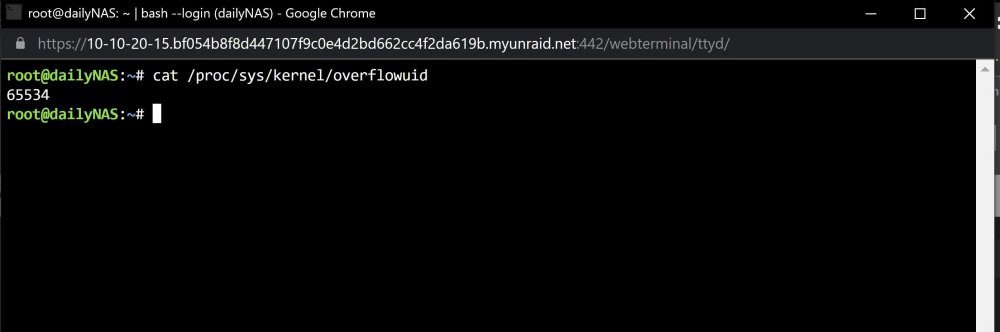
Hi, I noticed that my containers which have GPUs passed through fail to restart after a CA auto-update this morning (15/06/22). One container which didn't stop during the night "appeared" to be working but was not transcoding a queued video. When I restarted this container manually I got the same error below. The error I get when starting any GPU-passed container is a "Bad parameter" pop-up. When I edit the container config to see the compile error I get this: docker: Error response from daemon: failed to create shim: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: initialization error: open failed: /proc/sys/kernel/overflowuid: permission denied: unknown. I have the nvidia-driver plugin installed and have reinstalled most versions of the drivers, from v470.94 to v515.43.04. nvidia-smi shows my GPUs and the driver version correctly. I am not sure what the cause of the error is, if its docker, the nvidia plugin, etc. I noticed this issue occurring since upgrading the unraid OS from 6.9 to 6.10 (which included a nvidia driver update). I have tried: a fresh docker.img, with previously configured container templates redownloaded. restoring the appdata folder from a backup. Checking GPU usage. Only the containers are set up to use the GPU (I even tried with a single container). I also made sure not to use the OS GUI mode. Currently nothing is using the GPU, according to nvidia-smi. Downgraded the OS from 6.10.2 to 6.10.1. Here is the diagnostics file (had to use cmd line as GUI method doesn't do anything). Any help will be greatly appreciated. dailynas-diagnostics-20220615-0956.zip
-
I also have this issue with tdarr_node and plex; or any container with a GPU passed through. I have no idea of the cause other than OS and driver update. I have rolled back both to no avail.



