




CowboyRedBeard
Members
-
Joined
-
Last visited
-
I'm on 6.12.6 and have been since it came out. Everything "works" but I'm sorta weary of being this far behind. However, in times past I've upgraded and broken things... The system has been pretty solid for me for at least a year, maybe two... honestly I can't remember, and that's part of the problem. I did things along the way over the last 6 years or so, then just started ignoring system maintenance. What's the best path to upgrade and back things up to avoid problems, and then be able to roll back if I have them? An example is the USB drive I used for this system is probably almost 10 years old, and it has been running unraid the whole time. In fact, this box has been turned on with the exception of a few days for at least 6 years (on this MB and setup). When I first built this system, I had a number of VMs on here for different things and a bunch of dockers. Now it's essentially used for two very small VMs that I could live without and stuff to support Plex. Is it a consideration to just start fresh and copy over what settings I need? I've also considered building a less power hungry newer system, since I don't need this much compute power any longer. System: Supermicro X9DRi-LN4+ Dual Intel® Xeon® CPU E5-2690 v2 I have the following plugins, surely some of these are no longer compatible. What else should I review? CA Auto Update Applications 2024.03.17 CA Backup / Restore Appdata 2023.03.28c CA Cleanup Appdata 2024.11.28 Community Applications 2025.10.27 Dynamix Cache Directories 2025.11.14 Dynamix System Information 2025.11.14 Fix Common Problems 2025.08.07 IPMI support 2025.12.13 Nvidia Driver 2025.03.25 Tips and Tweaks 2025.03.06 Unassigned Devices 2025.11.18 Unassigned Devices Plus 2025.08.05a User Scripts 2025.06.21
-
Happy to help for the sake of finding out something new for the community if you give me the commands to run... already ordered a new one.
-
I'm on 6.12.6 and have started getting this error with my cache drive. May 1 09:30:00 Tower kernel: sd 11:0:0:0: [sdg] tag#1 access beyond end of device May 1 09:30:00 Tower kernel: I/O error, dev sdg, sector 220241888 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2 May 1 09:30:00 Tower kernel: BTRFS error (device sdg1: state EA): bdev /dev/sdg1 errs: wr 101, rd 1385, flush 0, corrupt 0, gen 0 May 1 09:30:00 Tower kernel: I/O error, dev loop2, sector 13370056 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2 May 1 09:30:00 Tower kernel: BTRFS error (device loop2: state EA): bdev /dev/loop2 errs: wr 10, rd 3331, flush 1, corrupt 0, gen 0 I found no posts on this forum, but found this: https://aufarg.github.io/btrfs-access-beyond-end-of-device.html And this is beyond my current level.... is this a thing others have seen in unraid? A reboot fixed it for me the last two times this has happened, is this an issue with the drive maybe? It's only about 2 years old. It's a Crucial CT1000MX500SSD1 Rev: M3CR043
-
There's two templates... what's the difference there?
-
What is everyone doing for backups of VMs at the moment? I saw that 6.13 / 7.0 may have snapshots built in... But in the interim, is there a good backup system that uses deltas? Currently I've just been shutting down the VM and making a copy, but those are huge files and the number of VMs I have are growing and their importance to my operations is also increasing. Thanks in advance for the advice!
-
Hey fam, I'm considering upgrading now that CA tells me I don't meet the minimum build version. I have been running unraid for 6+ years on this same box, and in the past had a few strange issues that went away when I upgraded to 6.10.3. So I've been apprehensive to upgrade. I run about 25 different dockers, and 4 VMs full time in addition to general services like shares. MB is a Supermicro X9DRi-LN4+, and I have the NVIDIA pass-thru situation going on (plugin). What is some general advice on finding a safe upgrade path? Also I've had this same SanDisk Cruzer Fit USB for unraid for 6 years now, and the server has been basically turned on that entire time (a few power outages & maint windows for additional drives). Should I swap that out at some point? What's the best way to back up my unraid install? I guess I'd go to latest stable which is 6.12.4 at this time, anything to look out for there? Thanks for the help!I keep getting "not available" update status on the docker tab, is this still the right URL? https://hub.docker.com/r/netdata/netdataAny chance this could have something to do with my memory configuration or something like that? I am using the SCU cable for most of the array drives, although the Parity disk Cache drive are on the onboard SATA3 ports.
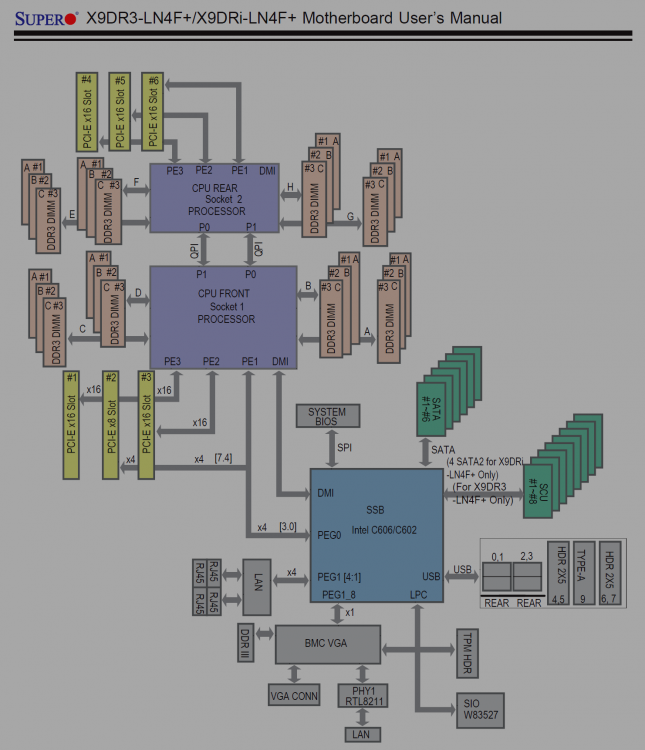 Do you think this is a product of the configuration? I can't see how it's a hardware issue, so maybe reinstalling unRAID would help? Also, more than happy to post any logs / test data needed to solve this.I have another new Crucial MX500 ( CT1000MX500SSD1 ) I can replace it with to try.... but I had this problem with MX500 500Gb drives that I had prior. And those were 2 drives in a pool at first, split the cache to a single drive and was still a problem. I tried both BTRFS and XFS I'll do whatever tests you guys think make sense. Let me know. THANK YOU FOR THE HELP! -yes that's caps 🙃Yeah, I had an Intel Optane drive in there that I was using with VMs. I was able to send to it at a pretty crazy clip, but the SSDs won't achieve anything even approaching what the benchmarks say they can do for more than a few minutes.Both SSDs are connected via SATA3 ports on the MB (SuperMicro) and I've also tried having them connected to a SATA card plugged via PCIEBut shouldn't the below behavior be basically all the time? I mean, those SSDs should be able to keep 300MiB/s and more for extended periods of time right? I'm pretty sure this doesn't have anything to do with network, since it exhibits the same behavior even disk to disk. The IO Wait has got to be a byproduct of whatever the problem is. This wasn't the case for a long time prior to 6.7 in this very same server, with all the same hardware. These current SSD drives were even an attempt to rule out the previous SSDs.
Do you think this is a product of the configuration? I can't see how it's a hardware issue, so maybe reinstalling unRAID would help? Also, more than happy to post any logs / test data needed to solve this.I have another new Crucial MX500 ( CT1000MX500SSD1 ) I can replace it with to try.... but I had this problem with MX500 500Gb drives that I had prior. And those were 2 drives in a pool at first, split the cache to a single drive and was still a problem. I tried both BTRFS and XFS I'll do whatever tests you guys think make sense. Let me know. THANK YOU FOR THE HELP! -yes that's caps 🙃Yeah, I had an Intel Optane drive in there that I was using with VMs. I was able to send to it at a pretty crazy clip, but the SSDs won't achieve anything even approaching what the benchmarks say they can do for more than a few minutes.Both SSDs are connected via SATA3 ports on the MB (SuperMicro) and I've also tried having them connected to a SATA card plugged via PCIEBut shouldn't the below behavior be basically all the time? I mean, those SSDs should be able to keep 300MiB/s and more for extended periods of time right? I'm pretty sure this doesn't have anything to do with network, since it exhibits the same behavior even disk to disk. The IO Wait has got to be a byproduct of whatever the problem is. This wasn't the case for a long time prior to 6.7 in this very same server, with all the same hardware. These current SSD drives were even an attempt to rule out the previous SSDs.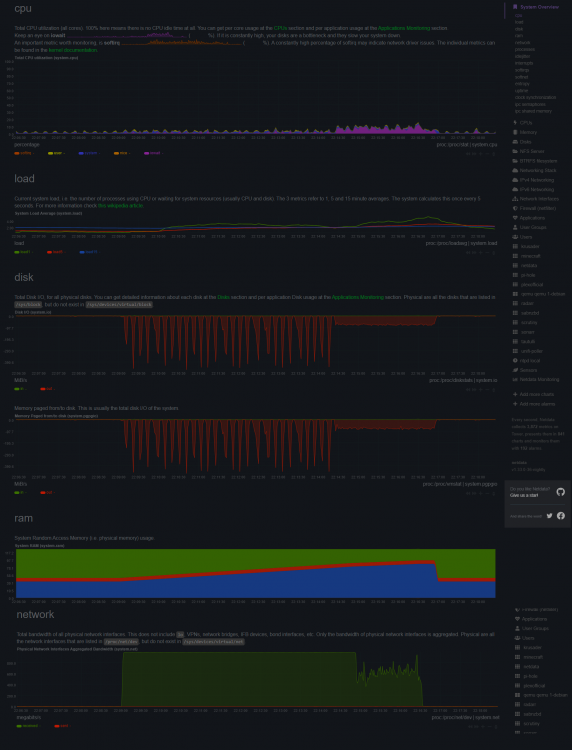 Probably the posts on this page are a very depiction of the problem as it appears currently. But essentially, with any file write process to cache I end up with high i/o wait times. I will see the cache drive able to write at around 300MiB/s for just a minute or two and then after that it will only give around 80MiB/s after. This shows up in netdata and on the unraid dashboard as in the following posts: And in that second one you can even see the CPU temps rise, which as was mentioned here was thought to be odd since it's just "waiting" ... but I monitor CPU temp / Fan speed with IPMI and then send that data to influxDB where I can trend it (which is that graph in the second post) Happy to conduct any tests you think are meaningful and post the results here. But primarily I see this with cache drives only (spinning disks don't obtain the same sort of speeds so I guess the system can keep up with them). And, I also see this if it's Sab downloading / unpacking a file, or transferring data to or from a non-array / non-cache SSD. Also, earlier on in this thread, I had an Intel Optane NVME drive in the box on PCIE slot and was able to get crazy sustain write speeds to it without this issue occurring. I've since pulled that out, but could put it back in for testing if needed.
Probably the posts on this page are a very depiction of the problem as it appears currently. But essentially, with any file write process to cache I end up with high i/o wait times. I will see the cache drive able to write at around 300MiB/s for just a minute or two and then after that it will only give around 80MiB/s after. This shows up in netdata and on the unraid dashboard as in the following posts: And in that second one you can even see the CPU temps rise, which as was mentioned here was thought to be odd since it's just "waiting" ... but I monitor CPU temp / Fan speed with IPMI and then send that data to influxDB where I can trend it (which is that graph in the second post) Happy to conduct any tests you think are meaningful and post the results here. But primarily I see this with cache drives only (spinning disks don't obtain the same sort of speeds so I guess the system can keep up with them). And, I also see this if it's Sab downloading / unpacking a file, or transferring data to or from a non-array / non-cache SSD. Also, earlier on in this thread, I had an Intel Optane NVME drive in the box on PCIE slot and was able to get crazy sustain write speeds to it without this issue occurring. I've since pulled that out, but could put it back in for testing if needed.



