




3doubled
Members
-
Joined
-
Last visited
-
I'm going to give this thread a nudge. I'm also looking at upgrading my Unraid server from an ancient i7 920. I'd really like to ensure Plex hardware transcoding is working well on the upgrade. I had my eye on Intel 11th gen as I've heard 12th gen is still a mess in Linux. Is 11th gen working well? ucliker, you said it "wasn't unstable", which didn't sound like a ringing endorsement. 4k to 1080p working well? HDR tone mapping? Otherwise, I'm assuming the CPU side of 11th gen should be fine, since it is just skylake ++++++ Thanks in advance.
-
Try: sudo -u abc php /config/www/nextcloud/occ maintenance:mode --off EDIT - path was incorrect before, fixed it. You can also change the maintenance value variable in config.php located at /appdata/nextcloud/www/nextcloud/config/ and reboot the docker.
-
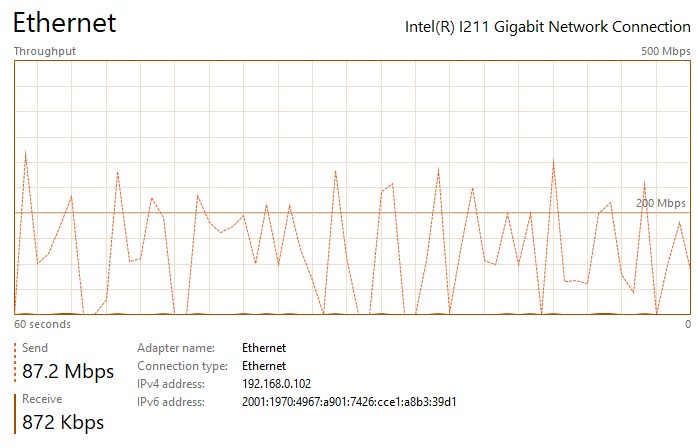
The spikes during upload transfer seem to be related to mysql performance. This person did some testing and was able to improve transfer speeds, especially for small files. The issue is that the biggest improvement comes from a change that is inherently less safe, so this is not a great option. Here is a 2.5 GB file being uploaded: This is the default with innodb_flush_log_at_trx_commit = 1 This is with innodb_flush_log_at_trx_commit = 2 This is with innodb_flush_log_at_trx_commit = 5 No other innodb setting change suggested in forums has made a significant impact, but that one certainly helps. Small file performance seems a bit better, but it still isn't great. The problem is that it weakens power loss protection so many suggest against this type of change. I still have no idea what is bottle necking the upper limit of performance, but there is obviously a beyond nextcloud issue here, as its also reported with owncloud.
-
I know this is an old thread, but I just wanted to add that excluding the \appdata folder in Dynamix Cache Directories and setting the max level depth to 8 greatly reduced the CPU spiking behavior for me.
-
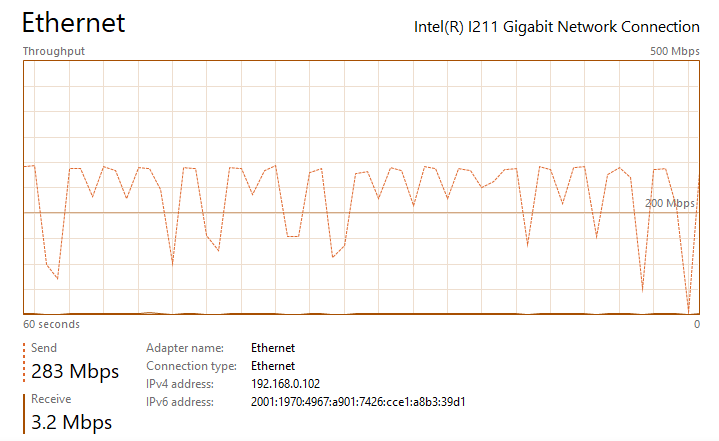
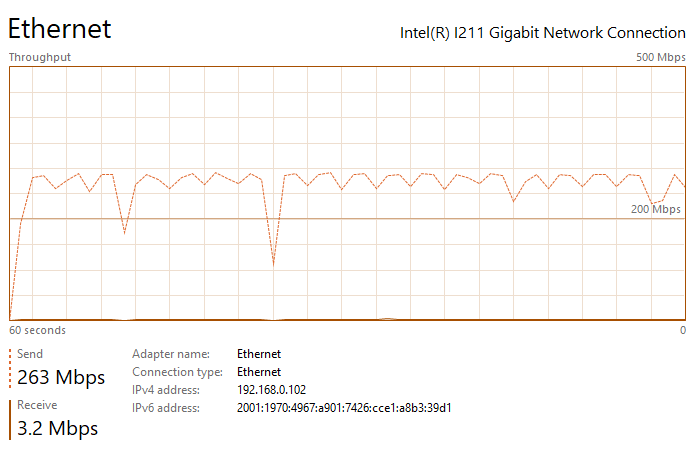
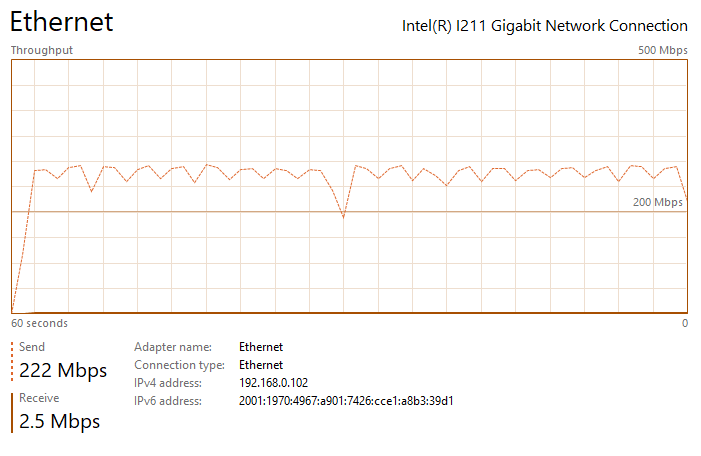
Thanks for the suggestion ufo56. I had actually tried implementing all of your suggestions a few days ago, but the Redis changes crashed NextCloud and caused an "Internal Error" message in the docker UI (I realized my mistake and noted it below). This time I went back and added your changes individually. All testing was done on an gigabit LAN either uploading to my nextcloud share, which writes to a SSD cache, or downloading to an SSD: The upload baseline is the following, I see peaks up to 200 - 260 mbps (~30 MB/s) during upload, but transfer is not very steady, so the overall speed isn't great. See the attached image network performance image below "Nextcloud Upload Before Changes.png". Pretty slow for SSD to SSD transfer over gbit connection. The download baseline is better, I see rather consistent transfer speeds of ~310 mbps (~38 MB/s). First I changed the proxy.conf file by adding or changing the following lines in \appdata\letsencrypt\nginx. I then restarted the LetsEncrypt and NextCloud dockers. After making this change, I saw no noticeable difference in file transfer speed and it had the same bursty behavior as illustrated in the image I referenced above. Next I implemented the php-fpm changes. I did this by adding the following lines to the end of the www2.conf file in /appdata/nextcloud/php, hopefully that was the correct place and manner to make the change. I then restarted the NextCloud docker. After making this change, I saw no noticeable difference in file transfer speed and it had the same bursty behavior as illustrated in the image I referenced above. Next I implemented the changes in php.ini. I did this by adding the following lines to the end of the php-local.ini file in /appdata/nextcloud/php, hopefully that was the correct place and manner to make the change. I then restarted the NextCloud docker. After making this change, I saw no noticeable difference in file transfer speed and it had the same bursty behavior as illustrated in the image I referenced above. Next I enabled the Redis cache. After installing RedisI made those changes in the config.php file in \appdata\nextcloud\www\nextcloud\config. A mistake I was making previously was that you must replace IP with your server IP. For some reason I thought it would automatically grab the IP. This error was causing the Internal Server Error issue I had earlier. I then restarted the NextCloud docker. With all of these changes in place, nothing has changed and I'm still seeing the bursty upload behavior. I am also noticing that the peak burst upload speeds fall off over time. After transferring a few GB, speeds have fallen by about 50%. See attached "Nextcloud Upload After Changes Steady State.png". If I pause, wait a couple seconds, and then resume, the transfer is restored to "full speed" again, see attached "Nextcloud Upload After Changes Pause and Restart.png". So there appears there may be two issues: My max download speed appears to be limited to ~310 mbps (~38 MB/s) My max upload speed is similarly limited, but it also bursty, with an average transfer speed between 100 and 150 mbps (~12 - 18 MB/s) Any additional thoughts would be greatly appreciated. Nextcloud Upload Before Changes.png Nextcloud Download After Changes.png Nextcloud Upload After Changes Steady State.png Nextcloud Upload After Changes Pause and Restart.png
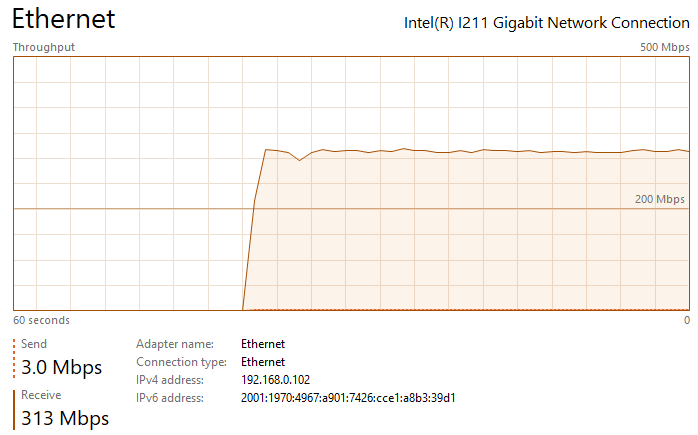
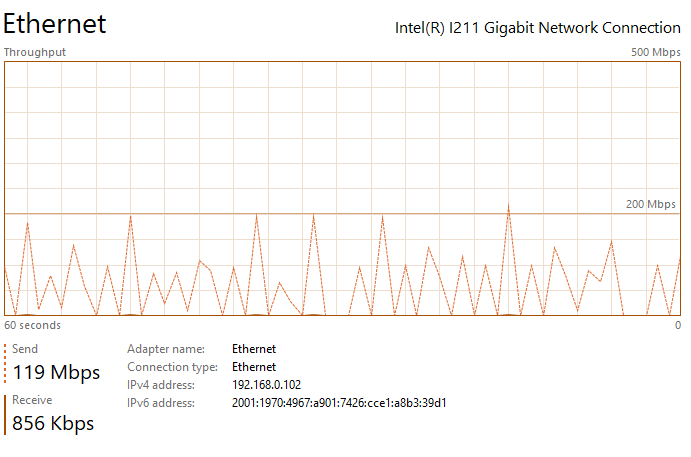
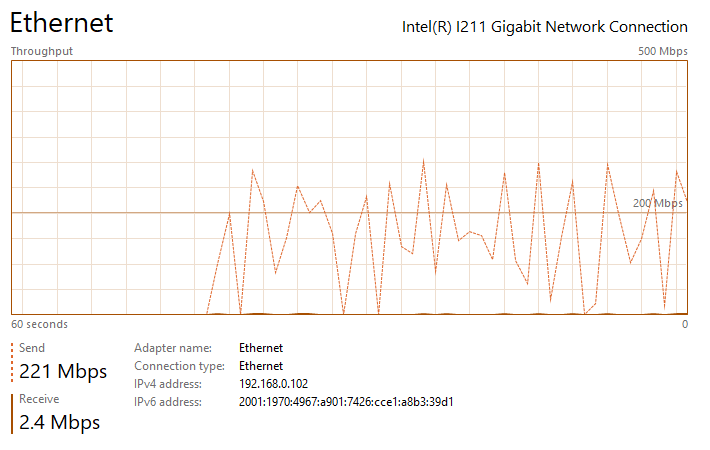
-
Hi all. I'm a new NextCloud user and I followed Spaceinvader One's great video tutorial (Thanks Spaceinvader One!). I managed to setup NextCloud and the reverse proxy OK (it's functional), but I'm seeing speeds between KB/s and low MB/s speeds when either uploading or downloading files to/from NextCloud on a gigabit local network. If I copy the same files using file explorer in Windows, I hit 80 - 90 MB/s when uploading to the Unraid server shares directly (no cache). When I Google around, I see people reporting NextCloud speeds in the 80 - 90 MB/s range, so it seems something is wrong. Here is what I've speculated is the problem: There could be a problem with my reverse proxy setup, such as: Slow HTTPS encryption bottle-necking performance??? My desktop is failing to make a direct LAN connection with NextCloud and is going to the internet to reach my server. Even if I try to connect to NextCloud directly using the IP address, it is always resolved to the duckdns address I setup. Database performance related NextCloud is recommending I install Redis - which I can't seem to configure properly without breaking the NextCloud Server (I get a Internal Server Error 500 message. I was having some file locking errors initially, but these seem to have gone away for now. Any help would be much appreciated. If it would help to see any configuration files, please let me know which.
-
Thanks everyone for the help, especially aptalca, I found the backups and was able to restore to a previous date and the library is now updating. Thankfully Plex was automatically creating those backups. I'll checkout trakt.tv too. Cheers.
-
Thanks. Is there no way to just fix the corruption? I don't have a backup stored. If not, then how could I cause Plex to rebuild the database? Should I just delete the appdata and start again like I did last time. That's an ok fix, but kind of annoying since I lose all of the watched/unwatched info, which is what I'm hoping to avoid. Thanks
-
I hope everyone is having a great weekend. I'm having trouble with my Plex server docker where it refuses to update the library. I've added several files to the watched folders, but they are all ignored. This occured around the time that my cache disk filled up, and I think it might be connected, as this happened a few months back and the only way I could solve the problem was to rebuild the plex server. Thus far, I've tried the scan, optimize, clean, empty trash options in the Plex server GUI. I've tried refreshing metadata (no luck so far). I've deleted the docker image and installed a new one (25 GB this time, in case that helps). Also, I've noticed that playing a file through Plex, even on my local network, take about 10 - 20 sec to load. It used to be instantaneous. I'm not sure if this is connected with the new player or the issue with my server. Short of building the server from scratch again I'm out of ideas, I'm hoping there is a better solution. I've attached my log file. Please let me know if there is anything else I can share. Thanks! Plex Media Server Logs_2018-03-24_19-08-05.zip
-
So the preclear on that 2TB EARS drive failed again. This time I used "preclear_disk.sh -A /dev/sdX" as I mentioned in my previous post. I've attached the preclear output, please let me know what you think. I'm thinking this drive is unreliable and I'll have to RMA it. It is especially annoying that when it freezes up, I have to reboot the server to gain access to it again. I've also attached the SMART report from the beginning of the preclear. I don't think there is much of interest there other than the "not in smartctl database" error... but I'll leave the final judgment to the experts. I also might add that this drive is connected to a Supermicro AOC-SAT2-MV8. Thanks! **Edit** I just took a look at my syslog and I've got a ton of red lines. I'd attach my full syslog, but it is 624MB (and growing). It just keeps repeating the same set of errors many times a second. I can't even open the .txt file its so large. I can tell from the log that it is coming from /dev/sdb... which is that 2TB EARS drive. Could these errors just be the result of the drive being non-responsive? Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x41/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x41 { DriveReady Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x41/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x41 { DriveReady Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x41/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x41 { DriveReady Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x41/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x41 { DriveReady Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x41/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x41 { DriveReady Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x41/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x41 { DriveReady Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x41/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x41 { DriveReady Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x41/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x41 { DriveReady Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x51/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x51 { DriveReady SeekComplete Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x51/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x51 { DriveReady SeekComplete Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x51/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x51 { DriveReady SeekComplete Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x51/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x51 { DriveReady SeekComplete Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x51/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x51 { DriveReady SeekComplete Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) Feb 8 10:53:27 Tower kernel: ata1: translated ATA stat/err 0x51/04 to SCSI SK/ASC/ASCQ 0xb/00/00 (Drive related) Feb 8 10:53:27 Tower kernel: ata1: status=0x51 { DriveReady SeekComplete Error } (Errors) Feb 8 10:53:27 Tower kernel: ata1: error=0x04 { DriveStatusError } (Errors) 2TB-EARS-FAIL.txt smart_start_sdb.txt
-
Cool! I'm glad a few hours of me banging my head against the desk amounted to something useful for a change Thanks for all your hard work on this script, it is a great program!
-
I am running 4.7. The preclear using the -A option is now running, I will let you know whether it is successful or whether it ends in an error like the last attempt using the old (ancient?) preclear script. My fingers are crossed.
-
Thanks for your quick response Joe L.! It appears the version of preclear was very old... before the -v command was implemented. Only the -n, -t, and -c commands are available in that version. I should have mentioned that by rebooting I regained access to the EARS drive and that the following problems occur while the disk is responsive. I have attached a log of performing fdisk -l, hdparm, preclear_disk.sh -t, then preclear_disk.sh -A. From this log you will see that using the -A command results in the above mentioned smartctl error. Calling the preclear script without -A works fine. Should I preclear without the -A and then use the -C 64 command to convert the disk? *EDIT* By using the command "preaclear_disk.sh -D -A /dev/sdX" I was able to circumvent the smartctl error. Immediately I said "No" to a preclear and tried "preaclear_disk.sh -A /dev/sdX", which also miraculously worked, despite it previously not working (see the attached logs). Thanks for your help Joe L., if anything funny was going on I hope I supplied you with enough information for you to understand what it was. 2TB-EARS-Preclear-Trouble.txt
-
I'm having a cascade of problems today. Besides realizing I have a 2TB seagate drive that requires a critical update to CC35 (don't know why though) and a Gigabyte board that has added HPA sectors to one of my hard drives... I also have a funny WD 2TB EARS drive. The topic of this post will pertain to the EARS drive: I originally installed the 2TB EARS drive with NO jumper. I precleared using an older version of preclear (<< 0.9.9) and didn't take the Advanced Format aspect of the EARS drive into consideration (sector 63, not 64). Everything went fine and I added the drive to my array (I believe Unraid 4.6 at the time). Fast forward to the other day, when a red dot and a message "disk invalid" appeared next to the drive in the unraid menu. I happened to be preclearing another 2 TB EARS drive (again, NO jumper, sector 63). This drive precleared OK and I swapped the disks in the array. Attempting to discover whether the first 2 TB EARS disk was bad or not, I attempted to preclear (NO jumper, sector 63) and the preclear failed with the following error messages (sorry I didn't copy the whole log at the time, just the errors and they are not in order): dd: reading `/dev/sdb': Input/output error > 0+0 records in > 0+0 records out > 0000000 > 0 bytes (0 B) copied, 0.00222053 s, 0.0 kB/s > dd: writing `/dev/sdb': Input/output error Restarting udevd BLKRRPART: Input/output error Following this error, I attempted to run preclear again, but the disk no longer reported and all that was returned was two rows of asterisks with nothing between them. Afterward I went searching for similar problems in the forums and I happened upon the whole Advanced Format discussions. I updated my preclear script, updated to Unraid 4.7, and attempted to preclear the dodgy 2TB EARS drive again. Under these conditions, with or without the -A option, I get the attached output saying my drive is not recognized (in both smartctl 5.38 and 5.39). If I run the old preclear script, I do not get this error. Is this drive broken? Why does the old preclear script not return the same smartctl error? How can I identify what version the old preclear script is? Thanks in advance! preclear-output.txt







