jaso
Members
-
Joined
-
Last visited
Everything posted by jaso
-
@amapo Nice work. Another request for you to create a fork for Unraid of your version. :-)
-
Hi folks, [Edit = It turns out I am dumbass and got my two licence keys mixed up. Nothing to see here] Cheers, Jaso
-
Update: Replaced data cables for disk6 executed a xfs repair on Disk6 from Unraid UI, which took about 5 minutes repair went pretty good - there were only a handful of files that were placed in lost+found folder, which took about 20 minutes of renaming and moving. Question: Can I trust the parity status or do I need to redo parity?
-
Thanks JorgeB - will do. I did a parity check the other day and it makes my components run HOT and I always get a lot of ATA errors. I usually prop up a fan to the server when that happens but forgot to do it this time. (The irony is that I ordered new kit lat week (mobo, CPU, ram, case, PSU, HBA, etc.) to migrate my drives into a new Unraid host. They are sitting in the courier depots and will probably arrive tomorrow.)
-
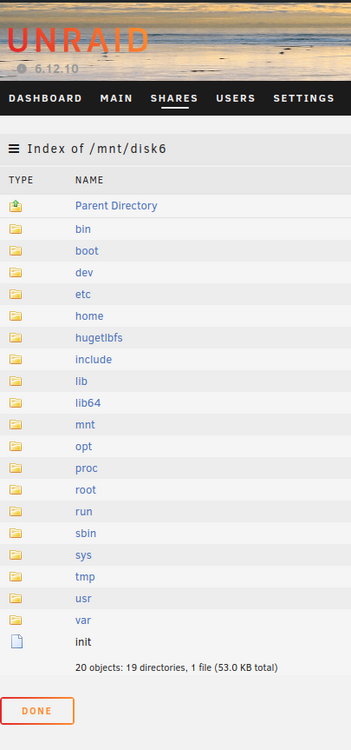
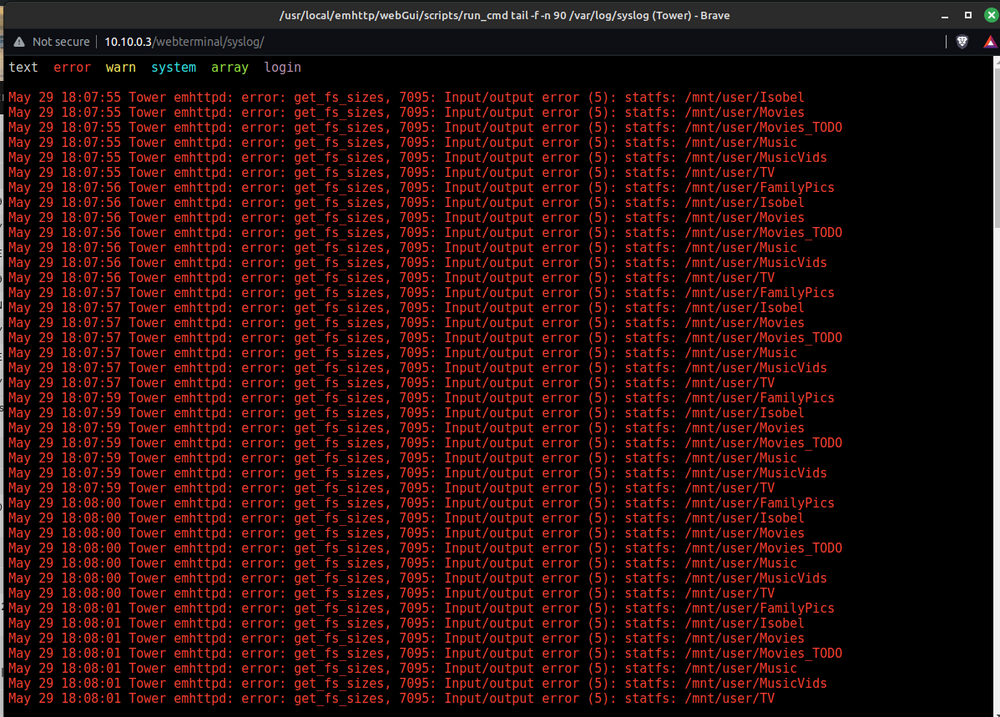
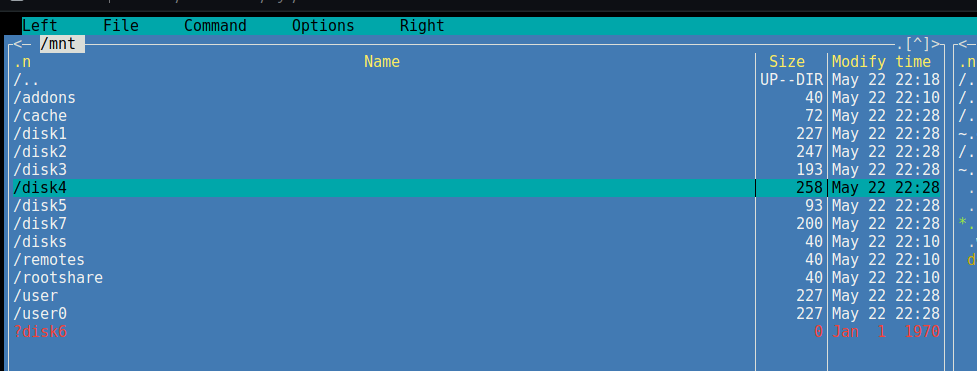
I just fired up Plex to watch a few TV shows and noticed that large chunks of TV episodes were missing. When I had a look at my Unraid server I noticed that Disk 6 is acting really strange. I've had a few disks die on me, but I've never had this happen. In the Unraid UI the file contents of disk 6 - rather than listing my shares - seems to be listing the contents of the underlying OS root! This can't be good. When I bring up a terminal window and use mc tolist the contents of /mnt everything appears AOK except for disk6 which is listed in red and has a question mark in front of it! When I double-click on "disk6" mc states "Error: Cannot read directory contents" This can't be good. I am crossing fingers, hoping that if I do a reboot my Disk 6 will magically re-appear... My syslog looks like this: I have dumped the diagnostics file. Looking at syslog1.txt I can see lines like this: May 28 18:24:37 Tower kernel: XFS (md6p1): Corruption detected. Unmount and run xfs_repair I just watched SpaceInvader One's video "How to fix XFS File System Corruption on an Unraid Server" and I am starting to feel a little bit better. Before I commit to the XFS repair I was hoping the Unraid brains trust could chime in and let me know if I am heading in the right direction? Cheers, Jaso tower-diagnostics-20240529-1811.zip
-
Solved by rolling back t previous version, by changing the template entry for 'repository' from linuxserver/sickchill to linuxserver/sickchill:2024.3.1-ls192
-
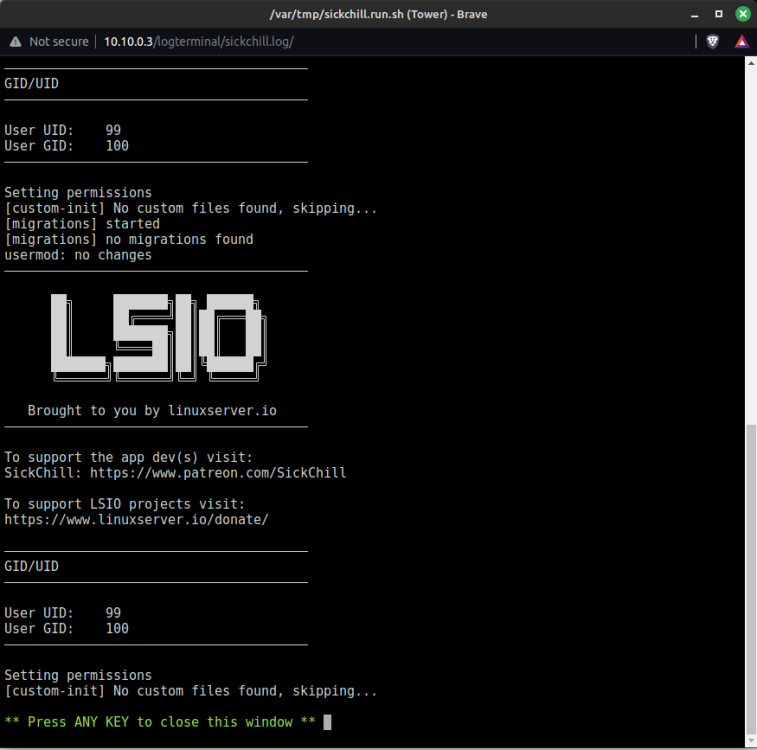
Like the title says, sickchill won't start since the last sickchill update. I have updated Unraid from 6.12.9 to 6.12.10, but it still won't start. The following errors where appearing in my Unraid syslog, before and after the upgrade of Unraid. I have confirmed the errors are sourced from sickchill by starting and stopping each docker. The errors only appear when sickchill is started (and stop when sickchill is stopped): Apr 9 20:57:32 Tower kernel: traps: python3[11080] trap invalid opcode ip:15276047f14e sp:7ffc5821ba10 error:0 in etree.cpython-311-x86_64-linux-musl.so[15276044d000+32a000] Apr 9 20:57:34 Tower kernel: traps: python3[11220] trap invalid opcode ip:148d0ee7f14e sp:7ffd670c8300 error:0 in etree.cpython-311-x86_64-linux-musl.so[148d0ee4d000+32a000] Apr 9 20:57:38 Tower kernel: traps: python3[11325] trap invalid opcode ip:14c0dca7f14e sp:7ffec052d360 error:0 in etree.cpython-311-x86_64-linux-musl.so[14c0dca4d000+32a000] Apr 9 20:57:42 Tower kernel: traps: python3[11418] trap invalid opcode ip:146ccec7f14e sp:7ffdcacc9050 error:0 in etree.cpython-311-x86_64-linux-musl.so[146ccec4d000+32a000] Apr 9 20:57:45 Tower kernel: traps: python3[11550] trap invalid opcode ip:14d71687f14e sp:7ffe90072fc0 error:0 in etree.cpython-311-x86_64-linux-musl.so[14d71684d000+32a000] Apr 9 20:57:48 Tower kernel: traps: python3[11640] trap invalid opcode ip:14a154e7f14e sp:7fffe7b38550 error:0 in etree.cpython-311-x86_64-linux-musl.so[14a154e4d000+32a000] I have attached screenshots of: * unraid logs * sickchill docker settings * sickchill logs I am assuming it's probably some silly config setting I am neglecting, but I just can't figure it out. I would be great if someone can point me in the right direction. Cheers, Jaso
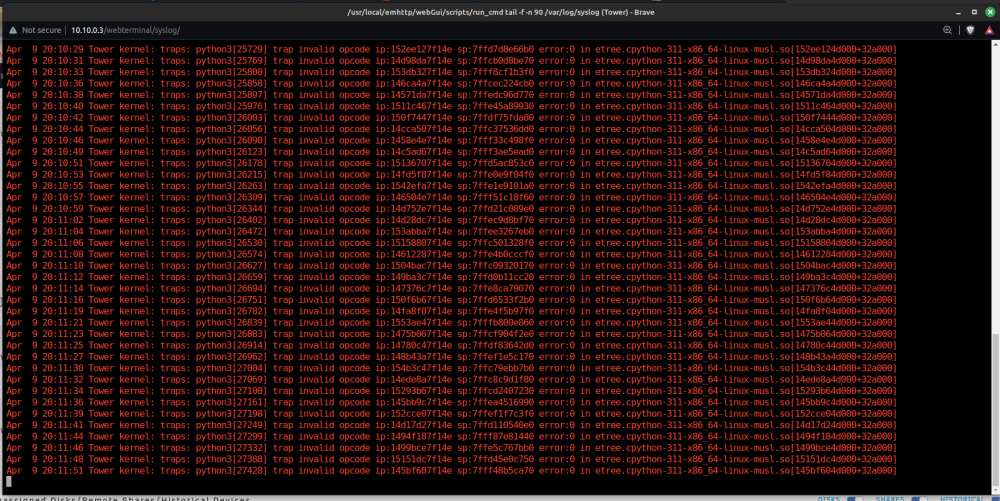
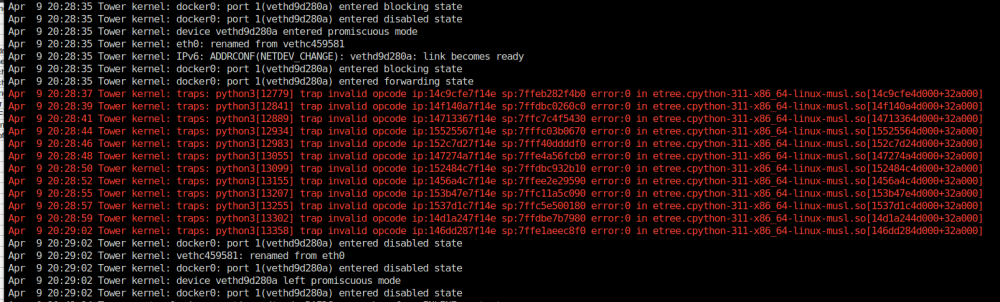
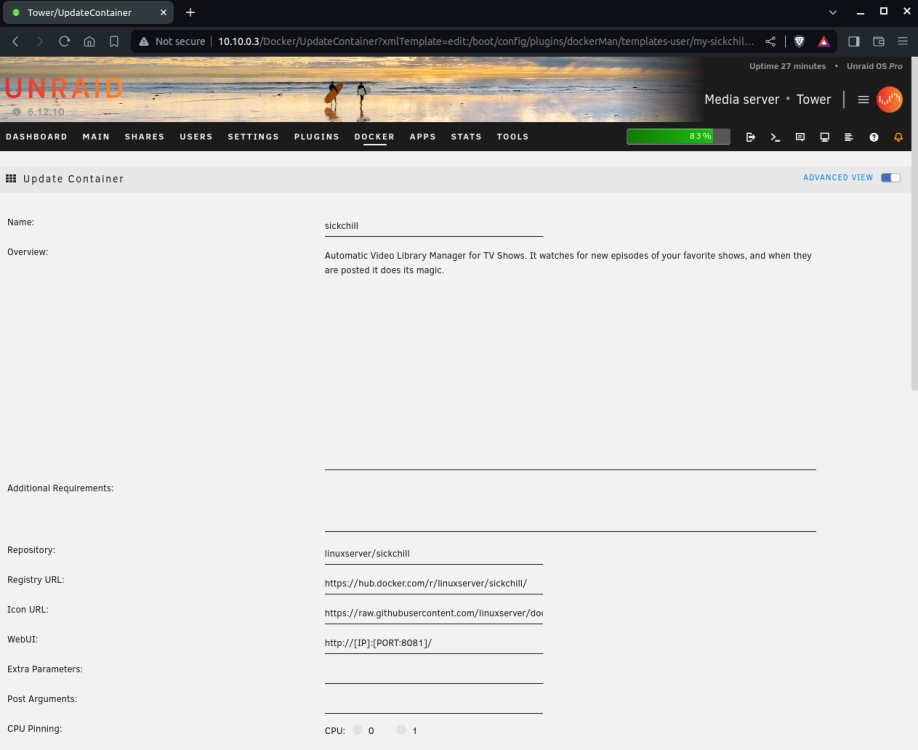
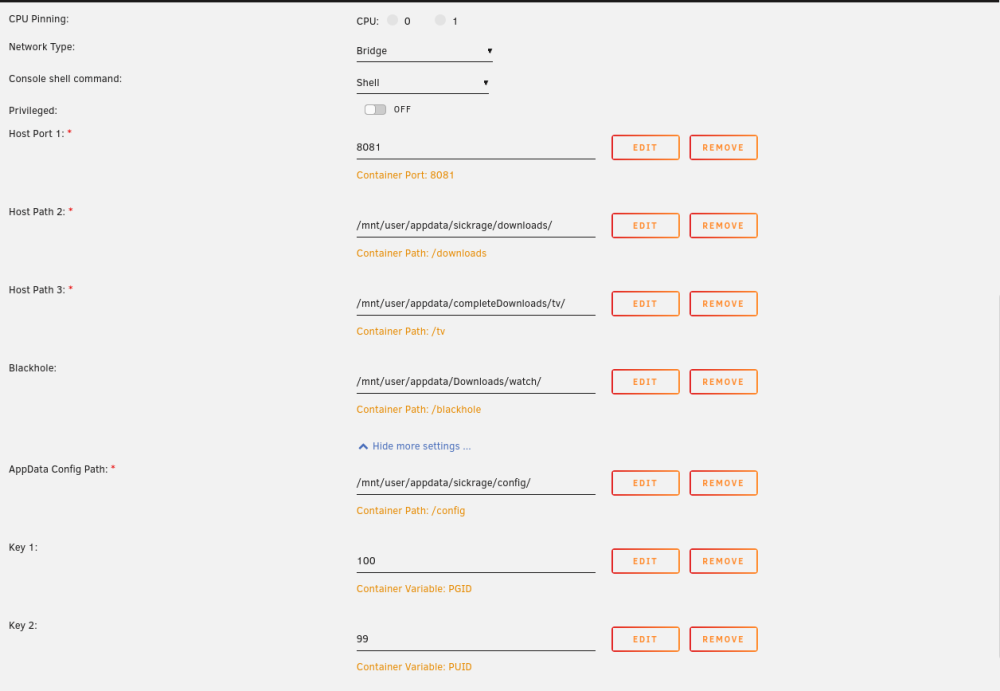
-
Just wanted to do two things: 1. A big thankyou to itimpi for the unRAIDFindDuplicates script. I have had a few copy/move errors over the last decade and itempi's script just found nearly 400GB of dupes scattered over my 42GB unraid array. 2. I banged together a little script that looks at the output of the itimpi's script, and deletes the dupes. Note that you must do a bit of cleaning of itimpi's output file first - delete everything except the file paths. That is, remove the lines at beginning of duplicates.txt that look like this: (also delete file size warnings, and the lines for files associated to the warnings) COMMAND USED: ./unRAIDFindDuplicates.sh Duplicate Files --------------- Here is my script - I called it 'delete-dupes.sh'. Execute it like this: bash ./delete-dupes.sh '/boot/duplicates.txt' #!/bin/bash # Check if the file exists if [ ! -f "$1" ]; then echo "File not found!" exit 1 fi # Read the file line by line while IFS= read -r line; do # Check if the line is empty if [ -n "$line" ]; then # Prepend "/mnt/user/" to the line path="/mnt/user/$line" # Delete the file path rm -v "$path" fi done < "$1" Be careful. If you execute the delete-dupes script twice in a row it will delete the remaining (now unique) files. I had thousands of files that were duplicated, without the script I would have been manually deleting duplicate files for weeks. Thanks again itempi!
-
Sickchill died for me recently after updating to latest docker version of sickchill via unraid docker screen "check for updates" button. I am on Unraid 6.9.1. Sickchill container ID: 46be26380d7a. I have restarted the sickchill docker a few times but no joy. Any ideas? Edit: I also tried editing the docker config to run sickchill in "Privileged" mode. Still no joy There are a few errors appearing when I view the logs: warnings.warn("urllib3 ({}) or chardet ({})/charset_normalizer ({}) doesn't match a supported " Checking poetry sickchill installed: True /usr/lib/python3.9/site-packages/requests/__init__.py:102: RequestsDependencyWarning: urllib3 (1.26.7) or chardet (5.0.0)/charset_normalizer (2.0.7) doesn't match a supported version! warnings.warn("urllib3 ({}) or chardet ({})/charset_normalizer ({}) doesn't match a supported " Traceback (most recent call last): File "/usr/bin/SickChill", line 8, in <module> sys.exit(main()) File "/usr/lib/python3.9/site-packages/SickChill.py", line 345, in main SickChill().start() File "/usr/lib/python3.9/site-packages/SickChill.py", line 90, in start settings.DATA_DIR = choose_data_dir(settings.PROG_DIR) File "/usr/lib/python3.9/site-packages/sickchill/helper/common.py", line 404, in choose_data_dir if location.joinpath(check).exists(): File "/usr/lib/python3.9/pathlib.py", line 1424, in exists self.stat() File "/usr/lib/python3.9/pathlib.py", line 1232, in stat return self._accessor.stat(self) PermissionError: [Errno 13] Permission denied: '/root/sickchill/sickbeard.db' EDIT 2: A new image of sickchill was released [Image ID: 357610432]. Pulled new image. Everything fixed.
-
The Jquery Web-UI is a bit too fancy for my ebook reader (Kobo Aura H2O). I can see some bits of the UI quite clearly but the bright blue bar that contains the downloads link renders as a grey blob on the Kobo. Nonetheless on the kobo I can't actually initiate a download to my e-reader. Dees anyone know if there is there is a simpler, old-fashioned URL I could hit to view a much simpler version of the UI?
-
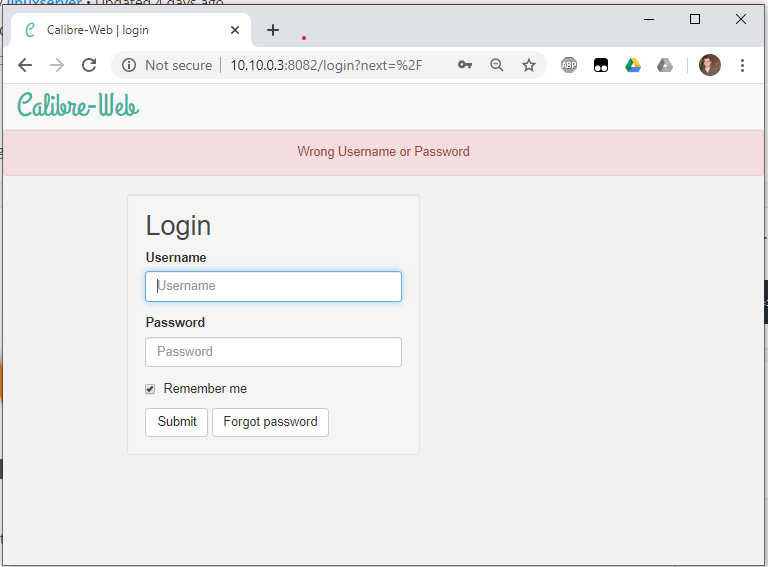
FIXED: I had to a) stop calibre-web; b) delete the app.db file , and c) restart calibre-web. I installed this Calibre-Web after being informed by Fix-Common-Problems that my previous Calibre docker was deprecated. I can't log in to the Calibre-Web Server. When I try the default admin/admin123 I get this message "Wrong Username or Password". Not sure how to proceed. I assume it's a PEBCAK error, but I can't see ehere I've gone wrong. I thought I'd be able to update the secrets file, but not sure what to put in there, or format. It's currently empty: root@1e58b165290d:/config# cat client_secrets.json {} root@1e58b165290d:/config# FYI I am running UnRaid 6.8.2. Here is a pic of login screen: