Jackal
Members
-
Joined
-
Last visited
Everything posted by Jackal
-
Hi @browned, I have the same HBA card, HPE H240, on a Supermicro motherboard. Can you please tell me how did you find the relevant disk index number? I guess it is the "smPort1" variable in the smart-one.cfg script, correct?
-
Hi @Daniel Ayers, Didi you intalled some how "ssacli" tools in Unraid? Could you please share how did you do that? Thanks in advance!
-
I would like to store my cache drives (SSDs) into a case like the following ones, where you can store up to 6x drives in 5.25'' space. Any recommendations? 1. Icy Box Raidsonic: IB-2260SSK-12G [https://icybox.de/en/product.php?id=355] 2. Icy Dock ExpressCage: MB326SP-B [https://www.icydock.com/goods.php?id=231] I have seen a few users using the MB326SP, however I was leaning towards the Raidsonic with the metal enclosure. Please let me know if you have any ideas/prior experience e.t.c.
-
Well, the following settings worked for me. I also discovered, this is what it is used by the 'preclear' plugin in order to extract attributes and information. I hope I am not doing something wrong here New Information Added, that cleared things up for me more. This is taken from the smartctl (8) - Linux Man Pages

-
Hi all, I am reviving this thread because since a little while ago I got a 2nd hand H240 because I saw it was a plain HBA and should work out of the box. Today upon testing, I realized that there might be a problem with the HDD temperatures. They are not show up, as well as the SMART attributes. I saw that @ezhik made a post a couple of years back as well. Playing around I just stumbled upon the following parameters that one can setup optionally in Unraid and now the temperatures are shown up properly in the GUI. Is this all that one has to do? What happens if a disk changes a letter after a reboot (or after being failed from the array)? However I realized that SMART attributes do not appear. Is there a solution about that by any chance?


-
Hi @Xaero . I really appreciate following up on my problem. Had it not been for this problem I would not have gathered all this information. So far all the DIMMs in pairs have been tested successfully, as well as 4 of them at the same time. Now, I am waiting for a test with all of 6 of them installed in slots except the "problematic" one. It may not be in the motherboards recommended mode of operation but what shall I do. Next test is to test once again the "problematic" slot and see if the error is reproduced. And then I am definitely following your advice and pop the CPU out for inspection/cleaning etc during the weekend. I have done that many times in the past before, but last time I did such a thing, I discovered 2 bent pins in the cpu socket and it took me a while to bring back the system in a working state. Not a very pleasant memory ;-). But will definitely do if necessary. Thankfully all this will end up pretty soon, as I want to move on, choose a case, and start putting the parts together ...!!!
-
Now I have started testing the modules in pairs to see which one is the faulty one. So far 2/6 DIMMs passed the stress tests without producing any ECC errors. Now I am quite sceptical if there is something wrong with a specific RAM slot according to @Xaero. Let us see ... 4 more hours remain to see what is going on with these two DIMMs.
-
Thanks a lot @Xaero. It seems that I have some testing in front of me. The thing is that I do not have a known good memory module that I can swap. I am testing these that the system came with to see which is bad and which is not. Now you are making me scary !!! I hope this is not going to be anything than a bad memory module...
-
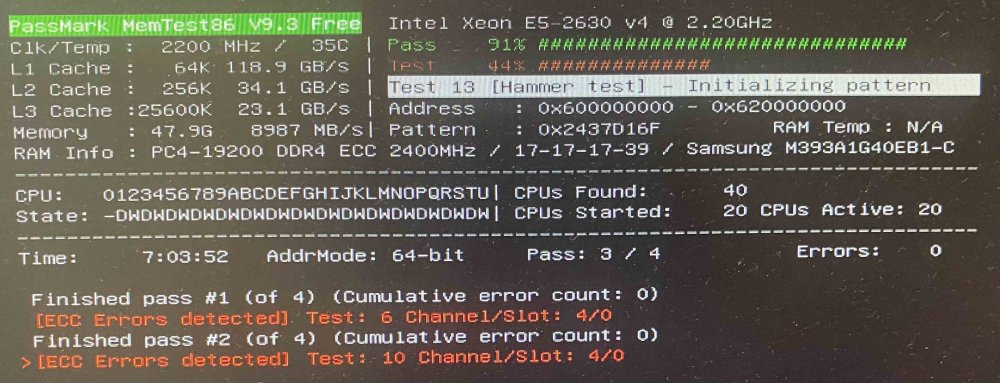
Hi all, I recently got my hands into a SuperMicro X10DAI with (2x) E5-2630v4 CPUs and (6x) 8GB RDIMMs of RAM which I will become a multipurpose server. So far so good What I found out today after testing the RAM, for a second time in a weeks-period, is that I get some ECC errors. Well, it is just "2" but shall I be worried / no-worried / semi-worried / forget and re-check it again after an X-amount of days/months? It seems that the system responds and corrects the errors but...? Furthermore, since I do not find any answer in the manual, which one is Channel 4? In other manuals I have seen detailed information regarding RAM population. In this one I can not seem to understand the "Fill First" Method. My Guess is that ------------------------- DIMM_00 ------- DIMM_02 Channel_00 --> P1-DIMMA1 & P1-DIMMA2 Channel_01 --> P1-DIMMB1 & P1-DIMMB2 Channel_02 --> P1-DIMMC1 & P1-DIMMC2 Channel_03 --> P1-DIMMD1 & P1-DIMMD2 Channel_00 --> P2-DIMME1 & P2-DIMME2 Channel_01 --> P2-DIMMF1 & P2-DIMMF2 Channel_02 --> P2-DIMMG1 & P2-DIMMG2 Channel_03 --> P2-DIMMH1 & P2-DIMMH2