

bigbangus
-
Posts
234 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by bigbangus
-
-
On 4/16/2024 at 11:11 AM, JorgeB said:
Lots of call traces logged, but unclear to me what cause them, was this a one time thing or is the server crashing regularly?
@JorgeB I forgot I had issues running the Google Coral USB and Cyberpower Backup USB on my main motherboard USB and I since moved them to a PCIe USB expansion card.
I recently took the expansion card out and the same issues came back... crashing on 02:00.0 which is my main USB on the mobo.
My bad, sorry to waste your time, I should have remembered I did this two years ago. I put the PCIe back and it's fine now.
-
 1
1
-
-
On 10/26/2023 at 1:39 PM, SimonF said:
Rename /usr/local/sbin/qemu to qemu.old then start VM manager disable auto start and then rename the file back
Saved me! Was stuck cause my bindings changed when I added a new PCIe card.
Is it reasonable to request a feature where you can force disable autostart to all VMs from the VM settings to avoid this situation when there are hardware changes?
-
My server crashed but I can't interpret the logs.
Luckily I record the Unraid log to my pfSense box. See attached with current diagnostics.
Thanks!
pfSense_Unraid_2024-04-16_Crash.txt unraidnas-diagnostics-20240416-1039.zip
-
2 hours ago, trurl said:
Shutdown, check connections, reboot, post new diagnostics
Will do, won't be able to get to it physically in a couple of weeks. Keep posted.
-
On 1/30/2024 at 4:08 AM, JorgeB said:
I would recommend posting the diagnostics first, disk1 may have dropped, not failed.
thank you
-
My disk 1 has failed on my backup server and the parity is still good.
Can I just make my parity my disk 1 and forget about redundancy all together on this server. Is there a way to do that?

Thanks.
-
I just have to highlight that mapping /cache in the container to /tmp/espcache on the host results in significantly faster compiling speeds in ESPHome. So if you feel like it takes forever to update your ESPHome devices because of slow compiling, I will definitely recommend this change.
-
39 minutes ago, digiblur said:
Probably due to all the disk I/O and that's the UnRaid not the container. You can try mapping to the folder /cache in the container to say /tmp/espcache on the host. If of course you have enough memory to hold the temp files. It speeds things up quite a bit.
Yup it's dialed now. Thank you sir. is this worthy of a template update? I feel like this should be standard.
And on a personal note, welcome to the bald head club. It suits you well!
-
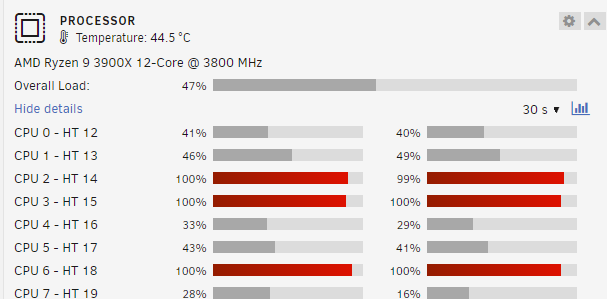
Why does ESPHome utilize all the processors available to my docker service when building the firmware to update an ESPHome device?


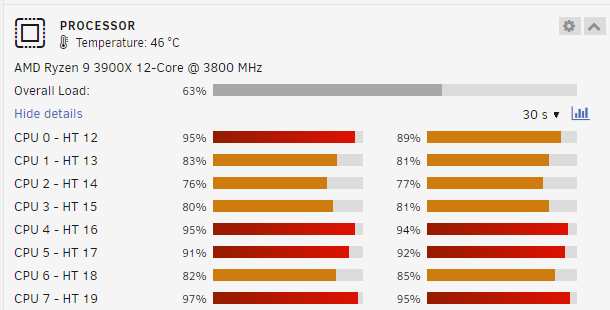
-
On 8/16/2023 at 2:19 PM, Wolfhunter1043 said:
This helped me out, but spoke to soon again. Mixed up the u- where it should be -u
Thank you!
sudo -u abc php /app/www/public/occ db:add-missing-indicesOn 8/16/2023 at 7:23 PM, Conson Droppa said:@Wolfhunter1043 Caught the "u-" typo too but thanks for the post.
Fixed in the post. Sorry for the typo fellas if it wasn't hard enough already to chase the occ debacle. Glad I could help.
-
Spoke too soon. It's now apparently:
sudo -u abc php /app/www/public/occ db:add-missing-indices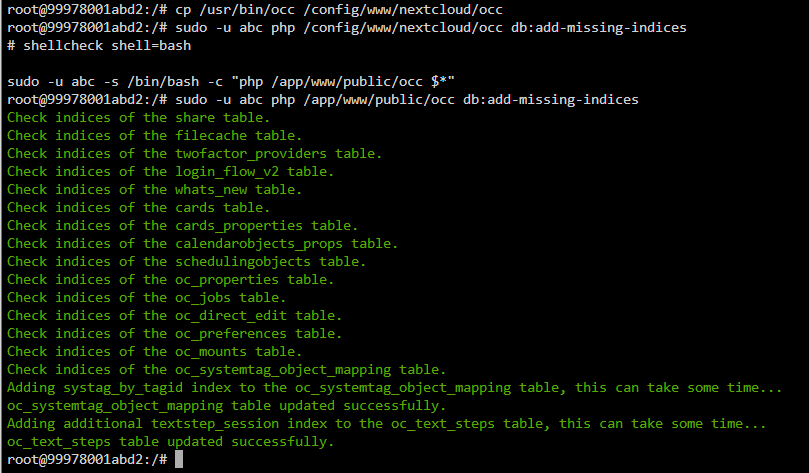
-
2
-
-
Any idea why this command in the nextcloud console window doesn't work anymore?
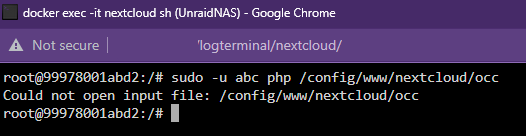
I'm trying to run
sudo -u abc php /config/www/nextcloud/occ db:add-missing-indices
but it's like the file is not there anymore
-
1 hour ago, jfoxwu said:
However, the only changes I made are in accordance to swag nextcloud's proxy template so to pass the nextcloud's security check (e.g. enabling add_header X-Frame-Options..., etc.). How do you deal with this?
You add them to the nextcloud proxy-conf in swag. Here is what mine looks like with all the comments removed:
server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name nextcloud.*; add_header Strict-Transport-Security "max-age=15768000; includeSubdomains; preload;"; include /config/nginx/ssl.conf; client_max_body_size 0; location / { include /config/nginx/proxy.conf; include /config/nginx/resolver.conf; set $upstream_app nextcloud; set $upstream_port 443; set $upstream_proto https; proxy_pass $upstream_proto://$upstream_app:$upstream_port; proxy_buffering off; proxy_max_temp_file_size 2048m; } }and then make sure your proxy.conf which is referenced above is back to default in swag as such:
## Version 2023/02/09 - Changelog: https://github.com/linuxserver/docker-swag/commits/master/root/defaults/nginx/proxy.conf.sample # Timeout if the real server is dead proxy_next_upstream error timeout invalid_header http_500 http_502 http_503; # Proxy Connection Settings proxy_buffers 32 4k; proxy_connect_timeout 240; proxy_headers_hash_bucket_size 128; proxy_headers_hash_max_size 1024; proxy_http_version 1.1; proxy_read_timeout 240; proxy_redirect http:// $scheme://; proxy_send_timeout 240; # Proxy Cache and Cookie Settings proxy_cache_bypass $cookie_session; #proxy_cookie_path / "/; Secure"; # enable at your own risk, may break certain apps proxy_no_cache $cookie_session; # Proxy Header Settings proxy_set_header Connection $connection_upgrade; proxy_set_header Early-Data $ssl_early_data; proxy_set_header Host $host; proxy_set_header Proxy ""; proxy_set_header Upgrade $http_upgrade; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Host $host; proxy_set_header X-Forwarded-Method $request_method; proxy_set_header X-Forwarded-Port $server_port; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-Server $host; proxy_set_header X-Forwarded-Ssl on; proxy_set_header X-Forwarded-Uri $request_uri; proxy_set_header X-Original-Method $request_method; proxy_set_header X-Original-URL $scheme://$http_host$request_uri; proxy_set_header X-Real-IP $remote_addr;
-
 1
1
-
-
8 minutes ago, jfoxwu said:
I checked my reverse proxy conf file and noticed the default from swag's documentserver proxy conf template uses http/Port80 instead of https/Port443. I changed it to https and 443 just like yours and clear the cache of my browser. After restarting swag, I can access documentserver from my public domain url just fine. However, I am still suffering the same issue.
No idea what is going on. For now I have setup up Collabora. Will revisit this if there is new update to either documentserver or the onlyoffice nextcloud plug in.
what do you mean exactly still suffering the same issue while still being able to hit it fine from your public domain url?also what have you configured in the Nextcloud ONLYOFFICE settings for urls?
-
On 7/5/2023 at 9:23 PM, jfoxwu said:
+1, I am having this problem as well.
As far as I can tell, documentserver is working correctly. I can access through reverse proxy, and the example editor test works just fine. The nextcloud's onlyoffice plugin can connect to the document server. However, nextcloud can no longer open any of the office files within the browser. Using Edge/Chrome will result in the same error message "refused to connect." Using firefox will either show a blank page, or a warning message saying it cannot open an already embedded page within the tab.
So I managed to solve the issue. I believe I had a combination of errors in my swag nginx config files. I returned all my swag nginx configs back to default (ssl.conf, proxy.conf, resolver.conf, nginx.conf).
Also here is my onlyoffice proxy-conf
GNU nano 7.2 onlyoffice.subdomain.conf ## Version 2023/05/31 # make sure that your onlyoffice documentserver container is named documentserver # make sure that your dns has a cname set for documentserver server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name onlyoffice.*; include /config/nginx/ssl.conf; client_max_body_size 0; location / { include /config/nginx/proxy.conf; include /config/nginx/resolver.conf; set $upstream_app OnlyOfficeDocumentServer; set $upstream_port 443; set $upstream_proto https; proxy_pass $upstream_proto://$upstream_app:$upstream_port; #proxy_redirect off; } }
And finally, delete all your browser cache and restart your browser. Also after trying to open a document in nextcloud, if you still get a refuse to connect, do a Ctrl+Shift+R and it may work. This was my major problem. I had solved the issue but kept going back because my browser cache was all jacked up.
Hope it works, let me know.
-
1
-
-
I don't know if this is the right place to do this, but want to say a general thank you to all the contributors and lime tech developers for Unraid 6.12. The GUI enhancements are excellent and the new appdata backup plugin is really polished.
I've not dabbled in ZFS yet, but just really happy with Unraid. I started my journey into the home lab around COVID time and Unraid is what sparked my curiosity for self-hosted applications. It's now one my main hobbies and passions and I don't think I would have explored as far as I did without Unraid and all the wonderful SpaceInvaderOne video tutorials.
Thank you.
-
2
-
-
Ok got it. That's a day I'll never get back but at least I'm back on the latest branch of minio/minio
First you have to make the bucket on the new S3 instance then you have to copy over the bucket contents.
mc mb minio/bucket mc cp --recursive minio_old/bucket/ minio/bucket/
-
 1
1
-
-
On 11/7/2022 at 10:17 AM, cheesemarathon said:
Then from your old minio data directory copy your .minio.sys/config/config.json file and put it in the same location in the new minio data directory. Both containers should now be running and you can use mc cp or mc mirror to move the data to the new minio container.
PAIN! I got this far. What are the commands to copy buckets from 'minio_old' to 'minio'?
-
On 6/11/2023 at 4:55 AM, JorgeB said:
Unfortunately there's nothing relevant logged.
what about this part?
Jun 10 04:16:25 unraid CA Backup/Restore: done! Jun 10 04:16:27 unraid kernel: NVRM: GPU at PCI:0000:04:00: GPU-43924f5b-3d1d-9fb3-4784-c566475994c7 Jun 10 04:16:27 unraid kernel: NVRM: Xid (PCI:0000:04:00): 79, pid='<unknown>', name=<unknown>, GPU has fallen off the bus. Jun 10 04:16:27 unraid kernel: NVRM: GPU 0000:04:00.0: GPU has fallen off the bus. Jun 10 04:16:27 unraid kernel: clocksource: timekeeping watchdog on CPU0: hpet wd-wd read-back delay of 201711390ns Jun 10 04:16:27 unraid kernel: NVRM: A GPU crash dump has been created. If possible, please run Jun 10 04:16:27 unraid kernel: NVRM: nvidia-bug-report.sh as root to collect this data before Jun 10 04:16:27 unraid kernel: NVRM: the NVIDIA kernel module is unloaded. Jun 10 04:16:27 unraid kernel: clocksource: wd-tsc-wd read-back delay of 201779346ns, clock-skew test skipped! Jun 10 04:16:27 unraid kernel: xhci_hcd 0000:04:00.2: Unable to change power state from D3hot to D0, device inaccessible
And then this at the very end before the involuntary reboot:
Jun 10 04:17:18 unraid kernel: clocksource: timekeeping watchdog on CPU15: hpet read-back delay of 201719282ns, attempt 3, marking unstable Jun 10 04:17:18 unraid kernel: tsc: Marking TSC unstable due to clocksource watchdog Jun 10 04:17:18 unraid kernel: TSC found unstable after boot, most likely due to broken BIOS. Use 'tsc=unstable'. Jun 10 04:17:18 unraid kernel: sched_clock: Marking unstable (3266968550854251, -36363093365)<-(3266932404371485, -216638034) -
I had a crash this morning roughly at 4:30am. My daily backup is at 4:00am so not sure if it's related.
The server has rebooted and is now operating. Could someone take a look at the logs? I send them to my pfsense syslog-ng no it should have captured the before and after.
Thanks!
-
Crickets. Can anyone help with this issue. I tried reaching to OO for support and they said Unraid not supported
 which I think means they just don't understand Unraid is linux + dockers.
which I think means they just don't understand Unraid is linux + dockers.
https://forum.onlyoffice.com/t/nextcloud-server-settings-pass-but-cant-open-document/4961/7
Maybe someone could share a working nginx proxy-conf with me. Here is what I have
server { listen 443 ssl; listen [::]:443 ssl; server_name onlyoffice.*; include /config/nginx/ssl.conf; client_max_body_size 0; location / { include /config/nginx/proxy.conf; include /config/nginx/resolver.conf; set $upstream_app OnlyOfficeDocumentServer; set $upstream_port 443; set $upstream_proto https; proxy_max_temp_file_size 2048m; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } }Healthcheck in nextcloud is true, but then opening any document I get "onlyoffice.xxx.xx refuses to connect"
-
I've got a weird issue. The health check for ONLYOFFICE config is good in the Nextcloud > Admin Settings > OnlyOffice > Server Settings

but whenever I try to click on a Document in Nextcloud to start editing, I get this:
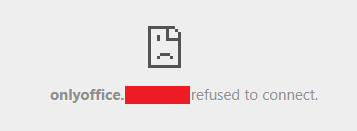
Can anyone point me to the relevant logs or how to start diagnosing this?
-
2
-
-
Just happened to me while I cherry picked some container updates that were pending for days. I finally had only 2 left to update and I hit update all and they just looped forever. Maybe this is a reproducible pattern to test with devs.
Had to restart server.
-
1
-
-
For those with cloudflare, I followed this tutorial here to setup my cloudflare DDNS update: cloudflare-ddclient
docker container log:
------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io ------------------------------------- To support LSIO projects visit: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [custom-init] No custom files found, skipping... [ls.io-init] done. SUCCESS: updating <domain.tld>: IPv4 address set to <x.x.x.x>














How to convert parity disk to disk 1
in General Support
Posted
Finally the disk did fail. I kept trying to rebuild it and preclear it. I swapped the SATA cables and port and still same issue. I ordered a replacement. Thanks for all the help fellas. Learned a lot.