




reyo
Members
-
Joined
-
Last visited
Everything posted by reyo
-
Oh, I don't know. BTRFS has killed at least 1 NVME drive with metadata writes. We hosted production from Unraid NVME drive which was formated BTRFS. The files got corrupted, files were lost, etc. BTRFS isn't production ready. What ever the people tell. Formated XFS and all is good, on the same NVMe.
-
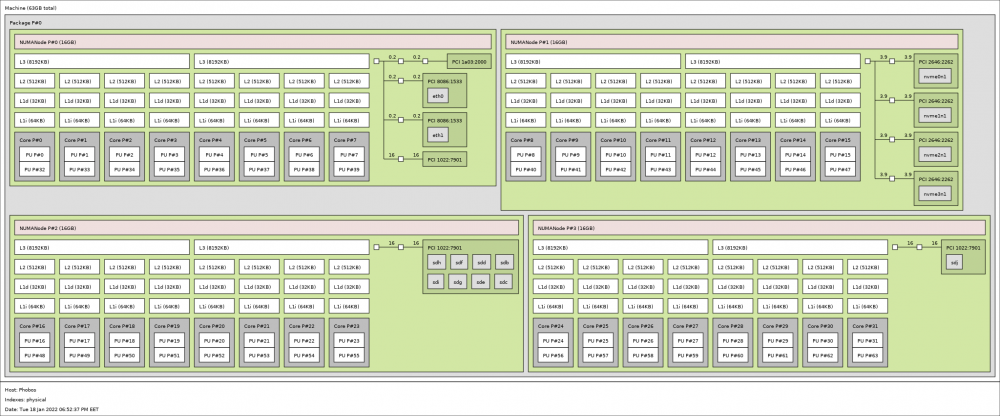
This is my current layout Very-very good stuff! Supermicro H11SSL-i Thank you @ghost82 and @SimonF
-
So @ghost82 was exactly right. Didn't know that you could request information like this: This is the output available: 4 nodes (0-3) node 0 cpus: 0 1 2 3 4 5 6 7 32 33 34 35 36 37 38 39 node 0 size: 15987 MB node 0 free: 159 MB node 1 cpus: 8 9 10 11 12 13 14 15 40 41 42 43 44 45 46 47 node 1 size: 16124 MB node 1 free: 51 MB node 2 cpus: 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 node 2 size: 16124 MB node 2 free: 50 MB node 3 cpus: 24 25 26 27 28 29 30 31 56 57 58 59 60 61 62 63 node 3 size: 16122 MB node 3 free: 49 MB node distances: node 0 1 2 3 0: 10 16 16 16 1: 16 10 16 16 2: 16 16 10 16 3: 16 16 16 10 Memory is taken the nearest memory controller for the die / CCX? When a process runs at node 3 (the way that docker spawns processes), then it the memory could be allocated from node 0, then latency happens? It's probably best to make dedicated VM-s, because then the nearest memory is allocated. Sorry for my bad English and my lack of understanding on chip level :), haven't really looked at CPU diagrams and tried to make sence how stuff works on die level.
-
Thank you! But wouldn't CCX-5-8 cross die. Wouldn't it be faster if CCX5-6? I read somewhere that best performance would be 4x 8 core VMs, or whatever configuration, untill no cross-die configuration is used. Because of the L3, probably. This die / CCX configuration is much appreciated! Also, how much this die crossing will affect performance / latency. Running a docker based web server, currently on the host itself, but thinking to make 3x 8c/16t VMs (3 dies). Would the performance be better or will it be neglectable (drive backend is raid 1, nvme). My thoughts are that maybe the extra latency virtualization adds and the gains from sticking within a die are outweighted.
-
Hi! I just remembered that Naples is 4x 8c/16t dies on 1 SoC and die sharing is bad for performance. Also RAM sharing isn't good for performance, but this can't be controlled I think. PS. I'm kinda new with all this EPYC stuff Thanks in advance

-
-
Just view it as XML, find the clock section and change the <clock offset='localtime'> to <clock offset='utc'> . Seems like Windows wants UTC as base and adds the timezone to that. Thats why the time goes wrong: it gets localtime from host (which is already +3h e.g) like 14:00, adds offset +3 and you get 17:00. Which is 3 hours ahead.


