




surferjsmc
Members
-
Joined
-
Last visited
Everything posted by surferjsmc
-
No more unclean shutdows so i can confirm the scheduled TRIM job was the root cause. Thank you all for your feedback.
-
Update: TRIM was scheduled for 2:00 AM. A manual TRIM took 2–3 minutes, which perfectly matches the timing of the unclean shutdowns on my NVMe cache pool. I have rescheduled TRIM to run at a completely different time, far away from the shutdown window. Last night, the script executed the server shutdown perfectly. The server started manually this morning with no errors, confirming that the overlapping schedules were the root cause. I'll monitor the system and the new TRIM schedule for a few days to make sure it's fully resolved. New diagnostics added. corellia-diagnostics-20260626-1106.zip
-
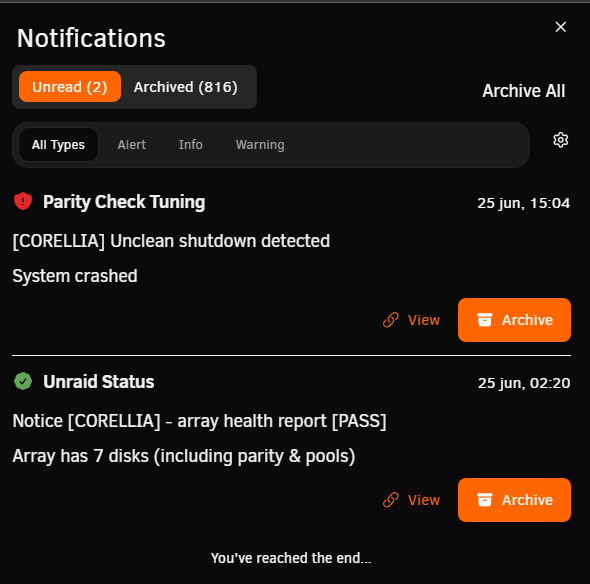
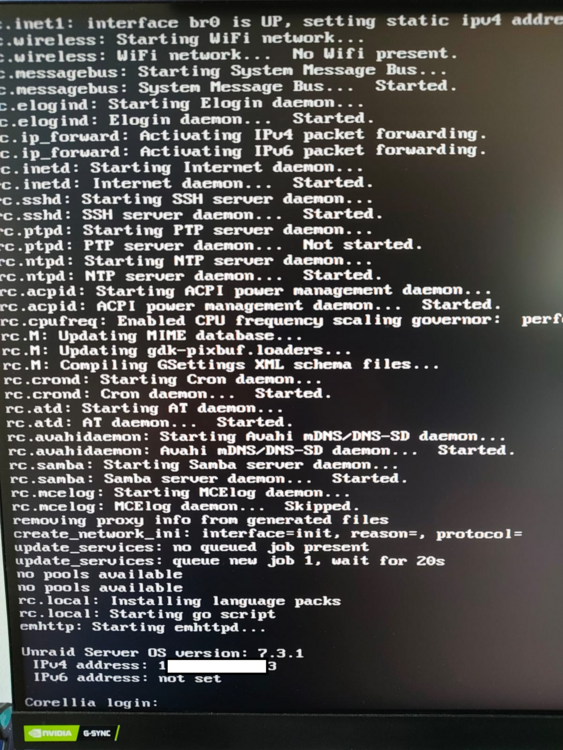
Hi, sorry for the delay. Today I finally had time to check the scheduled BIOS power-on. With a monitor hooked up to the server, I followed the whole startup process and didn't notice anything wrong. The server took about 3 minutes in total from power-on to the login prompt, and nothing looked abnormal (attached is a screenshot of the boot screen). The boot finished at 15:03, but the server error occurred at 15:04, even though it never rebooted itself or failed during that time. Once again, however, the same notifications appeared. I also performed a manual shutdown and boot, and it didn't return any errors. I even tried turning the server on in the morning before the scheduled time, and there were also no errors. Everything was running as usual—just a few containers and plugins, and no VMs. corellia-diagnostics-20260625-1516.zip
-
I manually shut it down while the parity check was running at 43%, then started it again, and there were no notifications of an unclean shutdown.
-
Hi all, Two days ago, I noticed a notification reporting an unclean shutdown, which triggered a parity check as expected. However, for the last three days, including today, I have been receiving the same notification. My server is configured to power on every day at 3:00 PM through the BIOS and shut down every day at 2:00 AM, except on Friday and Saturday nights, using a basic custom script: /usr/local/sbin/powerdown Cron schedule: 0 2 * * 1-5 Everything was working correctly until Monday. Based on the notifications, it does not appear that the scheduled shutdowns are failing. The unclean shutdown alert is being generated about four minutes after startup, around 3:05 PM. On Tuesday, I started the server manually, and it shut down four minutes later, just as it does when it starts automatically at the scheduled time. One thing worth mentioning is that after the unclean shutdown notification, the server appears to start normally. All services seem to work as expected, and the parity check is automatically triggered, just as it should be after an unclean shutdown. From a functional standpoint, everything looks normal apart from the repeated unclean shutdown alerts. To be honest, I can't find anything useful in the logs, so I'm sharing the diagnostics in the hope that someone can identify the root cause of this issue. Thx in advance! corellia-diagnostics-20260610-1624.zip
-
Another 1U rack server, Quanta S210-X12RS
-
Oh ok i was wrong, thanks Strike!!
-
Hello guys! Doing some housekeeping, I've found the custom script below, scheduled at array start. To be honest, I don't remember when I put that in there, and it seems to be related to keeping the NVIDIA driver up to date. Anyone recall if this is still necessary? wget https://raw.githubusercontent.com/keylase/nvidia-patch/master/patch.sh chmod +x ./patch.sh ./patch.sh
-
Well, I guess now I just need to set both shares to 'cache only' and start Docker, right?
-
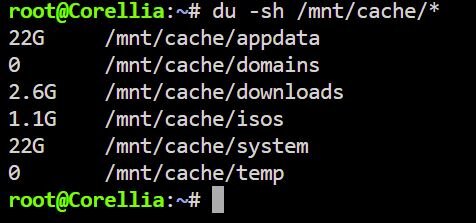
Mover is done and here are the diagnostics corellia-diagnostics-20250608-0916.zip I don’t understand why, if the shares are 22 GB and 54 GB, the cache pool only shows 42 GB used.



-
Well after a few weeks I'm facing several issues, docker starts and after i don't know what it fails, here are some screenshot of fix common problems and how i have the pools and shares, obviously is a appdata location issue and I've tried to changed from cache only to cache-array and even revert to just array but i can't find the solution :( Perhaps i just need to move appdata and system files from the array to the cache? Also I'm concern about the memory issue, I've replaced my previous hardware and maybe RAM is failing. corellia-diagnostics-20250604-1130.zip



-
Thanks to ChatGPT Lenovo ThinkCentre M93p


-
Hello i have two requests: Lenovo ThinkCentre M93p And HP Elitedesk 800 G3/G4/G5 TWR Thanks in advance!


-
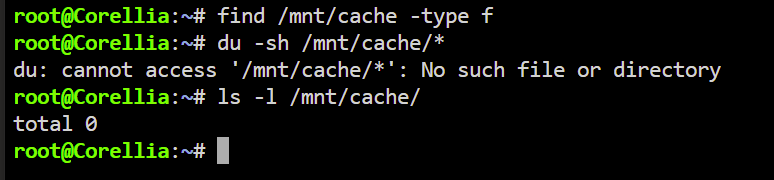
Well I've set all the shares that had data to use cache as primary and array as secondary then executed mover and now the cache drive is empty after all files where moved. I'll set everything back to array only, stop the array, delete the cache pool and replace the drive. Thank you all!

-
The only way I see to set a secondary storage location is by changing the primary to "cache," which doesn't seem logical to me, since my goal is to eliminate the cache drive.
-
New diags, Thx Jorgecorellia-diagnostics-20250512-1537.zip
-
Hi! I need to replace my cache drive but first i have to eliminate the current one, I've started by disabling docker and VMs, then changed all shares to use array only and stopped the array, then manually run Mover. At first around 115 GB where stored in cache and after executed mover the first time around 60GB still stored, Mover Tuning was not installed until today after several manual runs failed but same results. corellia-diagnostics-20250512-1457.zip




-
We are getting old
-
To be honest I don't recall disabling that but it fixit, could be related to replacing the disk or maybe upgrading from 6.12 to 7? Once again thank you Jorge!
-
New diags tatooine-diagnostics-20250219-1647.zip
-
tatooine-diagnostics-20250219-1421.zip
-
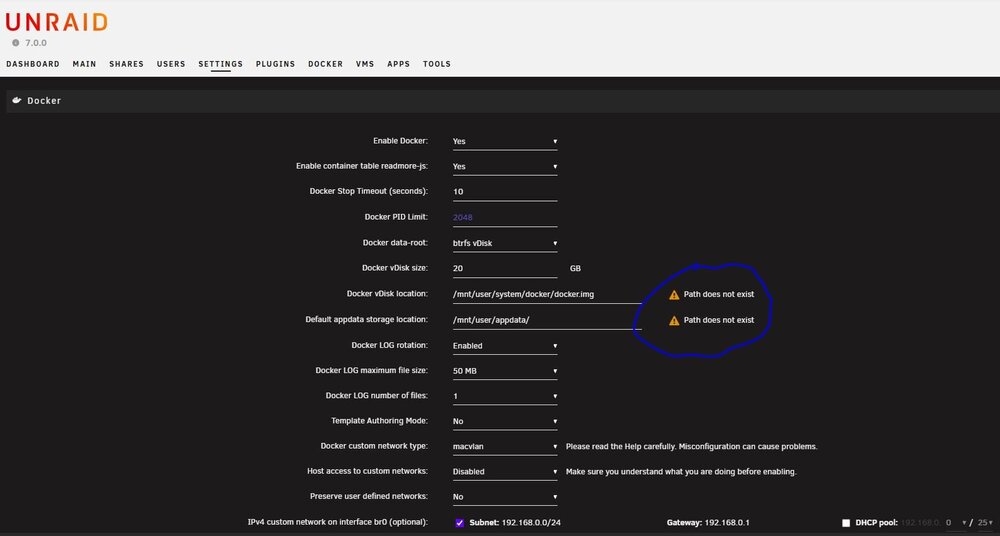
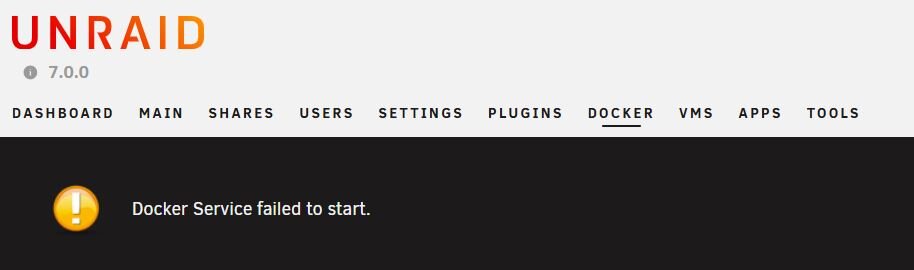
Both Docker and VM fail to start
-
yes i did.
-
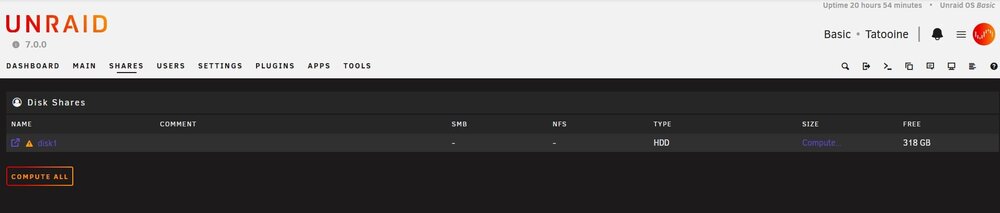
After a few years of inactivity, I started my Unraid test server again today. It originally had a single disk in the array without parity or cache, running version 6.12, which I’ve since updated to version 7. I had to replace the original array disk with a different one since I no longer have the original on hand. This is when I ran into issues with Docker, specifically missing vDisk and appdata paths. I assume the problem arose because the original disk was replaced with a different one, which is now empty. All shares are missing so I’ve tried using the 'New Config' option and followed the knowledge base steps to delete the Docker vDisk, along with a few other things, but I’m still stuck without a solution. There’s no data stored on this server—it's just for testing purposes. I’m open to wiping anything you suggest to get everything back to square one. At this point, I’d appreciate your advice. Thank you in advance. tatooine-diagnostics-20250218-1428.zip
-
Hi Jorge, in. the past same thing happened but from my laptop and I'm pretty sure it wasn't because I've double click it 😊


























