




ephigenie
Members
-
Joined
-
Last visited
Everything posted by ephigenie
-
Ok i have thank you - with your help its figured out now. Now for everyone who faced the same issue - just to document it : With Perc 710 controllers - whereas the single disk was configured as a virtual disk you need to do the following, assuming you have to change more than 1 disk in a row - because i.e. like in my case with a poweredge T620 the drive cage is 2 x 4 drives connected via a 4i cable each so no way to take them separate. 1) make a screenshot of your (old) config & names then shutdown 2) change your cabling ( i.e. 4 disks at once ) 3) start unraid up again - it will complain too many disks are missing ... 4) make sure you see all your 4 disks but with (partition not readable / supported ) 5) go to tools -> new config 6) run sgdisk -o -a 8 -n 1:32K:0 /dev/sdX ( as in X is each disk so 4 times ) for those 4 disks that are not readable 7) run xfs_repair /dev/sdX1 afterwards try to start the array ( with the new config ) 9) it should be fine now, if not reboot once. 10) repeat step 1-9 with the 2nd batch of disks 11) good luck. This has been tested with PERC / DELL raid controllers
-
Ah well - you mean to say i shall remove unraid and install a windows server to get the GPT partition table right in order for unraid to recognize it? - that sounds funny No i mean the disks are already formatted with XFS and i can mount them manually inside unraid. Just the partition layout for some reasons doesn't seem to fit. That is the challenge. I have transferred files now to an unassigned standalone HDD from 2 disks ( 8TB & 16TB ) . After the transfer i did "sgdisk -o -a 8 -n 1:32K:0 /dev/sdX" on those disks and ran an xfs_repair /dev/sdX & reboot. Eventually i started as well the mkfs.xfs /dev/sdX just to get the error message ( partition already has a live XFS filesystem ). At some point after a reboot the partitions were recognized and i could add them into the config. I am about to finish the transfer back for the 16TB disk so 2 out of 8 are fixed now. After the 16tb disk i will try a different approach. Copying these amounts of data around is taking weeks.
-
Thanks for the tip - but also did not work out. I think Unraid sets somewhere a magic byte in the GPT header. Tried to find it with sleuthkit already - but could not find it so far - i can only say that all gpt headers created from unraid look slightly different then the ones created outside. in 2 Bytes. The other cylinder alignment etc pp are all the same. Update: Tried again - copied the files over from one of the drives to a new drive. Now i am trying to format that drive and let it be recognized in unraid. Still it does not recognize the disk.
-
Thanks for the tip - but also did not work out. I think Unraid sets somewhere a magic byte in the GPT header. Tried to find it with sleuthkit already - but could not find it so far - i can only say that all gpt headers created from unraid look slightly different then the ones created outside. in 2 Bytes. The other cylinder alignment etc pp are all the same.
-
Yeah ok - thats unfortunately not possible - since the cabling is via minisas 4i (Dell 620T - 8x3.5 case ) - so it's going to be 4 disks at a time. Exactly the scenario i have right now.... Is there no reasonable explanation as to what exactly unraid is looking for in the partition layout ? Could not be more than a few bites set at the right point?
-
If i mount i.e. my disk1 ( sdg1 ) to /mnt/disks1/disk1 manually : The mount message is the same ( again rightfully seeing V5 Xfs etc ) ... This is what i see for those disks... The parity drive (which works) with fdisk -l /dev/sdo root@bob:~# fdisk -l /dev/sdo Disk /dev/sdo: 14.55 TiB, 16000900661248 bytes, 31251759104 sectors Disk model: ST16000NM001G-2K Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: 0013AD91-3326-4479-A772-A0AFE8D4BBCA Device Start End Sectors Size Type /dev/sdo1 64 31251759070 31251759007 14.6T Linux filesystem and a similar size but not working : root@bob:~# fdisk -l /dev/sdg Disk /dev/sdg: 14.55 TiB, 16000900661248 bytes, 31251759104 sectors Disk model: TOSHIBA MG08ACA1 Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: A1FEB878-5764-4167-91F8-AC9C8F88EC9C Device Start End Sectors Size Type /dev/sdg1 64 31250710494 31250710431 14.6T Linux filesystem cfdisk is showing the 512M at the end of the disk Now i am aware of course i can just reformat and then lose all my data and be done with that ... but that would be quiet the hassle. I also think i could in theory buy another 16TB drive, mount it into unassigned devices, format it - then mount one of my old drives - copy everything over than format the old drive and add it - but its a lengthy exercise ( with in total 8 drives ). Would be great if that can be shortened somehow. Update: I have ordered another Toshiba 16TB disk - but anyone can help please and explain the difference in the partition layout? bob-diagnostics-20240403-0018.zip
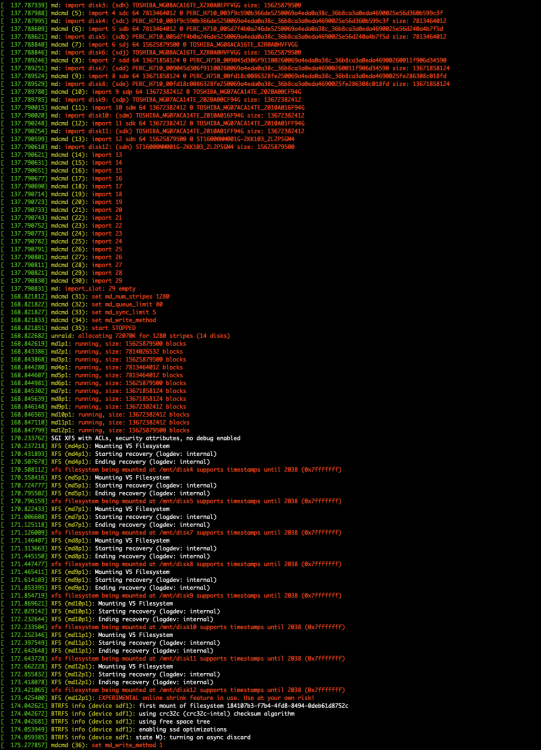

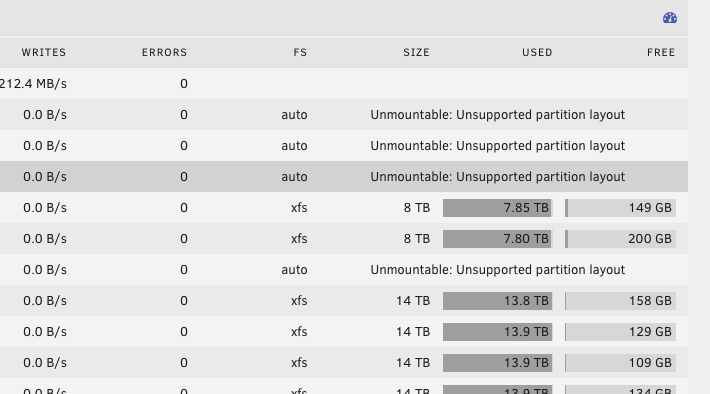


-
Needless to say in the above screenshot you can still see 4 more drives having the DELL naming ... those are coming as well over ( still on the old controller ) . For some reason i think technically it should be absolutely do-able to get unraid to mount and recognize the disks again. I will deep dive a bit more into what kind of partition layout unraid is formatting the other disks. In order to manipulate this disks to undergo the same layout.
-
soooo i got into the situation now ... that i have replaced the controller. But i cannot get them to mount into unraid as part of the Array. However i can mount separately individually without any issue... Any recommendations ? Below my old config with the perc710 controller (now i am using a 24i - 9306 or so LSI based controller ) Unfortunately now however - although the partitions look almost the same, it is saying "unknown partition layout" cannot mount. However on the command line i can mount them individually - so all my data is there. Now i would love to know what partition information / schema Unraid exactly is looking for - so i can change the disks partition layout. I mean start sectors are quite the same - just at the end seems there is a 512MB patch free that the other native unraid formatted disks dont have. All disks have UUID and actually show XFS as well here. Any ideas anyone ? I mean i have all my data still there ... ?
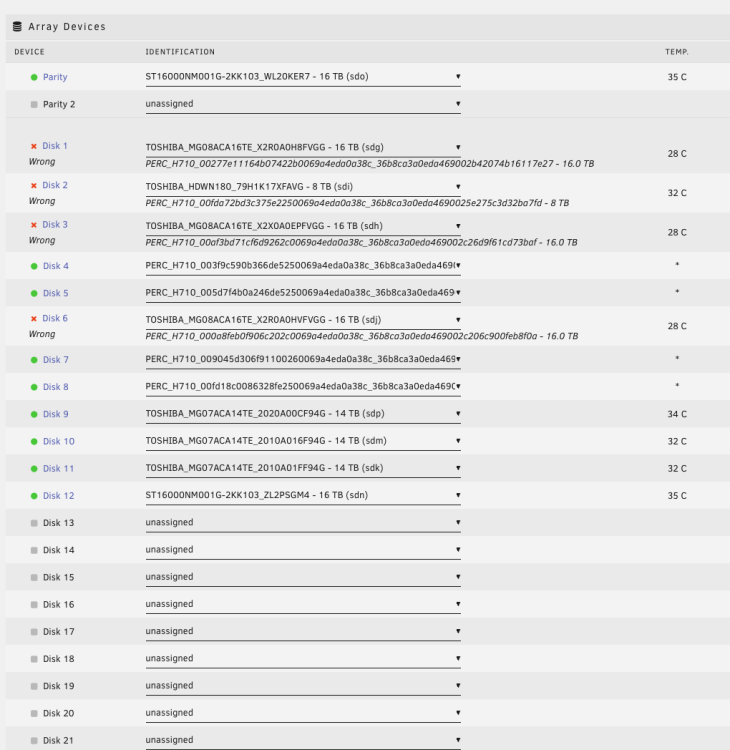
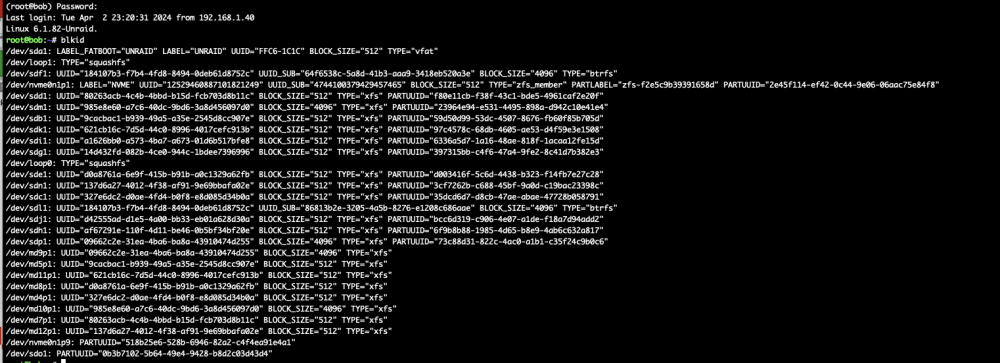
-
Hi, I have a fairly populated Unraid Server with approx 15drives so far. Those are distributed across 2 controllers. One of them is a legacy DELL Controller in NON-IT mode and the other one an updated IT mode SAS Controller. Now I have reached the point I need to add some additional disks via external DAE and want to add more controllers, but have not enough slots so I am forced to think about optimization of the current setup. My plan would be now to i.e. replace the existing controllers with this : SAS9305-24i LSI 9305-24i Logic Controller Card IT Mode 24-Port SAS 12Gb/s However - the naming is an issue of course. Now is there a "scan" feature available that would make Unraid recognize a disk ( its signature) although the name has changed ? Obviously that would only affect the disks connected as individual raid0 on the dell controller, the 7 disks on the IT mode controller would remain unchanged name wise and be recognized ( I assume ) . I am aware the whole idea and why its not recommended to use those raid controllers without the pass-through "IT" mode is for exactly this scenario (be independent of the controller) ... But such is life. Now I am searching for a solution. Anyone has a hint?
-
Same of me. Any update on this ? Tried setting the NVIDIA_DRIVER_CAPABILITIES & NVIDIA_VISIBLE_DEVICES flag for the container - but no chance
-
Did you try looking with IOtop which process is causing the amount of IO ? Can you trace it as well with docker stats across your containers ? Just to try to identify the verdict....
-
Well in parts i can agree - individual filesystems are an advantage. Unfortunately what i have seen while debugging shfs: is its highly unefficient. This and then along with the "mover" is causing a lot of issues. I get, that the overhead in IO is caused by being extra-cautios and double check everything. However since the approach of array configuration is not extendable during live operation as well as cache... The "only" configurable thing that is actually causing most of the confusion are the settings around the cache. And the involvement of the mover. To this part i would not understand why i.e. its not possible to make that a transition process, whereas upon all criterias are being fullfilled, a "progress - meter" can show the status of the transition. i.e. I change a share from "prefer" to "cache only" : nothing happens in terms of the mover. ( isn't that unexpected ? ) ? Given that the others : i.e. i change a share from "use cache" to "prefer" : the data will be copied from the array to the cache. But based on what pattern ? MRU ? LRU ? Specially the case of a share being converted to be "cache only" has some of the biggest problems in terms of workflow. Why not stop VM's & Docker and trigger a move by some i.e. rsync based tool on the shell ? Later on - even your share is still "cache only" SHFS triggered by the mover will still insist on over and overly seeking the share's FS on ALL disks. Something that definitely would need to be avoided in order to give the cache some sort of decent performance. Otherwise the disks that are supposed to be relieved are still needed for every run. And i validated this with strace ........ In terms of Cache & ZFS : Why would i not prefer having i.e. snapshots or a block wise cache ? I think there is almost no reason. in terms of different HDD sizes on ZFS : no issue at all. multiple arrays are possible as well.
-
You can try creating a raid1 / raid0 out of your 2 SSD's and putting XFS on top. Everyone please read: - https://en.wikipedia.org/wiki/ZFS ... - uptown triple-device parity per pool - of course multiple pools per host - builtin encryption - live extension - builtin deduplication - builtin hierarchical caching ( L1 Ram, L2 i.e. SSD ) blockwise and without possible data loss if the cache device dies with cache devices being able to be added and removed live and separate cache for fast write confirmation ( SLOG) - builtin "self-healing" - Snapshots... Only downside pools cannot be easily downsized. Really in short 98% of everything we dream about. I for myself like the comfort of the interface, VM and Docker handling, Ease of configuration of NFS, SMB etc And virtually none of that would fall apart. Filesystems are hugely complex beasts. And the amount of Forum entries here that are connected to performance issues of SHFS / mover are really a lot.
-
No. If you would look at their latest blog - and the video that was posted there - you would see that they are indeed considering ZFS. And i can tell you from my analysis - of the SHFS processes via strace and its behavior, that SHFS in itself has big issues performance wise. Guess why plugins like the directory cache and others exist. ZFS is the superior file system and it has decent Caching (block wise) build in amongst other features such as i.e. Snapshots, Raid etc. .. So imagine we would have the performance of XFS with the flexibility of BTRFS and snapshots and something like "dm-cache" build in. But all with the nice interface of Unraid and the easy handling of Docker Containers and VMs etc ... With ZFS on top, multiple pools wouldn't be an issue. Not to mention the amount of attention that any BUG in ZFS has in the worldwide community. Whereas if there is a serious bug in SHFS - its only in the hand of a few - and writing a filesystem is a very sophisticated task that needs a lot of time and resources. We would all profit from it - as well as LT. vid in question : https://unraid.net/blog/upcoming-home-gadget-geeks-unraid-show
-
Wow quit the impressive difference for you! Glad the change to XFS worked out for you. All the best! And yes i hope they will throw away this SHFS asap and replace it all with ZFS.
-
ok i just read the beginning of the thread again. Basically you have made sure already your "docker.img" is now inside the cache. The same should be done for the "appdata" shares as it contains all the data of your docker images. Next issue would be : SAB shouldn't impact anything else then the drive you chose to dedicate to it. That being said, in my setup, where i also heavily rely on sab, it is a very potent piece of software with extremely high IO demand. I have setup a separate box with a 4 x 2TB raid10 as download server with its / on SSD. In the earlier days, the box was unpacking on the SSD - however i quickly run out of space. With the 4 x 2TB disks - SAB is easily downloading faster then i can unpack - and the download box is fully IO - Saturated. Depending on what performance levels you might want to achieve - you might have to migrate your SAB to an additional SSD.
-
you have to set your system share and appdata share to prefer. Then switch off docker. Run the mover. Once it is finished, verify the following way: ls -al /mnt/cache/system/docker/docker.img exists ? and it doesn't exist at all on your normal disk drives! so i.e. ls -al /mnt/disk1/system/docker/docker.img doesn't exist. you can as well copy the system directory with i.e. "mc" directly to /mnt/cache/ Once you have done that and there is no more "system" and no more appdata directory on any of your /mnt/disk* directories (except for /mnt/user - where all your devices in the pool are merged ) start your docker again. See if you have a difference in your system performance. I still have at least 1 core busy with "chefs" when i.e. plex is doing a scan - or anything else similar is happening - but the system stays responsive and is not totally drowning in IO .
-
@CowboyRedBeard I found something quit interesting, that might be affecting you as well. So first things first - after debugging the heck out of my box - i found that while it wasn't immediately visible, my docker containers were competing with the "mover" . While the Issues with the mover persist (very inefficient IO as it seems), i found, despite what i was initially thinking, the docker.img was still persistent on my array. So what i wasn't fully aware of, was that when i put the appdata share on "cache only" literally the mover is not doing anything with it (in terms of moving anything). So i solved the full lock down from the mover with : 1) disabling docker 2) set the share for "cache prefer" 3) run the mover, waited until everything moved to the cache 4) scubbed the cache drives, run the mover again just to be sure 5) switched the share back to "cache only" 6) started the Docker again 7) started testing - the mover IO issues are still existing - however my wait IO went absolutely down to max 10 my docker containers started nicely - and are completely unaffected from the mover now. Now the conclusion : 1) the Samsung SSD's are not at fault 2) docker.img on the Array is leading to an IO deadlock. 3) i just watched the video from 9th of April and they wanna switch to ZFS - so i'll wait for that to come since that would def. outperform shfs by far and is much more efficient. For you : check the location of your docker.img at first. Its not being moved if the docker service is still running... (same for any VM's)
-
This seems related. at this point in time my mac mini with 3 simple WD NAS (each Raid1) attached no cache - was at least 10 times faster then the supposed to be monster server with dual xeon, 2TB SSD cache, P2000 etc... And not seeing any feedback, not even a question from LT is really dissapointing. I used mergerfs before and it was working really nice. I am really wondering what is so different now - except that by design my hardware is much more capable then what i had before - yet i am unable to achieve even close to the similar performance. My server is unable to stream a single movie locally. Everything is stuck.
-
Any update on this please please ? strace -fF -p 43726 -e lstat : running for 1 sec. : [pid 31881] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31881] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk2/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk7/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33810] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33810] lstat("/mnt/disk2/appdata", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/appdata", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/appdata", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/appdata", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33810] lstat("/mnt/disk7/appdata", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/appdata", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/appdata", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/appdata", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/domains", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31856] lstat("/mnt/disk2/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/domains", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31876] lstat("/mnt/disk2/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/domains", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk2/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/domains", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk2/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/domains", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33805] lstat("/mnt/disk2/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/domains", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/files", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33805] lstat("/mnt/disk2/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/files", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33805] lstat("/mnt/disk2/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/files", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/files", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk2/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/files", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk2/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/files", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk2/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/isos", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33798] lstat("/mnt/disk2/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/isos", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31880] lstat("/mnt/disk2/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/isos", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31868] lstat("/mnt/disk2/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/isos", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33799] lstat("/mnt/disk2/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/isos", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33805] lstat("/mnt/disk2/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/isos", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31881] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31881] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31881] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31881] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31881] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31881] lstat("/mnt/disk6/media", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31881] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31881] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31881] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33810] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33810] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33810] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33810] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33810] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33810] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33810] lstat("/mnt/disk6/media", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33810] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33810] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33810] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31856] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31856] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31856] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31856] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31856] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31856] lstat("/mnt/disk6/media", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31856] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33798] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33798] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33798] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33798] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33798] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33798] lstat("/mnt/disk6/media", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33798] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31880] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31880] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31880] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31880] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31880] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31880] lstat("/mnt/disk6/media", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31880] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31868] lstat("/mnt/cache/music", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/music", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/music", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/music", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31868] lstat("/mnt/disk5/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/music", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/music", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/music", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/music", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31868] lstat("/mnt/disk5/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33799] lstat("/mnt/disk5/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/music", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/music", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/music", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/music", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31881] lstat("/mnt/disk5/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/music", 0x150a1c469c00) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/music", 0x150a1c469c00) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk2/music", 0x150a1c469c00) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/music", 0x150a1c469c00) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33810] lstat("/mnt/disk5/music", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/music", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/music", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/music", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/music", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/music", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/system", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31856] lstat("/mnt/disk2/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/system", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31876] lstat("/mnt/disk2/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/system", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/system", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 33798] lstat("/mnt/disk2/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/system", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31880] lstat("/mnt/disk2/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/system", 0x150a4c8c2c00) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31880] lstat("/mnt/disk2/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/system", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server", {st_mode=S_IFDIR|0755, st_size=218, ...}) = 0 [pid 33799] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server/Plug-ins", {st_mode=S_IFDIR|0755, st_size=30, ...}) = 0 [pid 33805] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server/Plug-ins", {st_mode=S_IFDIR|0755, st_size=30, ...}) = 0 [pid 33805] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33810] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31876] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33798] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31874] lstat("/mnt/cache/appdata/upstatsboard", {st_mode=S_IFDIR|0755, st_size=18, ...}) = 0 [pid 31874] lstat("/mnt/disk1/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata/upstatsboard", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31880] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33799] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31881] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33805] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31874] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)", {st_mode=S_IFDIR|0755, st_size=96, ...}) = 0 [pid 31874] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)", {st_mode=S_IFDIR|0755, st_size=119, ...}) = 0 [pid 31874] lstat("/mnt/disk10/media/Movies1/Killing Oswald (2013)", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31880] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 33799] lstat("/mnt/cache/appdata/bazarr/app", {st_mode=S_IFDIR|0775, st_size=32, ...}) = 0 [pid 33799] lstat("/mnt/disk1/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/appdata/bazarr/app", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/appdata/bazarr/app/db", {st_mode=S_IFDIR|0775, st_size=18, ...}) = 0 [pid 31881] lstat("/mnt/disk1/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/appdata/bazarr/app/db", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/appdata/bazarr/app/db/bazarr.db-journal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/appdata/bazarr/app", {st_mode=S_IFDIR|0775, st_size=32, ...}) = 0 [pid 31881] lstat("/mnt/disk1/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/appdata/bazarr/app", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/appdata/bazarr/app/db", {st_mode=S_IFDIR|0775, st_size=18, ...}) = 0 [pid 31876] lstat("/mnt/disk1/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/appdata/bazarr/app/db", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db", {st_mode=S_IFREG|0644, st_size=14925824, ...}) = 0 [pid 33799] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 33799] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 33799] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33799] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33799] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 33799] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33799] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 33799] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33799] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33799] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33799] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 31856] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 31856] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 31856] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 31856] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 33810] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 33810] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 33810] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 33810] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31876] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31874] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31868] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 33799] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 33805] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31856] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31856] lstat("/mnt/disk2/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31856] lstat("/mnt/disk7/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31881] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk2/appdata", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/appdata", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/appdata", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/appdata", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk7/appdata", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/appdata", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/appdata", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/appdata", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33810] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33810] lstat("/mnt/disk2/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33810] lstat("/mnt/disk7/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33798] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk2/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk7/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31874] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31874] lstat("/mnt/disk2/appdata", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31874] lstat("/mnt/disk7/appdata", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/domains", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk2/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/domains", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31880] lstat("/mnt/disk2/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/domains", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/domains", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33799] lstat("/mnt/disk2/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/domains", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/domains", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31856] lstat("/mnt/disk2/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/domains", 0x150a4c259c00) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk2/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/domains", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/files", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk2/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/files", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/files", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk2/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/files", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/files", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/disk2/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/files", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/disk2/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/files", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/files", 0x150a4c8c2c00) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31880] lstat("/mnt/disk2/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/files", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/isos", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33799] lstat("/mnt/disk2/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/isos", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33805] lstat("/mnt/disk2/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/isos", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/isos", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31856] lstat("/mnt/disk2/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/isos", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31856] lstat("/mnt/disk2/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/isos", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/isos", 0x150a4c259c00) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31881] lstat("/mnt/disk2/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/isos", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31881] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31881] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31881] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31881] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31881] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31881] lstat("/mnt/disk6/media", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31881] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31881] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31881] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31868] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31868] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31868] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31868] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31868] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31868] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31868] lstat("/mnt/disk6/media", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31868] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31868] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31868] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31874] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31874] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31874] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31874] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31874] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31874] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31874] lstat("/mnt/disk6/media", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31874] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31874] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31874] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31880] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31880] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31880] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31880] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31880] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31880] lstat("/mnt/disk6/media", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31880] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33805] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33805] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33805] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33805] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33805] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33805] lstat("/mnt/disk6/media", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33805] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33810] lstat("/mnt/cache/music", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/music", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk2/music", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/music", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33810] lstat("/mnt/disk5/music", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/music", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/music", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/music", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/music", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/music", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/music", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/music", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/music", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/music", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31876] lstat("/mnt/disk5/music", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/music", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/music", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/music", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/music", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/music", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/music", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/music", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/music", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/music", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31856] lstat("/mnt/disk5/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/music", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/music", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/music", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/music", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31881] lstat("/mnt/disk5/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/music", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/music", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/music", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/music", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/music", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31868] lstat("/mnt/disk5/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/system", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31868] lstat("/mnt/disk2/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/system", 0x1509d75bbc90) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 33799] lstat("/mnt/disk2/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/system", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/system", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31880] lstat("/mnt/disk2/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/system", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/system", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 33805] lstat("/mnt/disk2/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/system", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 33805] lstat("/mnt/disk2/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/system", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)", {st_mode=S_IFDIR|0755, st_size=96, ...}) = 0 [pid 31856] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)", {st_mode=S_IFDIR|0755, st_size=119, ...}) = 0 [pid 31856] lstat("/mnt/disk10/media/Movies1/Killing Oswald (2013)", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31881] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259b30) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31874] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31880] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 33810] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31876] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31876] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31856] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31874] lstat("/mnt/cache/appdata/bazarr/app", {st_mode=S_IFDIR|0775, st_size=32, ...}) = 0 [pid 31874] lstat("/mnt/disk1/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata/bazarr/app/db", {st_mode=S_IFDIR|0775, st_size=18, ...}) = 0 [pid 31868] lstat("/mnt/disk1/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/appdata/bazarr/app/db/bazarr.db-journal", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/appdata/bazarr/app", {st_mode=S_IFDIR|0775, st_size=32, ...}) = 0 [pid 31880] lstat("/mnt/disk1/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk2/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/appdata/bazarr/app", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/appdata/bazarr/app/db", {st_mode=S_IFDIR|0775, st_size=18, ...}) = 0 [pid 33805] lstat("/mnt/disk1/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/appdata/bazarr/app/db", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/appdata/bazarr/app/db/bazarr.db-wal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db", {st_mode=S_IFREG|0644, st_size=14925824, ...}) = 0 [pid 33798] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31881] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31874] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31868] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33799] lstat("/mnt/cache/appdata/upstatsboard", {st_mode=S_IFDIR|0755, st_size=18, ...}) = 0 [pid 33799] lstat("/mnt/disk1/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/appdata/upstatsboard", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33810] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33805] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31856] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31876] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33799] lstat("/mnt/cache/appdata/heimdall/www", {st_mode=S_IFDIR|0775, st_size=120, ...}) = 0 [pid 33799] lstat("/mnt/disk1/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/appdata/heimdall/www", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk2/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/appdata/heimdall/www/app.sqlite-journal", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/appdata/heimdall/www", {st_mode=S_IFDIR|0775, st_size=120, ...}) = 0 [pid 33805] lstat("/mnt/disk1/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/appdata/heimdall/www", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/appdata/heimdall/www/app.sqlite", {st_mode=S_IFREG|0664, st_size=233472, ...}) = 0 [pid 31881] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 31881] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 31881] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 31881] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 31881] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 31874] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 31874] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 31874] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 31874] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 31868] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 31868] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 31868] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 31868] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 33810] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 33805] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31856] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31876] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31876] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31876] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31876] lstat("/mnt/disk2/appdata", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/appdata", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/appdata", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/appdata", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31876] lstat("/mnt/disk7/appdata", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/appdata", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/appdata", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/appdata", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31868] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk2/appdata", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/appdata", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/appdata", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/appdata", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk7/appdata", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/appdata", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/appdata", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/appdata", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31880] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31880] lstat("/mnt/disk2/appdata", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/appdata", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/appdata", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/appdata", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31880] lstat("/mnt/disk7/appdata", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/appdata", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/appdata", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/appdata", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33810] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33810] lstat("/mnt/disk2/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33810] lstat("/mnt/disk7/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/appdata", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33805] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33805] lstat("/mnt/disk2/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33805] lstat("/mnt/disk7/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/domains", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31856] lstat("/mnt/disk2/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/domains", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/domains", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk2/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/domains", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/domains", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk2/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/domains", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31876] lstat("/mnt/disk2/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/domains", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/domains", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk2/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/domains", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/files", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk2/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/files", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/files", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk2/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/files", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/files", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk2/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/files", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/files", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk2/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/files", 0x150a4c259c00) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31881] lstat("/mnt/disk2/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/files", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/isos", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31874] lstat("/mnt/disk2/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/isos", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/isos", 0x1509d5dafc90) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33798] lstat("/mnt/disk2/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/isos", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/isos", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31876] lstat("/mnt/disk2/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/isos", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31880] lstat("/mnt/disk2/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/isos", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/isos", 0x150a4c8c2c00) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31880] lstat("/mnt/disk2/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/isos", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31880] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31880] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31880] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31880] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31880] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31880] lstat("/mnt/disk6/media", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31880] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33805] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33805] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33805] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33805] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33805] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33805] lstat("/mnt/disk6/media", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33805] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31856] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31856] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31856] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31856] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31856] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31856] lstat("/mnt/disk6/media", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31856] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31874] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31874] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31874] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31874] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31874] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31874] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31874] lstat("/mnt/disk6/media", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31874] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31874] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31874] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33798] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33798] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33798] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33798] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33798] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33798] lstat("/mnt/disk6/media", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33798] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31876] lstat("/mnt/cache/music", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/music", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/music", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/music", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31876] lstat("/mnt/disk5/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/music", 0x1509d75bbc90) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/music", 0x1509d75bbc90) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/music", 0x1509d75bbc90) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/music", 0x1509d75bbc90) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33799] lstat("/mnt/disk5/music", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/music", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/music", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/music", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/music", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/music", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/music", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/music", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/music", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/music", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31868] lstat("/mnt/disk5/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/music", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/music", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/music", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk2/music", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/music", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31880] lstat("/mnt/disk5/music", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/music", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/music", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/music", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/music", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/music", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/music", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/music", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/music", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/music", 0x150a2ed08c00) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33805] lstat("/mnt/disk5/music", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/music", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/music", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/music", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/music", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/music", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/system", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31856] lstat("/mnt/disk2/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/system", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31881] lstat("/mnt/disk2/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/system", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/system", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31874] lstat("/mnt/disk2/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/system", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/system", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31876] lstat("/mnt/disk2/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/system", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/system", 0x1509d75bbc00) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 33799] lstat("/mnt/disk2/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/system", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server", {st_mode=S_IFDIR|0755, st_size=218, ...}) = 0 [pid 31868] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server/Plug-ins", {st_mode=S_IFDIR|0755, st_size=30, ...}) = 0 [pid 33810] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server/Plug-ins", {st_mode=S_IFDIR|0755, st_size=30, ...}) = 0 [pid 31880] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)", {st_mode=S_IFDIR|0755, st_size=96, ...}) = 0 [pid 33805] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)", {st_mode=S_IFDIR|0755, st_size=119, ...}) = 0 [pid 33805] lstat("/mnt/disk10/media/Movies1/Killing Oswald (2013)", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31881] lstat("/mnt/cache/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/media/Movies1/Killing Oswald (2013)/Killing.Oswald - 2013 - DVD.mkv", {st_mode=S_IFREG|0644, st_size=1100556210, ...}) = 0 [pid 31874] lstat("/mnt/cache/appdata/bazarr/app", {st_mode=S_IFDIR|0775, st_size=32, ...}) = 0 [pid 31874] lstat("/mnt/disk1/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/appdata/bazarr/app/db", {st_mode=S_IFDIR|0775, st_size=18, ...}) = 0 [pid 33798] lstat("/mnt/disk1/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/appdata/bazarr/app/db", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/appdata/bazarr/app/db/bazarr.db-journal", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata/bazarr/app", {st_mode=S_IFDIR|0775, st_size=32, ...}) = 0 [pid 31868] lstat("/mnt/disk1/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/appdata/bazarr/app", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata/bazarr/app/db", {st_mode=S_IFDIR|0775, st_size=18, ...}) = 0 [pid 31868] lstat("/mnt/disk1/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/appdata/bazarr/app/db", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/appdata/bazarr/app/db/bazarr.db-wal", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db", {st_mode=S_IFREG|0644, st_size=14925824, ...}) = 0 [pid 33799] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33799] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33810] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33810] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31856] lstat("/mnt/cache/appdata/upstatsboard", {st_mode=S_IFDIR|0755, st_size=18, ...}) = 0 [pid 31856] lstat("/mnt/disk1/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/appdata/upstatsboard", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31868] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31874] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31874] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33798] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31856] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 31856] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 31856] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 31856] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 31856] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 31868] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 31868] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 31868] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 31868] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 31876] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 31876] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 31876] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 31876] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 33798] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a2ed08c90) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 33805] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31880] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31856] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a2d122c00) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a2d122c00) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a2d122c00) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a2d122c00) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a2d122c00) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a2d122c00) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31856] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a2d122b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a2d122b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a2d122b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a2d122b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31868] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk2/appdata", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/appdata", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/appdata", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/appdata", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk7/appdata", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/appdata", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/appdata", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/appdata", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31876] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31876] lstat("/mnt/disk2/appdata", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/appdata", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/appdata", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/appdata", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31876] lstat("/mnt/disk7/appdata", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/appdata", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/appdata", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/appdata", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31874] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31874] lstat("/mnt/disk2/appdata", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31874] lstat("/mnt/disk7/appdata", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33798] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk2/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk7/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33805] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33805] lstat("/mnt/disk2/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33805] lstat("/mnt/disk7/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/appdata", 0x150a2ed08b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/domains", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31880] lstat("/mnt/disk2/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/domains", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/domains", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33810] lstat("/mnt/disk2/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/domains", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/domains", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk2/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/domains", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/domains", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk2/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/domains", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31876] lstat("/mnt/disk2/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/domains", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/files", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk2/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/files", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/files", 0x150a2f44ec90) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31874] lstat("/mnt/disk2/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/files", 0x150a2f44eb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/files", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/disk2/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/files", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/files", 0x150a4c8c2cc0) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31880] lstat("/mnt/disk2/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/files", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/files", 0x150a1c469c00) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk2/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/files", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/isos", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31881] lstat("/mnt/disk2/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/isos", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/isos", 0x150a2d122c90) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31856] lstat("/mnt/disk2/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/isos", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/isos", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31868] lstat("/mnt/disk2/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/isos", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/isos", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31876] lstat("/mnt/disk2/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/isos", 0x150a2f44ec00) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31874] lstat("/mnt/disk2/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/isos", 0x150a2f44eb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33798] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33798] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33798] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33798] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33798] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33798] lstat("/mnt/disk6/media", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33798] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33805] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33805] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33805] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33805] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33805] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33805] lstat("/mnt/disk6/media", 0x150a2ed08b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33805] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31880] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31880] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31880] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31880] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31880] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31880] lstat("/mnt/disk6/media", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31880] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31881] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31881] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31881] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31881] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31881] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31881] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31881] lstat("/mnt/disk6/media", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31881] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31881] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31881] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31856] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31856] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31856] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31856] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31856] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31856] lstat("/mnt/disk6/media", 0x150a2d122b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31856] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33799] lstat("/mnt/cache/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33799] lstat("/mnt/disk5/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/music", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/music", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/music", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/music", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31868] lstat("/mnt/disk5/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/music", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/music", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/music", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/music", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/music", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31876] lstat("/mnt/disk5/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/music", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/music", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/music", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/music", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/music", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33798] lstat("/mnt/disk5/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/music", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/music", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/music", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/music", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33798] lstat("/mnt/disk5/music", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/music", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/music", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/music", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/music", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/music", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/system", 0x150a1c469cc0) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 33810] lstat("/mnt/disk2/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/system", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/system", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31880] lstat("/mnt/disk2/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/system", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/system", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31881] lstat("/mnt/disk2/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/system", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/system", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31856] lstat("/mnt/disk2/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/system", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/system", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31868] lstat("/mnt/disk2/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/system", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/appdata/bazarr/app", {st_mode=S_IFDIR|0775, st_size=32, ...}) = 0 [pid 31874] lstat("/mnt/disk1/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/appdata/bazarr/app/db", {st_mode=S_IFDIR|0775, st_size=18, ...}) = 0 [pid 31874] lstat("/mnt/disk1/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata/bazarr/app/db", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata/bazarr/app/db/bazarr.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/appdata/bazarr/app", {st_mode=S_IFDIR|0775, st_size=32, ...}) = 0 [pid 31874] lstat("/mnt/disk1/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk2/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/appdata/bazarr/app", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/appdata/bazarr/app/db", {st_mode=S_IFDIR|0775, st_size=18, ...}) = 0 [pid 31880] lstat("/mnt/disk1/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk2/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/appdata/bazarr/app/db", 0x150a4c8c2b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/appdata/bazarr/app/db/bazarr.db-wal", 0x150a4c259cc0) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/appdata/bazarr/app/db/bazarr.db", {st_mode=S_IFREG|0644, st_size=14925824, ...}) = 0 [pid 31856] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31868] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31876] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33805] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33798] lstat("/mnt/cache/appdata/upstatsboard", {st_mode=S_IFDIR|0755, st_size=18, ...}) = 0 [pid 33798] lstat("/mnt/disk1/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/appdata/upstatsboard", 0x1509d5dafb40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31874] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31880] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33799] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 31881] lstat("/mnt/cache/appdata/upstatsboard/config.js", {st_mode=S_IFREG|0644, st_size=5291, ...}) = 0 [pid 33798] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 33798] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 33798] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 33798] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 33798] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33798] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 33810] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 33810] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 33810] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 33810] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/cache/.", {st_mode=S_IFDIR|0777, st_size=24, ...}) = 0 [pid 33810] lstat("/mnt/disk1/.", {st_mode=S_IFDIR|0777, st_size=116, ...}) = 0 [pid 33810] lstat("/mnt/disk2/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk3/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk4/.", {st_mode=S_IFDIR|0777, st_size=44, ...}) = 0 [pid 33810] lstat("/mnt/disk5/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk6/.", {st_mode=S_IFDIR|0777, st_size=63, ...}) = 0 [pid 33810] lstat("/mnt/disk7/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk8/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk9/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk10/.", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31868] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31868] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31868] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 31876] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 33798] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/CommunityApplicationsAppdataBackup", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/CommunityApplicationsAppdataBackup", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/CommunityApplicationsAppdataBackup", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/CommunityApplicationsAppdataBackup", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/CommunityApplicationsAppdataBackup", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/CommunityApplicationsAppdataBackup", 0x1509d5dafc00) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/CommunityApplicationsAppdataBackup", {st_mode=S_IFDIR|0777, st_size=38, ...}) = 0 [pid 33798] lstat("/mnt/disk7/CommunityApplicationsAppdataBackup", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/CommunityApplicationsAppdataBackup", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/CommunityApplicationsAppdataBackup", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/CommunityApplicationsAppdataBackup", 0x1509d5dafb60) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33798] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk2/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk7/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/appdata", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 33799] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33799] lstat("/mnt/disk2/appdata", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/appdata", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/appdata", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/appdata", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33799] lstat("/mnt/disk7/appdata", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/appdata", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/appdata", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/appdata", 0x1509d75bbb40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31881] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk2/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31881] lstat("/mnt/disk7/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/appdata", 0x150a4c259b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31856] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31856] lstat("/mnt/disk2/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31856] lstat("/mnt/disk7/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/appdata", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/appdata", {st_mode=S_IFDIR|0777, st_size=264, ...}) = 0 [pid 31868] lstat("/mnt/disk1/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk2/appdata", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/appdata", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/appdata", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/appdata", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/appdata", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk7/appdata", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/appdata", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/appdata", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/appdata", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/domains", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31868] lstat("/mnt/disk2/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/domains", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/domains", 0x150a07758c90) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31876] lstat("/mnt/disk2/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/domains", 0x150a07758b40) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/cache/domains", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 31874] lstat("/mnt/disk2/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk3/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk4/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk5/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk6/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk7/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk8/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk9/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 31874] lstat("/mnt/disk10/domains", 0x150a2f44eb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/domains", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33798] lstat("/mnt/disk2/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/domains", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/domains", 0x1509d75bbc00) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/domains", {st_mode=S_IFDIR|0777, st_size=6, ...}) = 0 [pid 33799] lstat("/mnt/disk2/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/domains", 0x1509d75bbb60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/files", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33799] lstat("/mnt/disk2/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/files", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/files", 0x150a1c469c90) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33810] lstat("/mnt/disk2/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/files", 0x150a1c469b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/files", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31856] lstat("/mnt/disk2/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/files", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/files", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 33805] lstat("/mnt/disk2/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/files", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/files", 0x150a07758c00) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/files", {st_mode=S_IFDIR|0777, st_size=19, ...}) = 0 [pid 31876] lstat("/mnt/disk2/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/files", 0x150a07758b60) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/cache/isos", 0x150a07758cc0) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31876] lstat("/mnt/disk2/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk3/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk4/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk5/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk6/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk7/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk8/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk9/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31876] lstat("/mnt/disk10/isos", 0x150a07758b20) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/cache/isos", 0x150a4c8c2c90) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 31880] lstat("/mnt/disk2/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk3/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk4/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk5/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk6/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk8/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk9/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk10/isos", 0x150a4c8c2b40) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/isos", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33798] lstat("/mnt/disk2/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/isos", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/isos", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33799] lstat("/mnt/disk2/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/isos", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/isos", 0x150a1c469c00) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk1/isos", {st_mode=S_IFDIR|0777, st_size=46, ...}) = 0 [pid 33810] lstat("/mnt/disk2/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/isos", 0x150a1c469b60) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31856] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31856] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31856] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31856] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31856] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31856] lstat("/mnt/disk6/media", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31856] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31856] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31868] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31868] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31868] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31868] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31868] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31868] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31868] lstat("/mnt/disk6/media", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31868] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31868] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31868] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33805] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33805] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33805] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33805] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33805] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33805] lstat("/mnt/disk6/media", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33805] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 33805] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 33805] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 33805] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 33805] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 33805] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 33805] lstat("/mnt/disk6/media", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33805] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 33805] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/cache/media", {st_mode=S_IFDIR|0777, st_size=52, ...}) = 0 [pid 31880] lstat("/mnt/disk1/media", {st_mode=S_IFDIR|0777, st_size=150, ...}) = 0 [pid 31880] lstat("/mnt/disk2/media", {st_mode=S_IFDIR|0777, st_size=169, ...}) = 0 [pid 31880] lstat("/mnt/disk3/media", {st_mode=S_IFDIR|0777, st_size=148, ...}) = 0 [pid 31880] lstat("/mnt/disk4/media", {st_mode=S_IFDIR|0777, st_size=163, ...}) = 0 [pid 31880] lstat("/mnt/disk5/media", {st_mode=S_IFDIR|0777, st_size=122, ...}) = 0 [pid 31880] lstat("/mnt/disk6/media", 0x150a4c8c2b60) = -1 ENOENT (No such file or directory) [pid 31880] lstat("/mnt/disk7/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk8/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 31880] lstat("/mnt/disk9/media", {st_mode=S_IFDIR|0777, st_size=72, ...}) = 0 [pid 31880] lstat("/mnt/disk10/media", {st_mode=S_IFDIR|0777, st_size=88, ...}) = 0 [pid 33798] lstat("/mnt/cache/music", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/music", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk2/music", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/music", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33798] lstat("/mnt/disk5/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/music", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/music", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/music", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk2/music", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/music", 0x150a4c259c90) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31881] lstat("/mnt/disk5/music", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/music", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/music", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/music", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/music", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/music", 0x150a4c259b40) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk1/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/music", 0x1509d75bbcc0) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 33799] lstat("/mnt/disk5/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/music", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/music", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk1/music", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/music", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/music", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31856] lstat("/mnt/disk5/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/music", 0x150a2d122b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/music", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/music", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk2/music", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/music", 0x1509d69b5c00) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/music", {st_mode=S_IFDIR|0777, st_size=98304, ...}) = 0 [pid 31868] lstat("/mnt/disk5/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/music", 0x1509d69b5b60) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/system", 0x1509d69b5cc0) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31868] lstat("/mnt/disk2/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/system", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/cache/system", 0x1509d69b5c90) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31868] lstat("/mnt/disk2/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk3/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk4/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk5/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk6/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk7/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk8/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk9/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 31868] lstat("/mnt/disk10/system", 0x1509d69b5b40) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/cache/system", 0x150a2ed08cc0) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 33805] lstat("/mnt/disk2/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk3/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk4/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk5/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk6/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk7/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk8/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk9/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33805] lstat("/mnt/disk10/system", 0x150a2ed08b20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/cache/system", 0x1509d5dafcc0) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 33798] lstat("/mnt/disk2/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk3/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk4/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk5/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk6/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk7/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk8/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk9/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 33798] lstat("/mnt/disk10/system", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/cache/system", 0x150a4c259c00) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk1/system", {st_mode=S_IFDIR|0777, st_size=47, ...}) = 0 [pid 31881] lstat("/mnt/disk2/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk3/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk4/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk5/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk6/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk7/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk8/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk9/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 31881] lstat("/mnt/disk10/system", 0x150a4c259b60) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server", {st_mode=S_IFDIR|0755, st_size=218, ...}) = 0 [pid 33799] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33799] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server", 0x1509d75bbb20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server/Plug-ins", {st_mode=S_IFDIR|0755, st_size=30, ...}) = 0 [pid 33810] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 33810] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/cache/appdata/binhex-plexpass/Plex Media Server/Plug-ins", {st_mode=S_IFDIR|0755, st_size=30, ...}) = 0 [pid 31856] lstat("/mnt/disk1/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk2/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk3/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk4/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk5/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk6/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk7/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk8/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk9/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) [pid 31856] lstat("/mnt/disk10/appdata/binhex-plexpass/Plex Media Server/Plug-ins", 0x150a2d122b40) = -1 ENOENT (No such file or directory) ^Cstrace: Process 43726 detached strace: Process 43727 detached strace: Process 18093 detached strace: Process 31856 detached strace: Process 31868 detached strace: Process 31874 detached strace: Process 31876 detached strace: Process 31880 detached strace: Process 31881 detached strace: Process 33798 detached strace: Process 33799 detached strace: Process 33805 detached strace: Process 33810 detached root@Tower:/mnt/user/media/tvshows#
-
Thank you for letting us know, hopefully we have some more inquiries soon from them about it, so it can be solved quickly.
-
My appdata share config : # Generated settings: shareComment="application data" shareInclude="" shareExclude="" shareUseCache="only" shareCOW="auto" shareAllocator="highwater" shareSplitLevel="1" shareFloor="0" shareExport="-" shareFruit="no" shareCaseSensitive="auto" shareSecurity="public" shareReadList="" shareWriteList="" shareVolsizelimit="" shareExportNFS="-" shareExportNFSFsid="0" shareSecurityNFS="public" shareHostListNFS="" shareExportAFP="-" shareSecurityAFP="public" shareReadListAFP="" shareWriteListAFP="" shareVolsizelimitAFP="" shareVoldbpathAFP="" From Today: strace -fF -p 18081 -s 4000 ( at the time 18081 was the shfs pid causing the highest IO % as per IoTOP ) [pid 49026] read(9, ";\0\0\0\1\0\0\0\260\227\322\363\v\0\0\0\367\16\36\4\0\0\0\0\330\1\0\0\330\1\0\0\250+\0\0\0\0\0\0grafana.db-journal\0", 59) = 59 [pid 49026] lstat("/mnt/cache/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk1/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk2/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk3/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk4/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk5/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk6/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk7/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk8/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk9/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] lstat("/mnt/disk10/appdata/grafana/grafana.db-journal", 0x150a2f44ecc0) = -1 ENOENT (No such file or directory) [pid 49026] writev(4, [{iov_base="\20\0\0\0\376\377\377\377\260\227\322\363\v\0\0\0", iov_len=16}], 1) = 16 [pid 49026] splice(4, NULL, 12, NULL, 135168, 0 <unfinished ...> [pid 5728] <... splice resumed> ) = 56 [pid 5728] read(159, "8\0\0\0\3\0\0\0\261\227\322\363\v\0\0\0\371\16\36\4\0\0\0\0\330\1\0\0\330\1\0\0\250+\0\0\0\0\0\0\1\0\0\0\0\0\0\0_\0\0\0\0\0\0\0", 56) = 56 [pid 5728] fstat(95, {st_mode=S_IFREG|0644, st_size=2748416, ...}) = 0 [pid 5728] writev(4, [{iov_base="x\0\0\0\0\0\0\0\261\227\322\363\v\0\0\0", iov_len=16}, {iov_base="\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\267\\U\0\0\0.\0\0\360)\0\0\0\0\0\370\24\0\0\0\0\0\0002c\214^\0\0\0\0\367\270\222^\0\0\0\0\367\270\222^\0\0\0\0\301\34^\22R-\360\6R-\360\6\244\201\0\0\1\0\0\0\330\1\0\0\330\1\0\0\0\0\0\0\0\20\0\0\0\0\0\0", iov_len=104}], 2) = 120 [pid 11470] <... splice resumed> ) = 55 [pid 5728] splice(4, NULL, 160, NULL, 135168, 0 <unfinished ...> [pid 11470] read(139, "7\0\0\0\1\0\0\0\262\227\322\363\v\0\0\0\367\16\36\4\0\0\0\0\330\1\0\0\330\1\0\0\250+\0\0\0\0\0\0grafana.db-wal\0", 55) = 55 [pid 11470] lstat("/mnt/cache/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk1/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk2/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk3/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk4/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk5/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk6/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk7/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk8/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk9/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] lstat("/mnt/disk10/appdata/grafana/grafana.db-wal", 0x150a06379cc0) = -1 ENOENT (No such file or directory) [pid 11470] writev(4, [{iov_base="\20\0\0\0\376\377\377\377\262\227\322\363\v\0\0\0", iov_len=16}], 1) = 16 [pid 11470] splice(4, NULL, 140, NULL, 135168, 0 <unfinished ...> [pid 8149] <... splice resumed> ) = 56 [pid 8149] read(10, "8\0\0\0\3\0\0\0\263\227\322\363\v\0\0\0\371\16\36\4\0\0\0\0\330\1\0\0\330\1\0\0\250+\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0", 56) = 56 [pid 8149] lstat("/mnt/cache/appdata/grafana/grafana.db", {st_mode=S_IFREG|0644, st_size=2748416, ...}) = 0 [pid 8149] writev(4, [{iov_base="x\0\0\0\0\0\0\0\263\227\322\363\v\0\0\0", iov_len=16}, {iov_base="\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\267\\U\0\0\0.\0\0\360)\0\0\0\0\0\370\24\0\0\0\0\0\0002c\214^\0\0\0\0\367\270\222^\0\0\0\0\367\270\222^\0\0\0\0\301\34^\22R-\360\6R-\360\6\244\201\0\0\1\0\0\0\330\1\0\0\330\1\0\0\0\0\0\0\0\20\0\0\0\0\0\0", iov_len=104}], 2) = 120 [pid 8149] splice(4, NULL, 13, NULL, 135168, 0 <unfinished ...> [pid 49028] <... splice resumed> ) = 44 [pid 49028] read(98, ",\0\0\0\1\0\0\0\264\227\322\363\v\0\0\0X\17\325\3\0\0\0\0c\0\0\0d\0\0\0!?\0\0\0\0\0\0www\0", 44) = 44 [pid 49028] lstat("/mnt/cache/appdata/heimdall/www", {st_mode=S_IFDIR|0775, st_size=120, ...}) = 0 [pid 49028] lstat("/mnt/disk1/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk2/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk3/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk4/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk5/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk6/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk7/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk8/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk9/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] lstat("/mnt/disk10/appdata/heimdall/www", 0x1509d5baeb20) = -1 ENOENT (No such file or directory) [pid 49028] writev(4, [{iov_base="\220\0\0\0\0\0\0\0\264\227\322\363\v\0\0\0", iov_len=16}, {iov_base="]\17\325\3\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0002\5\0\0\0\0.\0x\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\346\217\177^\0\0\0\0x\203\222^\0\0\0\0y\203\222^\0\0\0\0_h\3336\332\36\3418\354\216\236\5\375A\0\0\1\0\0\0c\0\0\0d\0\0\0\0\0\0\0\0\20\0\0\0\0\0\0", iov_len=128}], 2) = 144 [pid 49028] splice(4, NULL, 99, NULL, 135168, 0 <unfinished ...> [pid 32721] <... splice resumed> ) = 59 [pid 32721] read(163, ";\0\0\0\1\0\0\0\265\227\322\363\v\0\0\0]\17\325\3\0\0\0\0c\0\0\0d\0\0\0!?\0\0\0\0\0\0app.sqlite-journal\0", 59) = 59 [pid 32721] lstat("/mnt/cache/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk1/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk2/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk3/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk4/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk5/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk6/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk7/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk8/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk9/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] lstat("/mnt/disk10/appdata/heimdall/www/app.sqlite-journal", 0x150a05c28cc0) = -1 ENOENT (No such file or directory) [pid 32721] writev(4, [{iov_base="\20\0\0\0\376\377\377\377\265\227\322\363\v\0\0\0", iov_len=16}], 1) = 16 [pid 32721] splice(4, NULL, 164, NULL, 135168, 0 <unfinished ...> [pid 16766] <... splice resumed> ) = 56 [pid 16766] read(119, "8\0\0\0\3\0\0\0\266\227\322\363\v\0\0\0Y\23\36\4\0\0\0\0c\0\0\0d\0\0\0!?\0\0\0\0\0\0\1\0\0\0\0\0\0\0[\0\0\0\0\0\0\0", 56) = 56 [pid 16766] fstat(91, {st_mode=S_IFREG|0664, st_size=233472, ...}) = 0 [pid 16766] writev(4, [{iov_base="x\0\0\0\0\0\0\0\266\227\322\363\v\0\0\0", iov_len=16}, {iov_base="\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0E\5\0\0\0\0.\0\0\220\3\0\0\0\0\0\310\1\0\0\0\0\0\0\354\217\177^\0\0\0\0\372\32\202^\0\0\0\0y\203\222^\0\0\0\0V1\3352\236\36615\256L\217\5\264\201\0\0\1\0\0\0c\0\0\0d\0\0\0\0\0\0\0\0\20\0\0\0\0\0\0", iov_len=104}], 2) = 120 [pid 16766] splice(4, NULL, 120, NULL, 135168, 0 <unfinished ...> [pid 19467] <... splice resumed> ) = 44 [pid 19467] read(131, ",\0\0\0\1\0\0\0\267\227\322\363\v\0\0\0X\17\325\3\0\0\0\0c\0\0\0d\0\0\0!?\0\0\0\0\0\0www\0", 44) = 44 [pid 19467] lstat("/mnt/cache/appdata/heimdall/www", {st_mode=S_IFDIR|0775, st_size=120, ...}) = 0 [pid 19467] lstat("/mnt/disk1/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk2/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk3/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk4/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk5/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk6/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk7/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk8/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk9/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] lstat("/mnt/disk10/appdata/heimdall/www", 0x1509d69b5b20) = -1 ENOENT (No such file or directory) [pid 19467] writev(4, [{iov_base="\220\0\0\0\0\0\0\0\267\227\322\363\v\0\0\0", iov_len=16}, {iov_base="]\17\325\3\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0002\5\0\0\0\0.\0x\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\346\217\177^\0\0\0\0x\203\222^\0\0\0\0y\203\222^\0\0\0\0_h\3336\332\36\3418\354\216\236\5\375A\0\0\1\0\0\0c\0\0\0d\0\0\0\0\0\0\0\0\20\0\0\0\0\0\0", iov_len=128}], 2) = 144 [pid 19467] splice(4, NULL, 132, NULL, 135168, 0 <unfinished ...> [pid 18081] <... splice resumed> ) = 55 [pid 18081] read(123, "7\0\0\0\1\0\0\0\270\227\322\363\v\0\0\0]\17\325\3\0\0\0\0c\0\0\0d\0\0\0!?\0\0\0\0\0\0app.sqlite-wal\0", 55) = 55 [pid 18081] lstat("/mnt/cache/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk1/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk2/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk3/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk4/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk5/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk6/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk7/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk8/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk9/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] lstat("/mnt/disk10/appdata/heimdall/www/app.sqlite-wal", 0x150a2d122cc0) = -1 ENOENT (No such file or directory) [pid 18081] writev(4, [{iov_base="\20\0\0\0\376\377\377\377\270\227\322\363\v\0\0\0", iov_len=16}], 1) = 16 [pid 49026] <... splice resumed> ) = 56 [pid 18081] splice(4, NULL, 124, NULL, 135168, 0 <unfinished ...> [pid 49026] read(9, "8\0\0\0\3\0\0\0\271\227\322\363\v\0\0\0Y\23\36\4\0\0\0\0c\0\0\0d\0\0\0!?\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0", 56) = 56 [pid 49026] lstat("/mnt/cache/appdata/heimdall/www/app.sqlite", {st_mode=S_IFREG|0664, st_size=233472, ...}) = 0 [pid 49026] writev(4, [{iov_base="x\0\0\0\0\0\0\0\271\227\322\363\v\0\0\0", iov_len=16}, {iov_base="\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0E\5\0\0\0\0.\0\0\220\3\0\0\0\0\0\310\1\0\0\0\0\0\0\354\217\177^\0\0\0\0\372\32\202^\0\0\0\0y\203\222^\0\0\0\0V1\3352\236\36615\256L\217\5\264\201\0\0\1\0\0\0c\0\0\0d\0\0\0\0\0\0\0\0\20\0\0\0\0\0\0", iov_len=104}], 2) = 120 [pid 49026] splice(4, NULL, 12, NULL, 135168, 0^Cstrace: Process 18081 detached IT can be noticed as well - that not only one thread is doing the wrong and useless IO - ALL of them doing it in parallel, that is why the system is so completely suffocated!!!
-
i am open as well to it is any one from LT looking into this ? My Cache run full again - and the mover tries to copy back to the array. While he does that - the exact same things are happening as already diagnosed before. I see so many performance related issues posted here - i am almost sure most of them are connected to the same bug ( excessive unnecessary IO against the Array )
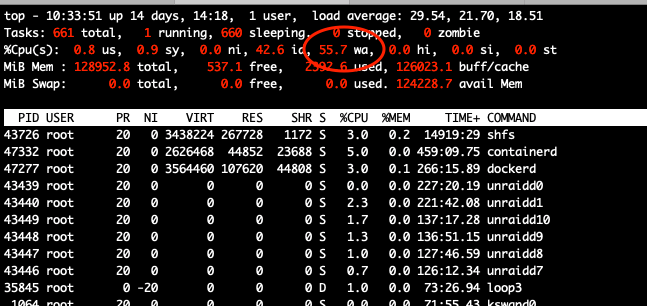
-
Btw. I found another thread just for the same. Seems it started with 6.7. The symptoms are exactly the same. THe server is all of a sudden suffocated with Wait IO .
-
I found something interesting this morning. There seem to be 2 issues that are causing this HIgh IO problem for Unraid. 1) BTRFS apparently has a problem with specific system calls related to directory structures. ( reporting non-accurate values, non-caching ) - i will investigate this further - maybe some mount options will help. 2) The majority of the problem however seems to stem from "shfs" the Filesystem for Unraid though. In my case i noticed, i have a couple of shfs threads. First i thought they are bound to each deal with one disk - but this doesn't seem to be the case. I have /mnt/cache/appdata set as "Cache Only" . However during a fraction of a second the shfs process tried to access directories on my disks ? And of course they don't exist there - since the share is set to "Cache Only" . Now we are not talking about only a few requests... there are millions of those - and all of them together are causing this incredible high IO and CPU load - since the CPU has to maintain the queue for all this requests across all disks. This is a serious BUG! Totally unnecessary IO and adds a lot of wear to the physical disks! They literally have to go through all of those requests instead of just sitting there nicely and calm and only answer when required. In order to try yourself to test - install ( via nerdpack ) : strace, elftools, iotop open iotop - see the PID 3072 - thats just one then : strace -fF -p 3072 -s 40000 -e lstat (below the PID was 3139) - however it will be the same regardless, just different dirs. Mind you, i filtered only the "lstat" system calls - all the "fstat" calls, the actually fopen, fwrite etc for the filetransfers has to happen as well... Oh and i should add - of course this is while the "mover" is running... And IO wait is >30% . If anyone from the Unraid Team will see this, i have attached my diagnostics zip for reference. In my understanding - since i configured appdata to reside completely on /mnt/cache - not a single request should end up here. And since those requests are being done from SHFS i think its not really the fault of the mover. Just the filesystem implementation not being smart enough. Shouldn't this implementation have i.e. a struct build upon startup where path are mapped to shares and their settings ? And this cache should be invalidated upon configuration changes or after timeout etc - The timeout can be even 60 seconds - but then instead of 10000s of requests only one will happen as a (re)validation test and then live goes on as normal. [pid 3139] lstat("/mnt/disk8/appdata/sonarr/MediaCover", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk9/appdata/sonarr/MediaCover", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk10/appdata/sonarr/MediaCover", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/cache/appdata/sonarr/MediaCover/32", {st_mode=S_IFDIR|0777, st_size=224, ...}) = 0 [pid 10611] lstat("/mnt/disk1/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk2/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk3/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk4/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk5/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk6/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk7/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk8/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk9/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 10611] lstat("/mnt/disk10/appdata/sonarr/MediaCover/32", 0x150a1c469b20) = -1 ENOENT (No such file or directory) [pid 15208] lstat("/mnt/cache/appdata/sonarr/MediaCover/32/fanart.jpg", {st_mode=S_IFREG|0666, st_size=478886, ...}) = 0 [pid 9581] lstat("/mnt/cache/appdata/sonarr/MediaCover/32/fanart.jpg", {st_mode=S_IFREG|0666, st_size=478886, ...}) = 0 [pid 10612] lstat("/mnt/cache/appdata/sonarr/MediaCover", {st_mode=S_IFDIR|0777, st_size=1348, ...}) = 0 [pid 10612] lstat("/mnt/disk1/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk2/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk3/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk4/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk5/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk6/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk7/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk8/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk9/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10612] lstat("/mnt/disk10/appdata/sonarr/MediaCover", 0x1509d5dafb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/cache/appdata/sonarr/MediaCover/32", {st_mode=S_IFDIR|0777, st_size=224, ...}) = 0 [pid 10396] lstat("/mnt/disk1/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk2/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk3/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk4/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk5/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk6/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk7/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk8/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk9/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 10396] lstat("/mnt/disk10/appdata/sonarr/MediaCover/32", 0x150a1fdfdb20) = -1 ENOENT (No such file or directory) [pid 13094] lstat("/mnt/cache/appdata/sonarr/MediaCover/32/fanart.jpg", {st_mode=S_IFREG|0666, st_size=478886, ...}) = 0 [pid 9271] lstat("/mnt/cache/appdata/sonarr/MediaCover/32/fanart.jpg", {st_mode=S_IFREG|0666, st_size=478886, ...}) = 0 [pid 9876] lstat("/mnt/cache/appdata/sonarr/MediaCover", {st_mode=S_IFDIR|0777, st_size=1348, ...}) = 0 [pid 9876] lstat("/mnt/disk1/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk2/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk3/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk4/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk5/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk6/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk7/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk8/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk9/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 9876] lstat("/mnt/disk10/appdata/sonarr/MediaCover", 0x150a06379b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/cache/appdata/sonarr/MediaCover/32", {st_mode=S_IFDIR|0777, st_size=224, ...}) = 0 [pid 3139] lstat("/mnt/disk1/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk2/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk3/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk4/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk5/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk6/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk7/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk8/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk9/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) [pid 3139] lstat("/mnt/disk10/appdata/sonarr/MediaCover/32", 0x150a05c28b20) = -1 ENOENT (No such file or directory) tower-diagnostics-20200408-0052.zip










