

CyaOnDaNet
-
Posts
32 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by CyaOnDaNet
-
-
Well after 34 days server uptime, it finally happened again. I will try the redis container for Nextcloud cache thing that @jcsnider suggested and report back how it goes. You should hear from me in about 45 days if it seems to be working or earlier if it doesn't work. 🤞
-
14 hours ago, jcsnider said:
Very interesting. I wonder if in your case you would have also been able to collect diagnostics. I have never been able to get a clean shutdown or collect diagnostics once things have started to lock up.
Maybe, I just didn't even think to try that time because the other two times it didn't work.
14 hours ago, jcsnider said:Historically when everything has broken down uptime is greater than 3 days, sometimes upwards of a week or two.
The two main times it has happened to me was about 30 days uptime. The third time I was only at maybe a week uptime but I had the container offline the whole time and only had it started for like the last 5 minutes of uptime.
14 hours ago, jcsnider said:On a side note: How often is your Mover configured to run?
Mine runs once every 8 hours. I noticed the two main times it happened that my mover was stuck. I ran the command mover stop and it did actually stop but that did not help safely shutdown or get the diagnostics data. I have my parity check scheduled monthly on the first and both times I noticed the issue it was November 3rd and December 3rd. I thought that maybe a combination of parity check and mover caused the issue but I have run manual parity checks since then with no issue so that was coincidental. This last time it happened where I could actually shutdown, my mover was not running, it hadn't been triggered yet. Maybe a combination of nextcloud locking up and the mover running prevents safe shutdown (and maybe diagnostics collection too?).
On a side note, my nextcloud is still running fine after the changes I made but it hasn't been very long. I will keep updated here on how it goes. If I can make it to 30+ days uptime again then I know the issue is probably solved. Unfortunately, I kind of plan on shutting down soon to adjust some things so it may be a while before I get to 30+ days again. -
19 hours ago, jcsnider said:
I'm guessing if you ssh into your unraid server and try to run lsof on any location (ie: lsof /mnt/user) that will also never finish executing (requiring a new terminal instance in order to issue further commands).
By the way, I just wanted to confirm that this was true for me. After it locked up, I performed a shutdown and though it took an extra minute or two, it was actually able to safely shutdown. The other 2-3 times this has happened, I could not shutdown because the docker service couldn't stop nextcloud. Maybe because I caught it so fast yesterday it didn't completely lock everything up.
-
19 hours ago, jcsnider said:
I never assigned a /tmp docker path, but I modified the php config within NextCloud to use a subdirectory in the /data folder to store upload data as it's being recieved so effectively I am doing the same thing to avoid my docker file increasing in usage dramatically.
I guess I should have been a bit more specific earlier. I added 'tempdirectory' => '/tmp/nextcloudtemp/', to my config.php in nextcloud and I added upload_tmp_dir = /tmp/php/ to my php-local.ini and then I mapped /tmp --> /mnt/user/appdata/nextcloud/temp which would technically be /data/temp.
19 hours ago, jcsnider said:Are either if you all using the filesystem_check_changes’ => 1, flag in your NextCloud config.php?
I was not but after you brought it up, I read about it and it sounds beneficial to our use case. I'm adding it now, did you have this enabled before? @jcsnider
19 hours ago, jcsnider said:I went into my NextCloud config and changed all my shared paths access properties to 'Read/Write - Shared' instead of just 'Read/Write'
I will do that too.
19 hours ago, jcsnider said:My instance is working for now but I don't expect that it will last.
Is it still working?
-
16 hours ago, jcsnider said:
If you ssh into your servers what is the output of the following command?
Wow, so I started up my container to get the version info for my previous comment and a couple of minutes later it 504'd. I ran the command and got the following:
root@Nighthawk:~# ps axl | awk '$10 ~ /D/' 4 99 6321 14590 20 0 127440 37480 - D ? 0:00 php7 -f /config/www/nextcloud/cron.php 4 99 7676 14590 20 0 127440 39696 - D ? 0:00 php7 -f /config/www/nextcloud/cron.php 5 99 19593 14579 20 0 260996 24004 - D ? 0:00 php-fpm: pool www 5 99 20230 14579 20 0 261060 23412 - D ? 0:00 php-fpm: pool www 4 99 25703 14590 20 0 127440 39340 - D ? 0:00 php7 -f /config/www/nextcloud/cron.php
-
15 hours ago, jcsnider said:
Other posts/threads that seem to be experiencing the same issue dating back to Unraid v6.5 and NextCloud 18.X.X.
I am running Unraid v6.8.0-rc7 and Nextcloud 19.0.5 (I know my unraid version is old old but I needed the the linux kernal in this version and they reverted it all v6.8.x after this RC. I will be updating to v6.9-RC1 soon after I read about any potential issues people may be having).
15 hours ago, jcsnider said:If you ssh into your servers what is the output of the following command?
Unfortunately, I gave up and performed an unsafe shutdown. My nextcloud docker isn't even running right now because I didn't have time to deal with this if it happened again but I will start it back up later today.
15 hours ago, jcsnider said:Are you all using LSI cards?
Yes, I have a LSI Logic SAS 9207-8i Storage Controller LSI00301.
1 hour ago, p3rky2005 said:Insidently i should now add ive waited untill now to post this as ive had 3 days stable, my issue actually was caused by trying to get nextcloud not to fill up the docker image upon upload, i added a /tmp variable and it worked for about a week and then started showing issues, but none of the logs show anything,
remove that /tmp variable and now its running stable again
This is interesting, I completely forgot I made changes to my container back in early October. I too had issues with nextcloud filling up my docker image during file upload. I have had nextcloud for a while but never really used it. I started uploading video files and noticed my docker image filling up so I looked into it but didn't find a whole lot of info. I added the docker path /tmp ---> /mnt/user/appdata/nextcloud/temp and that stopped my docker image from filling up. It just points the nextcloud /tmp directory to my cache drive. Has anyone else having this issue made any changes to the /tmp path? What about you @jcsnider?
-
Did you ever figure this out? I am having a similar issue. I noticed I couldn't log into my nextcloud today and attempted to restart the container in the GUI but it wouldn't stop. I tried the following commands in an ssh console but it just waited without doing anything:
docker stop nextcloud docker kill nextcloud docker rm --force nextcloud
Trying to download the unraid diagnostics in the webGUI results in endless waiting. Typing "diagnostics" in an ssh console resulted in "Starting diagnostics collection..." for over 12 hours and nothing was created in the /boot/logs folder.
Interestingly, on the "/Main" tab in the webGUI, my unassigned devices plugin won't load. I believe this issue may have overlapped with a parity check but I could be mistaken or that could be coincidental. My server won't shutdown because my docker service won't stop. All because I can't stop the nextcloud container. -
On 5/22/2020 at 10:36 AM, Fiservedpi said:
How would I stop the doubles?
This is a bug that slipped through the cracks. I believe I have a fix for it that will be implemented in the version 2.0.0 update. It's taken me a little while to get this update done as I have been pretty busy lately. I might just push the update early once I get to a stopping point with the current feature I am working on.
-
6 hours ago, Fiservedpi said:
anyone else's container randomly stop? I always have to keep an eye on it is this a bug?
I saw your issue on github, my response is below:
QuoteThat happens to me when discord has an outage, but that is usually only like once a month for me. If it is happening that frequently for you then maybe you have another issue causing discord to be unreachable. I will look into a way to handle this, like a reconnect handler. The last time I looked into this I hit a dead end. For now, you can use the docker flag `--restart always` to make it restart automatically.
To add the `--restart always` flag on unraid, enable advanced view on your container settings, go to the `Extra Parameters:` option and put `--restart always`.
-
 1
1
-
-
On 4/24/2020 at 4:18 AM, KINO said:
Hey there! Thank you for the wonderful work on this - I did have a question, though.
I currently have customized Tautulli to send Recently Added notifications like so (it took me sending a newsletter to an email and then setting it up to be parsed into a Discord Webhook). I do this on purpose, I don't like spamming my discord with a bunch of notifications, and would rather have this fire-off into the server once per day. Is there a way for me to setup your bot to detect which shows are in this list and, in turn, tag that role?
Thank you so much in advance!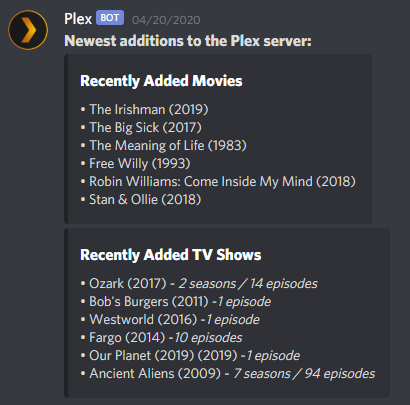
@KINO The intention behind the role mentions is that the channel the notifications feed into is muted and set to notify @mentions only. That way the user is not constantly spammed by all notifications but rather the ones that matter to them. You can manually give shows a role using the bot commands if it didn't auto create it for the desired show.
Firing off messages once per day is not currently possible. That gave me the idea of being able to set quiet hours, where the bot caches all messages during the window and sends them out once quiet hours are over. I will look into adding that; it should be possible to have it fire off once a day by just setting the quiet hours to only allow a 1 minute opening. It will be a little while before I can get to that as I need to refactor my code to work with Discord.js 12 first. -
On 3/24/2020 at 12:01 PM, Roken said:
message: 'request to http://192.168.1.73:8181/plog/api/v2?apikey=0501b2695dcd44a6ba6df9fbe9b587c1&cmd=get_activity&out_type=json failed, reason: connect EHOSTUNREACH 192.168.1.73:8181',~Tautulli Webhhok Startup~ Connection refused [Attempt #1], retrying in 30 seconds...I keep getting these errors. I've tried to directly accessing the url and it works fine from Chrome. Any ideas?
@Roken Sorry for such a late response. I'm not sure why this would be an issue. It looks like you have a webroot set to /plog/ on Tautulli. That means when you access the main UI page for tautulli the address is http://192.168.1.73:8181/plog/home.
The only other thing I can think of is for you to double check that you api is enabled in Settings > Web Interface > API > Enable API. -
9 hours ago, Fiservedpi said:
@CyaOnDaNet how are you getting images? Associated with the notification, is the .jpg inside the file with the .mkv?
@Fiservedpi You don't need to worry about generating images in the sub-folders or anything, Tautulli can provide image URL's. The image URL has to be publicly accessible and is automatically grabbed from Tautulli when the notification is pushed. To use this, enable image hosting in Tautulli. Go to Settings > 3rd Party APIs and select an option from the Image Host drop down. I self host my Tautulli now but in the past I have used Imgur with no problems.
-
1
-
-
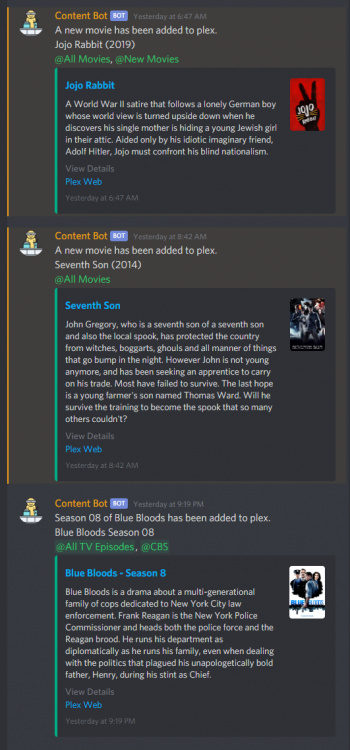
Even if you don't select the movie react roles with `!notifications edit`, the #notifications channel you set up will still receive recently added movie notifications, just with no roles if none are enabled.
-
 1
1
-
-
28 minutes ago, Fiservedpi said:
Would this work for Radarr? I'd like to be notified via Discord of movies added
@Fiservedpi
As of right now it doesn't connect to Radarr. You can have 2 types of movie based notifications though, triggered by the self-generated Tautulli recently added webhook. There is an All Movies react role and a New Movies react role (set if the movie was released within the last 9 months). These can be enabled with `!notifications edit`.
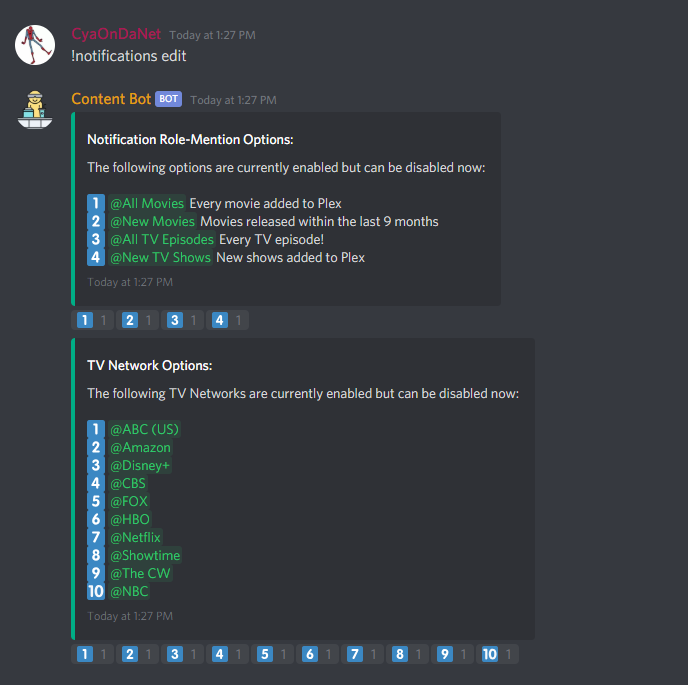
I have a few cool ideas brewing that may need a Radarr connection, so that may be a thing in the future.
-
 1
1
-
-
4 hours ago, Reldnahc said:
Also when I try to call!show listI get this in my logs.
(node:1) UnhandledPromiseRejectionWarning: RangeError: RichEmbed descriptions may not exceed 2048 characters. at RichEmbed.setDescription (/app/node_modules/discord.js/src/structures/RichEmbed.js:103:42) at Object.execute (/app/commands/showlist.js:23:5) at processTicksAndRejections (internal/process/task_queues.js:94:5) (node:1) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). (rejection id: 16) (node:1) UnhandledPromiseRejectionWarning: RangeError: RichEmbed descriptions may not exceed 2048 characters. at RichEmbed.setDescription (/app/node_modules/discord.js/src/structures/RichEmbed.js:103:42) at Object.execute (/app/commands/showlist.js:23:5) at processTicksAndRejections (internal/process/task_queues.js:94:5) (node:1) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). (rejection id: 16)@Reldnahc
I apologize for my oversight on this issue. I have a small library and neglected to envision what would happen with a larger library. All the Discord embeds that I could see exceeding limitations go through checks now and split up into multiple messages to prevent an error like this one. It should be fixed now, click on the advanced view in docker containers to force an update now or click check for updates at the bottom of the docker page and then apply update to the docker container. You will know if you have this update if the !bot info command shows Bot Version 1.2.2
4 hours ago, Reldnahc said:Hi I am trying to get this Docker to work. When I call
!notifications editIt opens the boxes with the react commands but nothing happens when I react.
That's strange that nothing happens after reacting. Is there anything in the logs? Does it say nothing was selected in time?
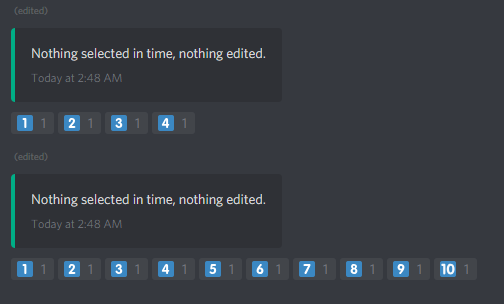
If no to both, then it is most likely hanging during the create Discord Role process. I would make sure your Bot has administrative privileges or at least manage role privileges but that should have still produced an error in the logs. -
1 hour ago, killjoy85 said:

Any idea on how to resolve?
I have tested and confirmed that that error is the result of an invalid Discord Bot Token. Make sure you have a valid Token in the template and try again.
Go to https://discordapp.com/developers/applications/ Click on your Bot application or make a new one. On that application click the bot tab and copy the Token and use it in your template.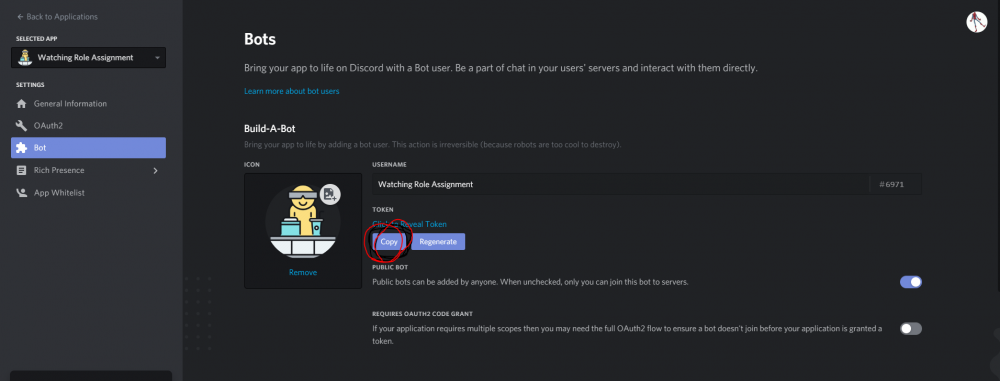
-
1
-
-
On 1/19/2020 at 5:06 AM, Bolagnaise said:
@CyaOnDaNet in your guide you wrote
it should be
If you want to see if its working, run `!bot logchannel #channel
Thanks, I updated the guide.
On 1/19/2020 at 5:13 AM, Bolagnaise said:@CyaOnDaNet new error when running !notifications list
DiscordAPIError: Maximum number of guild roles reached (250)
at /app/node_modules/discord.js/src/client/rest/RequestHandlers/Sequential.js:85:15
at /app/node_modules/snekfetch/src/index.js:215:21
at processTicksAndRejections (internal/process/task_queues.js:94:5) {
name: 'DiscordAPIError',
message: 'Maximum number of guild roles reached (250)',
path: '/api/v7/guilds/632476253542154240/roles',
code: 30005,
method: 'POST'
That error means that you hit the Discord Server Role Limit which I had not accounted for until now. Go ahead and check for updates and you should have bot version 1.2.1. I adjusted the code to work around the limit so it should be functional but you will still have that error in your logs. By the way, !notifications preview is a new command that can be used in place of !notifications list when experimenting, I created it because the bot now tracks the most recent call of !notifications list and updates the emoji reactions on bot startup to reflect any changes while it was offline. If you run !notifications preview or !notifications list it will generate as many roles as it can until it hits the Discord limit and then stops generating new roles. You can then proceed to edit that list with !notifications exclude show to get rid of anything you don't like and recall !notifications preview or !notifications list to let it reprocess and add new shows.
As an FYI, I also added a !delete command which deletes all Roles that have been generated by the Bot for easy cleanup if anyone decides to stop using the bot.-
1
-
-
8 hours ago, Bolagnaise said:
yes it does, (well http://192.168.0.101:8181/tautulli/home does) so it seems its not the issue, i installed the default tautulli, same issue. Best bet is too nuke everything i guess
Okay, so it looks like changing the webroot does have an effect. It looks like you changed the webroot to add the /tautulli then. I changed the code to allow webroot overrides by leaving the port field blank. Go ahead and check for docker updates or force apply and you should have bot version 1.1.6. What you need to do is leave the Tautulli port field in the template blank and instead put the full root path in the ip section. So in your case put 192.168.0.101:8181/tautulli as the ip and the port field empty. If you changed the webroot for Sonarr then do the same thing for that. I will go ahead and edit my OP to reflect this so others can see it easily if they also changed their webroot. Sorry for the issues, I was unaware I needed to account for webroot changes, but all should be good now.
-
1
-
-
10 minutes ago, Bolagnaise said:
I have googled the shit out of it, i think it might have something to do with me using a base url for a reverse proxy
Also, does http://192.168.0.101:8181/home take you to your Tautulli home page? If it does, I imagine the base url change shouldn't have effected the api.
-
1 minute ago, Bolagnaise said:
No problems, im going to uninstall the linuxserver version and try the Tautulli version.
For what its worth, I'm using the linuxserver version and its fine. My web interface settings look like this and its behind a nginx proxy but the bot accesses it locally so it has no problems.
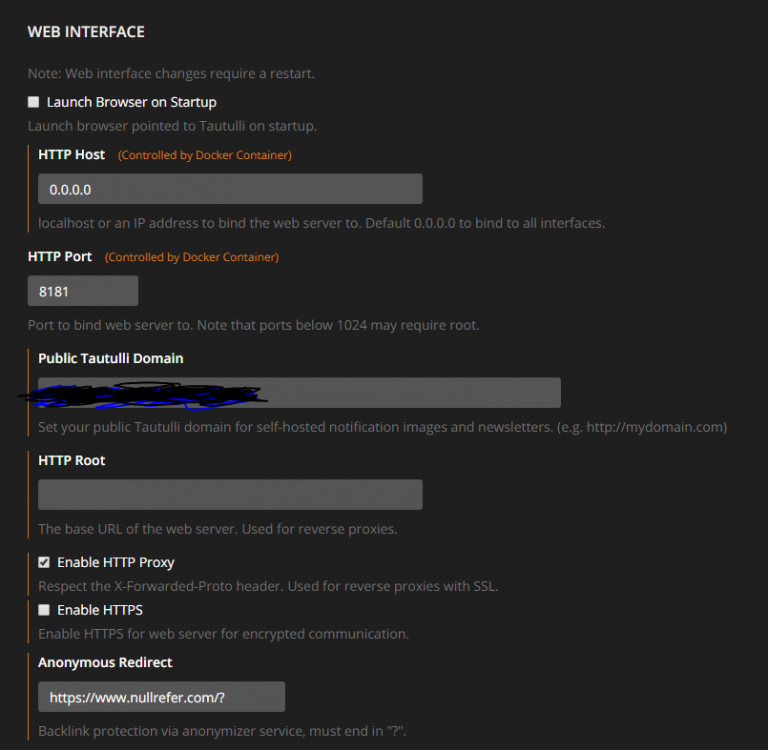 6 minutes ago, Bolagnaise said:
6 minutes ago, Bolagnaise said:I have googled the shit out of it, i think it might have something to do with me using a base url for a reverse proxy
Did you change the HTTP Root section?
-
29 minutes ago, Bolagnaise said:
same issue still happening.
First off, thanks for the log info and that screen capture. You clearly have the ip and port correct because of the "Powered by CherryPy 5.1.0" footer. If the api key was wrong it would still return a json saying invalid API key. Instead, its returning a html 404 error which is why the bot doesn't errors. I can reproduce the same 404 error page on my own Tautuill service by entering an invalid path. It's like your Tautulli api endpoint doesn't exist. This is very strange. The only thing I can suggest right now is to check if your Tautulli is up-to-date but I doubt that will make a difference. I am in communication with the Tautulli Discord support channel to see as to why your endpoint is not working. I will get back to you when someone offers a solution. Sorry if I could not be of more help at this current moment.
-
44 minutes ago, Bolagnaise said:
Unexpected token < in JSON at position 0',
type: 'invalid-json'After doing some more digging, I discovered that Tautulli's api can also return xml even though json is the default. Since it returned with < at position 0, I can only assume it returned xml. I made some changes to force it to return json and the container update is live, its bot version 1.1.5. Click on the advanced view in docker containers to force an update now or click check for updates at the bottom of the docker page and then apply update. If it's still returning this same error after the update let me know and I will enable some more debugging to see whats going on.
-
3 minutes ago, Bolagnaise said:
I cannot get it to connect to Tautulli, keeps getting this error. Api access is enabled in tautulli and its the correct api key.
message: 'invalid json response body at http://192.168.0.101:8181/api/v2?apikey=''TOKENREMOVED''&cmd=get_activity reason: Unexpected token < in JSON at position 0',
That's strange, is there anything else in the logs? I imagine its referring to the tautulli.js file at line 104 but I'm not sure what could cause an error like this. After some searching it appears that a TLS encrypted tautulli could have caused this. Do you by chance normally access tautulli with https? If so, just add that to your ip, so for your case it would be https://192.168.0.101 in the ip section of the template.
-
Just now, Fiservedpi said:
Sorry yes everything is good
Okay, cool, glad to hear. That was a weird issue you were having and I may need to dig a little deeper if someone else has the same problem.










Can't stop docker container Nextcloud or reboot the whole system
in General Support
Posted
Unfortunately, I have tried everything I could think of and have no idea how to stop it without forcing an unsafe shutdown. One time it shutdown like it was supposed to (I think because I caught it so fast) but all other times it hung. I close out everything I can, all other dockers and VM's, issue a shutdown and then hold the power button 15 minutes later. You have to do a parity check after this but otherwise I had no noticeable ill effects.
I can happily say that I am at 67 days server uptime with no issues. The redis changes seemed to be the last things I needed to make Nextcloud stable again. I have changed so much and its been a while but I will try to list everything I did below so others can hopefully benefit:
Starting with docker template changes:
In my nextcloud appdata directory under /www/nextcloud/config/config.php I changed/added the following things:
'filesystem_check_changes' => 1, 'memcache.local' => '\\OC\\Memcache\\APCu', 'memcache.distributed' => '\\OC\\Memcache\\Redis', 'memcache.locking' => '\\OC\\Memcache\\Redis', 'redis' => array ( 'host' => 'THE SAME IP USED IN THE CONTAINER FOR REDIS_HOST', 'password' => 'THE SAME PASSWORD USED IN THE CONTAINER FOR REDIS_HOST_PASSWORD', 'port' => THE_SAME_PORT_USED_IN_THE_CONTAINER:REDIS_HOST_PORT, ), 'filelocking.enabled' => 'true', 'datadirectory' => '/data', 'tempdirectory' => '/tmp/nextcloudtemp',In my nextcloud appdata directory under /php/php-local.ini I changed/added the following things:
upload_tmp_dir = /tmp/php/ session.save_handler = redis session.save_path = "tcp://SAME_IP_FOR_REDIS_THAT_I_USED_IN_CONTAINER:REDIS_PORT?auth=REDIS_PASSWORD"