




poeterdebier
Members
-
Joined
-
Last visited
-
Hi Jorge, removed all data from cache (moved to array). Removed and formatted the nvme's and recreated a pool. Scrub gives 0 errors and pool device stats are all at 0. Server operational without issues. Will closely monitor the server oncoming time. Also learned some things and will have a bit different approach on backing up files/settings in the future. I really appreciated the help and support. regards Piet (not sure if you want to close this post)
-
recreating the pool could be done by: moving all data to the array removing both cache from array / format adding both nvme back as cache or am I then recreating errors?
-
Hi Jorge, I decided to focus on disk1. So I did a file system check of disk1. I got an 'dirty log error'. I went ahead with 'zero log' and this fixed the file corruption on disk1. Started the array after that and disk1 mounted without issues. I did another scrub of the cache pool but this kept giving 2056 uncorrectable errors. As mentioned by you I started replacing/deleting some of the files that the syslog mentioned and this removed some of the uncorrectable errors in the cache pool. Not all unfortunately, 664 remaining. Also, I cannot identify them the same way as the isos were (with a mentioned file name). So regarding the 664 uncorrectable errors I am stuck at the moment. I was considering to repair the cache pool in the 'check filesystem status' but the help section was really specific with mentioning that this only needed to be done on advise of a community expert. So I only did the readonly check (but forgot to take a screenshot). (did a parity check with correction after disk1 was reinstated. Many corrections. Did a parity check again after that without correction checked. Finding 0 errors.) tower-diagnostics-20260102-2227.zip
-
Completely missed that one (the path part). Thanks. Removed already part and the errors went down. Tomorrow continue. Thanks for the help so far, to be continued. Happy New Year 🎆
-
tower-diagnostics-20251231-1622.zipSo I did a repair on disk1 through the webUI (Check Filesystem Status section). I had to 'zero log' due to 'dirty log detected'. After that I got a file system corruption fixed. So current disk1 is back online. I did a scrub of the cache pool and that is still the same (2056 uncorrectable errors). I also reset the pool device status (I assume that this is what you mean with 'reset pool stats'. At the moment I do not know what to do with the uncorrectable errors. The scrub should fix this if there is a correct copy available (I guess there isn't right now). I looked into the syslog to attempt to see what files are corrupt to remove/replace them but the only 'corrupt' message I can find is: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 7368, gen 4Do you have an idea how to identify the files that are corrupt? To get this uncorrectable error count back to zero?
-
Ok, thanks for the info. Will check the syslog/corrupt files etc. soonest. Probably not tonight 😄. Regarding the file check. That is something that you recommend to do before replacing the disk1 entirely? Or do you suspect something else is caused disk1 to become corrupt (the intermittent problem you mentioned). The reason to ask it, you want to have disk1 up and running as soon as possible right. If a second disk fails then I will be loosing data for sure. Still pretty inexperienced in all this so sorry for asking so many questions.
-
I dit a scrub of the cache pool as Jorge suggested. Swapping the DIMM's. Removed 1 8GB DIM of RAM and restarted the server (no issues, accept for disk1). Scrub result (aft stick): S stopped the server and removed the 2nd stick. Reinserted the first stick. And ran a scrub of the cache pool again. Scrub result (fwd stick) apart from the 2056 uncorrectable errors?! they look the same.
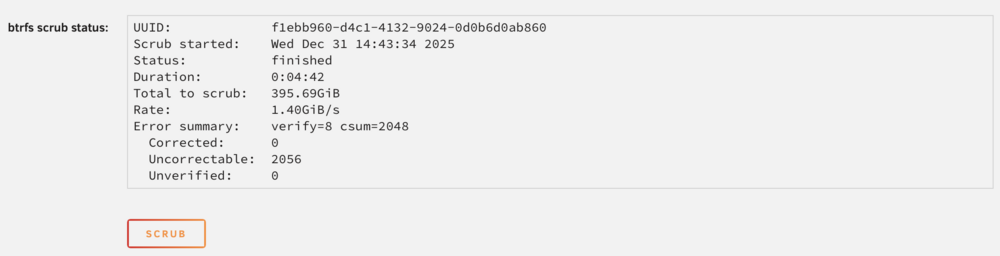
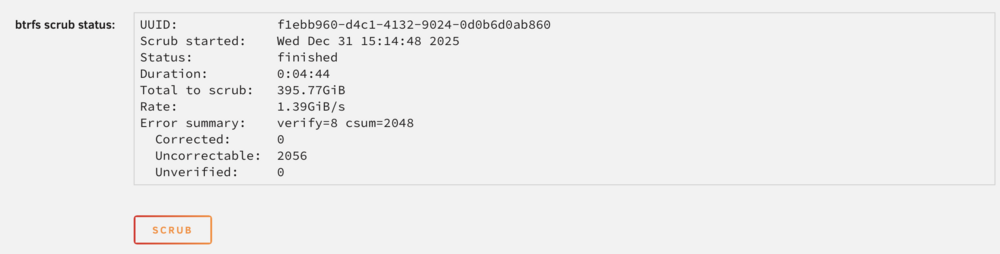
-
Sorry, don't want to spam. But as an additional question regarding rebuilding disk1. Should I run xfs_repair on disk1 first? Dec 30 20:33:41 Tower kernel: XFS (md1p1): Mounting V5 Filesystem 8c6a785e-215a-4193-b49b-741cfb95f8c2 Dec 30 20:33:42 Tower kernel: XFS (md1p1): Corruption warning: Metadata has LSN (40:2960824) ahead of current LSN (40:2958096). Please unmount and run xfs_repair (>= v4.3) to resolve. Dec 30 20:33:42 Tower kernel: XFS (md1p1): log mount/recovery failed: error -22 Dec 30 20:33:42 Tower kernel: XFS (md1p1): log mount failed Dec 30 20:33:42 Tower root: mount: /mnt/disk1: wrong fs type, bad option, bad superblock on /dev/md1p1, missing codepage or helper program, or other error.
-
Ok, that means doing the scrubbing of the cache before touching disk1. Would that possible mean that disk1 will be mountable again? That for example memory error can cause this 'unmountable: wrong or no file system'
-
I have ordered a new HDD to replace (if necessary disk 1). They are all bought around the same time and disk 2 failed July 2025 they are 5+ years old). I mean it start giving errors around that time. Not sure exactly what anymore as I just replaced the disk and rebuild parity without issues. No reason (at that time) to start looking for other problems. Unless there is something else to do before replacing disk 1, please let me know. I make sense to me to replace this disk before continuing but I am not a community expert 😄 so yeah what do I know. I am considering to purchase an extra nvme just in case one of the current nvme fails. Would you recommend to add this to the pool beforehand or just to wait until a nvme fails, then replace? So first steps: unless someone has a better approach! replace disk1 and rebuild run a parity check scrub with removed DIMMS as suggested by Jorge to see if there is a memory issue
-
What do you exactly mean with file system repairs? Replacing disk1 or the nvme?
-
The second SSD (1n1) I purchased a couple of years later than the 100% used one 0n1 so that likely explains the difference. Not sure exactly when I purchased it put it will be around 2024/2025 so around 4+ years younger. So, regardless of whether the error is coming from the memory or the NVMe, it looks like it is sensible to replace the NVMe with a new one (at least the 100% used one)? What would be the best way to keep an eye on this? A Docker app called Scrutiny or just have a look at it periodically? I never received an error/warning/suggestion about the NVMe reaching its (calculated) lifespan. Will try this next opportunity just to make sure. I hope it is not the memory though, talk about a bad time to have your memory go bad. With the server now up and running (maybe temporary) what would be your suggestions for backing up and data loss prevention? So far I have done the following: appdata backup flash backup Update:As I was typing this I noticed that I got a new error: Did not see that error before (related to this issue I mean). Got a drive that failed on me last year but that was since replaced by the Seagate. tower-diagnostics-20251230-1931.zip

-
4 passes no errors on Memtest. Restarted the server. Docker image is up and running again. Scrubbed nvme0n1 see attached screenshot. Also common problems found: Do I need to scrub the other nvme also? I did not yet started with assistance mentioned in the 'suggestion fix' from the coming problems plugin. I would like to continue with community support first. Which has been excellent. tower-diagnostics-20251230-1644.zip
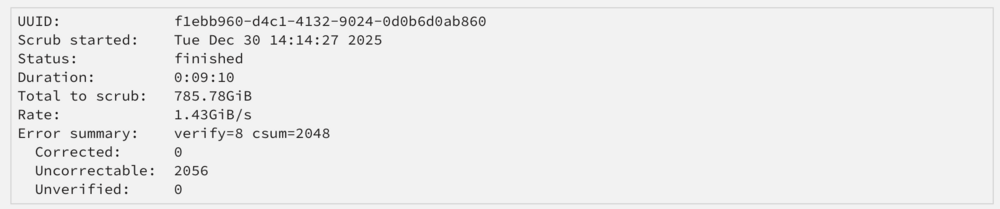

-
Ok, have two passes done. No errors. Will let it run for a couple of hours more as I am going out of the house any way. Will keep you posted.
-
Will do straight away, thanks for the fast feedback. Just an extra question: let's say that some memory is bad, would that mean that the pool cannot be saved/repaired? That I have data loss? update: Memtest is ongoing. It has been running for 20 minutes and gave me a "pass" (0 errors). The Memtest is still running right now. gr Piet.





