




GrehgyHils
Members
-
Joined
-
Last visited
-
@shawnngtq I ended up getting my UI to pop up by simply pressing esc...
-
Okay interesting. May I ask, what Linux distro are you trying to install? Also, did you get to the initial boot when you installed the OS or was it a black screen from the beginning? Agreed, the docker ui is lovely.
-
@shawnngtq negative, I haven't made any progress on this. Are you experiencing the same thing?
-
Hey everyone, I'm using Unraid version 6.9.2 and I'm attempting to create a Linux VM, specifically Pop OS 21.10, without Nvidia drivers. When I first created the VM, it booted to the installation screen and I walked through the wizard just fine. Once the VM rebooted, I've only been met with a black screen... Here's the XML of the VM: <?xml version='1.0' encoding='UTF-8'?> <domain type='kvm'> <name>pop-os</name> <uuid>d4e2a03b-c580-f7e2-50ce-629a924bbab4</uuid> <description>21.10</description> <metadata> <vmtemplate xmlns="unraid" name="Linux" icon="linux.png" os="linux"/> </metadata> <memory unit='KiB'>8388608</memory> <currentMemory unit='KiB'>4194304</currentMemory> <memoryBacking> <nosharepages/> </memoryBacking> <vcpu placement='static'>2</vcpu> <cputune> <vcpupin vcpu='0' cpuset='2'/> <vcpupin vcpu='1' cpuset='6'/> </cputune> <os> <type arch='x86_64' machine='pc-q35-5.1'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi.fd</loader> <nvram>/etc/libvirt/qemu/nvram/d4e2a03b-c580-f7e2-50ce-629a924bbab4_VARS-pure-efi.fd</nvram> </os> <features> <acpi/> <apic/> </features> <cpu mode='host-passthrough' check='none' migratable='on'> <topology sockets='1' dies='1' cores='1' threads='2'/> <cache mode='passthrough'/> </cpu> <clock offset='utc'> <timer name='rtc' tickpolicy='catchup'/> <timer name='pit' tickpolicy='delay'/> <timer name='hpet' present='no'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/user/domains/pop-os/vdisk1.img'/> <target dev='hdc' bus='virtio'/> <boot order='1'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/mnt/user/isos/linux/pop-os_21.10_amd64_intel_3.iso'/> <target dev='hda' bus='sata'/> <readonly/> <boot order='2'/> <address type='drive' controller='0' bus='0' target='0' unit='0'/> </disk> <controller type='usb' index='0' model='ich9-ehci1'> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x7'/> </controller> <controller type='usb' index='0' model='ich9-uhci1'> <master startport='0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0' multifunction='on'/> </controller> <controller type='usb' index='0' model='ich9-uhci2'> <master startport='2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x1'/> </controller> <controller type='usb' index='0' model='ich9-uhci3'> <master startport='4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x2'/> </controller> <controller type='sata' index='0'> <address type='pci' domain='0x0000' bus='0x00' slot='0x1f' function='0x2'/> </controller> <controller type='pci' index='0' model='pcie-root'/> <controller type='pci' index='1' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='1' port='0x10'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0' multifunction='on'/> </controller> <controller type='pci' index='2' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='2' port='0x11'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x1'/> </controller> <controller type='pci' index='3' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='3' port='0x12'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x2'/> </controller> <controller type='pci' index='4' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='4' port='0x13'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x3'/> </controller> <controller type='pci' index='5' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='5' port='0x14'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x4'/> </controller> <controller type='virtio-serial' index='0'> <address type='pci' domain='0x0000' bus='0x02' slot='0x00' function='0x0'/> </controller> <interface type='bridge'> <mac address='52:54:00:f6:79:45'/> <source bridge='virbr0'/> <model type='virtio-net'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </interface> <serial type='pty'> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> </serial> <console type='pty'> <target type='serial' port='0'/> </console> <channel type='unix'> <target type='virtio' name='org.qemu.guest_agent.0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='tablet' bus='usb'> <address type='usb' bus='0' port='1'/> </input> <input type='mouse' bus='ps2'/> <input type='keyboard' bus='ps2'/> <graphics type='vnc' port='-1' autoport='yes' websocket='-1' listen='0.0.0.0' keymap='en-us'> <listen type='address' address='0.0.0.0'/> </graphics> <video> <model type='qxl' ram='65536' vram='65536' vgamem='16384' heads='1' primary='yes'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x0'/> </video> <memballoon model='virtio'> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </memballoon> </devices> </domain> I've tried connecting to the VNC session via the built in Unraid web browser approach and also alternatives like Tight VNC viewer. Any help is appreciated! Thanks, Greg
-
I've verified that making this modification dropped my docker.img from 92% down to 66%. I have not attempted to connect to the server and will not be able to till after work or tomorrow but can report back. Thank you again ich777 and JonathanM. I would not have figured this out without the two of you
-
Noted, I'll hold off on mapping anything. I'll attach the output of that command as requested. So, I may have some information that will help here. I did not experience any issues when I was running the Pavlov VR server using the default maps. Now this is just based on my observations, but the problem seemed to start to arrive when I started experimenting with community maps, hosted on the Steam Workshop. I was talking to the community a bit, as I was running into an issue, and they informed me that the directory `/tmp/workshop` is where community maps will be downloaded to. I imagine this is what we're observing here. EDIT: Just noticed you replied while I was writing my initial reply. Looks like we're on the same page. I downloaded the maps two different ways. 1. Using rcon to trigger a MapSwitch, specifically using a command like `SwitchMap UGC[workshop map id] [game mode]` 2. Configuring the `/serverdata/serverfiles/Pavlov/Saved/Config/LinuxServer/Game.ini` to contain workshop map IDs I believe both 1 and 2 above will trigger the application to go fetch the map data and store it in `/tmp/workshop/ output.txt
-
Oh woops, you're absolutely right. I totally overlooked that. So I should be able to stop the Pavlov container, mount some directory from the host OS to the Pavlov container, say a newly made share. Then when I start the Pavlov container, it should notice that its `/tmp` directory is empty and redownload everything, I believe? My only other outstanding question is, if the above works and "stops the bleeding", is there any easy way to reduce the storage that was accidentally written to my `docker.img` file? Thanks for your help on this, you both have made exploring self hosting a game server a really rewarding experience.
-
Sure thing, here's the output: 6.1M /bin 0 /boot 0 /dev 1.9M /etc 0 /home 13M /lib 6.2M /lib32 4.0K /lib64 0 /media 0 /mnt 8.0K /opt 0 /proc 32K /root 4.0K /run 4.2M /sbin 2.5G /serverdata 0 /srv 0 /sys 4.9G /tmp 174M /usr 26M /var So are you thinking that the data in the Pavlov VR container's `/tmp`, somehow got written to my unraid's `docker.img` file, on the host OS?
-
Okay, understood. I don't believe I've modified anything in the template that would cause this issue, but I will attach a full screenshot for completion. The only modifications that I made was to the ports. Perhaps I've mis-configured something on my entire Unraid server itself and this doesn't have to do with the Pavlov template specifically?
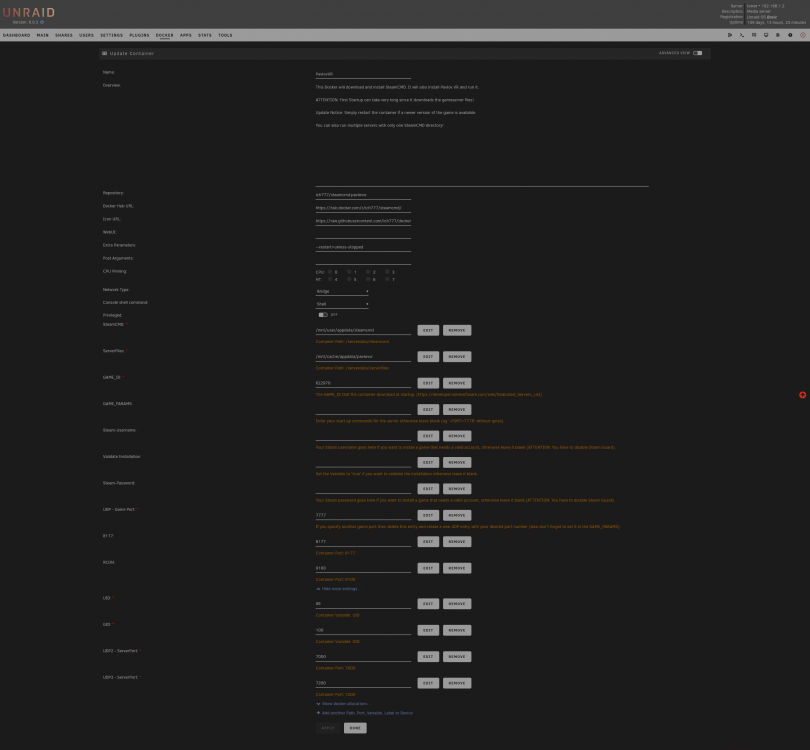
-
@ich777 One more follow up question. I have been playing with the Pavlov VR server this afternoon and it has been an absolute blast. I've been downloading custom maps etc... I just noticed alerts from my Unraid server saying: > Warning: Docker high image disk utilization (at... After running `$ docker system df -v`, I've noticed that this container has been writing a lot of data to the `docker.img`. ``` CONTAINER ID IMAGE COMMAND LOCAL VOLUMES SIZE CREATED STATUS NAMES 0fae144b0f31 ich777/steamcmd:pavlovvr "/opt/scripts/start.…" 0 5.33GB 10 hours ago Exited (143) 10 minutes ago PavlovVR ``` Are there any specific volumes would should be aware of to create when playing with this image? IE, so that the large amount of disk space is say written onto the cache directory or the array itself, rather than in the `docker.img`?
-
Okay that makes sense, I was able to get rcon running as described. Thanks ich777 That makes sense, it didn't dawn on me that there's probably only one dedicated linux server for the game and I could just safely assume you're using that. Appreciate your explanation and help!
-
@ich777 That helps a ton, I should be able to easily follow this and recreate it, so a big thank you! Let me ask you this, how would one figure this out on their own, without resorting to asking on this thread? Is there some documentation that I may have missed? I ask because I've been resorting to exploring the container itself to try to see which ports are expected, what is running, etc. My whole exploration is based quite a bit on luck and exploration ha Thanks again, Greg
-
Is there any support for Rcon for Pavlov VR? Perhaps I'm unsure where to look for documentation for a specific game
-
Is git lfs still offered by this pack? I have it installed but seemingly do not have access to this tool


