




Redspeed93
Members
-
Joined
-
Last visited
-
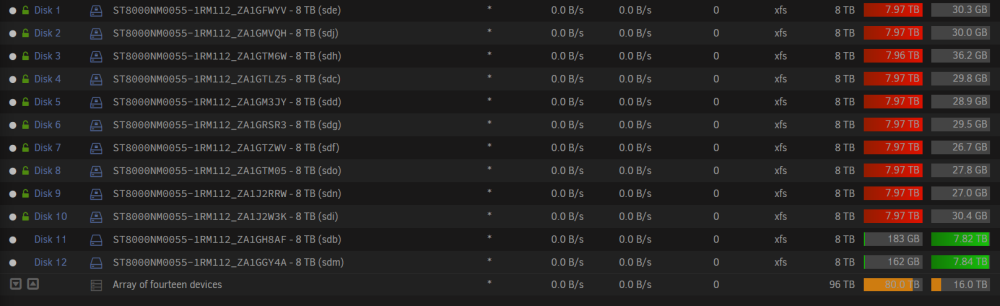
Some time ago I expanded my array with 2 more drives - and now I've just realized these are for some reason not encrypted like the rest of the pool. How do I get them encrypted as the rest of the pool and how do I avoid this happening next time I add new disks?
-
Can't write anything to influxdb - keep getting 204... [httpd] 192.168.1.107, 192.168.1.107,172.17.0.1 - root [31/Oct/2021:15:41:27 +0100] "POST /query?db=varken&epoch=ms HTTP/1.1" 200 57 "-" "Grafana/8.2.2" a0df45ab-3a58-11ec-813c-0242ac110006 369 ts=2021-10-31T14:41:27.218265Z lvl=info msg="Executing query" log_id=0XXhEm6W000 service=query query="SELECT count(distinct(hash)) FROM varken.\"varken 30d-1h\".Tautulli WHERE time >= 1635504903167ms AND time <= 1635677703167ms GROUP BY time(10m)" [httpd] 192.168.1.107, 192.168.1.107,172.17.0.1 - root [31/Oct/2021:15:41:27 +0100] "POST /query?db=varken&epoch=ms HTTP/1.1" 200 57 "-" "Grafana/8.2.2" a0df8b9f-3a58-11ec-813d-0242ac110006 356 [httpd] 192.168.1.100 - - [31/Oct/2021:15:41:32 +0100] "POST /write?db=telegraf HTTP/1.1" 204 0 "-" "Telegraf/1.20.2 Go/1.17" a3e07f00-3a58-11ec-813e-0242ac110006 31861 [httpd] 172.17.0.1 - root [31/Oct/2021:15:41:37 +0100] "POST /write?db=varken HTTP/1.1" 204 0 "-" "python-requests/2.21.0" a7101c85-3a58-11ec-813f-0242ac110006 25664 [httpd] 192.168.1.100 - - [31/Oct/2021:15:41:42 +0100] "POST /write?db=telegraf HTTP/1.1" 204 0 "-" "Telegraf/1.20.2 Go/1.17" a9d669d8-3a58-11ec-8140-0242ac110006 35903 [httpd] 192.168.1.100 - - [31/Oct/2021:15:41:42 +0100] "POST /write?db=telegraf HTTP/1.1" 204 0 "-" "Telegraf/1.20.2 Go/1.17" a9d669d8-3a58-11ec-8140-0242ac110006 35903 Any Ideas?
-
2 x LSI SAS-3 9300-8i + 1 x LSI SAS-2 9211-8i
-
No dice with -y or -Y for hdparm. Even though 12/14 drives are SATA (connected through HBA's).
-
hdparm sleep/standby does nothing to my disks. Looking at the log when manually spinning down a disk via gui simply shows "emhttpd: spinning down /dev/sd*" - but what command is used to do this spindown?
