




doma_2345
Members
-
Joined
-
Last visited
-
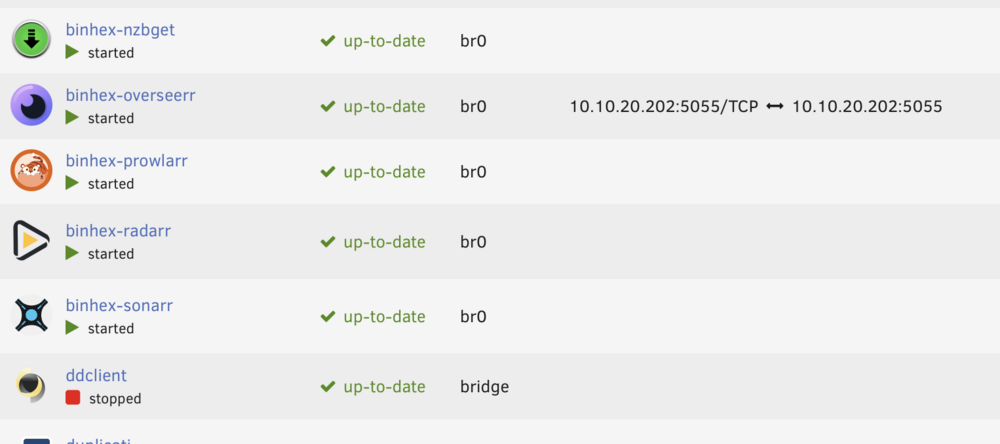
Yes, i have tried restarting the docker service. I have tried doing a force update. I am not sure what the 'template function' is (i assume you mean reinstalling from template) i havent tried this and dont really want to delete all of these containers to do this, In terms of editing them i am not sure what has been removed in the last update to edit them to put it back.
-
I have noticed that on all of my binhex containers the port mappings are now empty after the latest update of the containers. The only one that didn't update was overseerr which still has the port mappings. Any idea how to fix this as it causes issues when I click the webui menu button as it doesn't work.
-
Ok, i didnt reailse that, but assuming I am only writing file of max 20gb it will leave around 500gb free? I have my cache drive set to leave 250mb free but presently it is leaving 500gb (approx) free. I have found where to file a big report so have done so.
-
This was originally reported here and seemed to be fixed at some point meaning the cache drive could be fully utilized. However, when I upgraded to 6.10.x the issue/bug seems to be occurring again. I have my shares set to leave 500gb free on all my array drives, however this means that when my 1tb cache drive gets to 500gb utilization, any new copies start to write to the array, The old functionality used fill up the cache drive to 1tb and then start to write to the array. I cant see how this could have been implemented as a design feature by the fact that the functionality keeps changing and it also makes having large cache drives completely redundant if it only uses some of the available space. 35highfield-diagnostics-20220818-1538.zip
-
This was originally reported here and seemed to be fixed at some point meaning the cache drive could be fully utilized. However, when I upgraded to 6.10.x the issue/bug seems to be occurring again. I have my shares set to leave 500gb free on all my array drives, however this means that when my 1tb cache drive gets to 500gb utilization, any new copies start to write to the array, The old functionality used fill up the cache drive to 1tb and then start to write to the array. Not sure how to report this as a bug and cant see how this could have been implemented as a design feature by the fact that the functionality keeps changing.
-
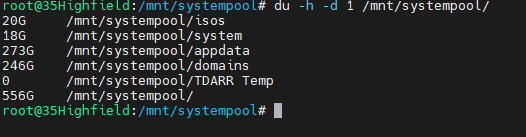
I am looking into the usage / capacity of a pair of raid 1 btrfs pool ssd's I am trying to work out what is taking up the space but i seem to be unable to get correct usage stats The main gui reports the following DF -h report the following which largely matches the GUI DU -h -d 1 reports this, which seems off and the shares page reports this, which is also different there is nothing other than these shares on the drive How do i get the true file size, i believe the total usage is correct but the individual share sizes is wrong, how do i get a proper overview of the sizes of the shares?



-
from looking into this du should be reporting a larger amount than btrfs reports not a smaller amount.
-
actually i think i might have been reading it wrong, trying to work out the switch for file depth
-
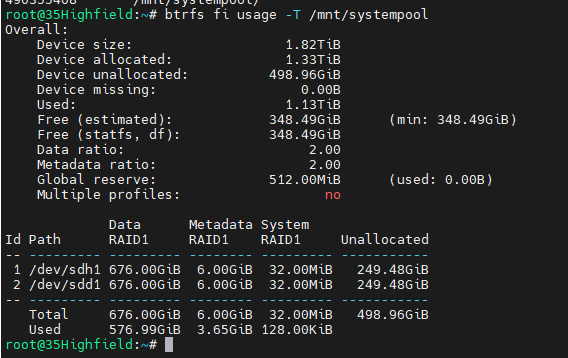
Well thats a different number again
-
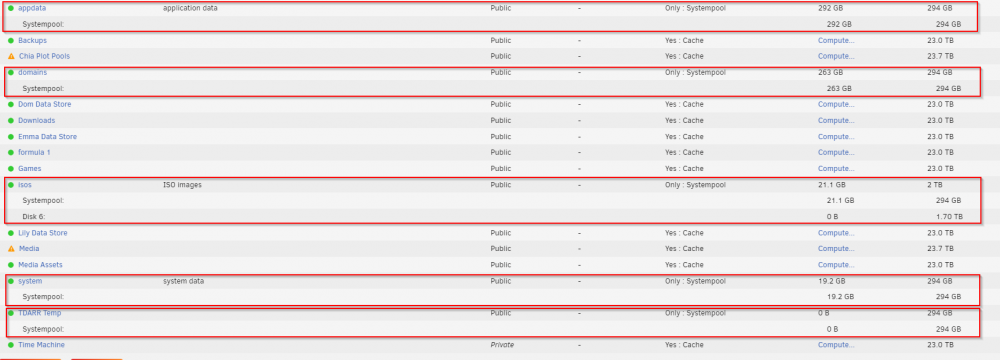
Hi All I wonder if someone could answer this I have a seperate pool set up /mnt/systempool The disk usage says the following These are two 1tb ssd's in a raid 1 configuration These are the system folders on this pool I thought it was strange the amount of spare capacity i had on this pool and when investigating found the following Why is the gui showing one thing and cli showing another?

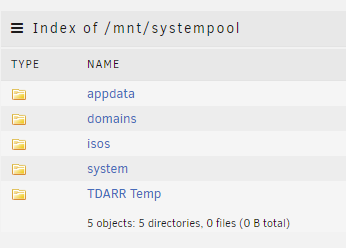
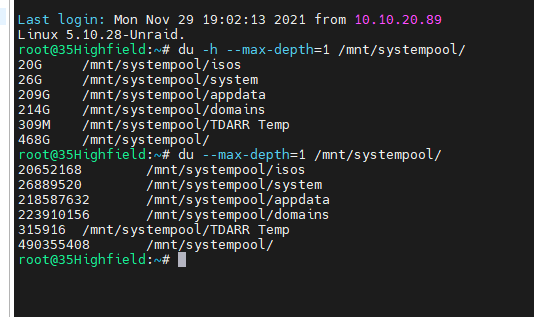
-
Although a pain and a long process, I can live with parity being rebuilt, at least I know now how to do it, (Tools > New Config) and my OCD can rest easy.
-
I know this has probably been asked before, but I couldnt find a suitable answer. This is how my disks look currently and its killing my OCD as the disk sizes arent grouped together. I would like to group all the 12tb drives together as disks 5 - 8 Is the fix as simple as stopping the array and re-assigning the disks, or is this totally not the way to do it, is there even a way to do it? These disks are not empty so I dont want to reformat and lose the data, so need to avoid that scenario.
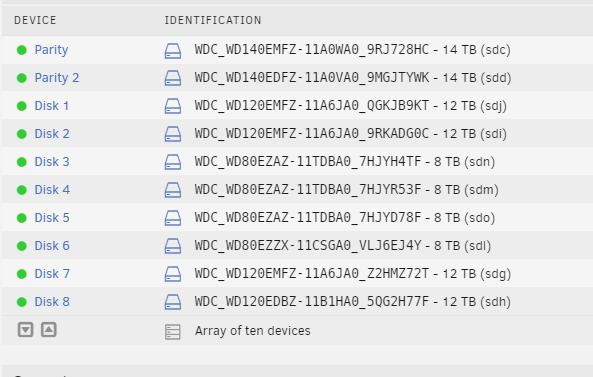
-
everyone please be aware of this bug i lost my first two chia farmed becuase of it, make sure you config file is correct https://github.com/Chia-Network/chia-blockchain/issues/3141
-
great to see this on the test version, much easier than checking the logs. Also much better than the response times I was getting on VM accessing the shares
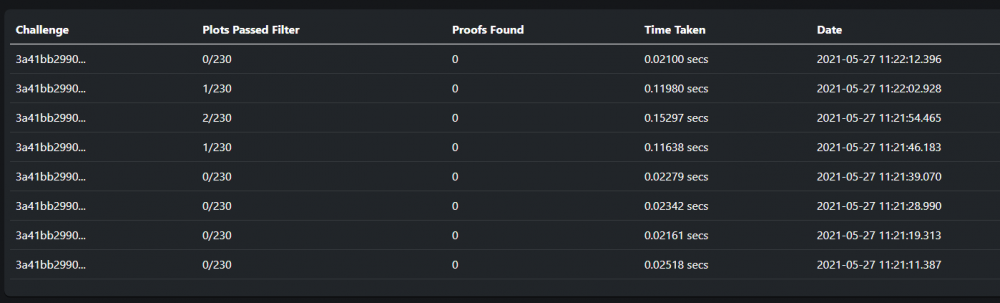
-
do you have nightly back ups of your appdata folder using CA Backup, the docker containers are stopped for this, i believe the default time is 3am












