

BVD
-
Posts
330 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by BVD
-
-
This is almost certainly your router settings. I'd start there.
-
I had severe dns latency when using airvpn years back, though never with that level of "exactly 9s" consistency.
If I'm remembering right, after pulling my freakin hair out for something like 3 days, I ended up finding ipv6 as the common underlying component... No idea "whose fault" it was - airvpn, RT-ac68u, FF [version 3 at the time], hell even .net as it was on both linux and windows machines, etc. I just found that once I squashed anything that even thought itself to be ipv6, it just... vanished.
Idk if that old-as-hell "problem", whatever it was, is still around, but figured I'd mention it given youd mentioned em.
Best of luck!
-
Sounding more like it has something to do with the way either mozilla or pihole is handling the myservers plugin - I'd start systematically narrowing it down from there, it certainly doesnt sound like its something in the servers config at this point
-
@benmandude I just realized you'd noted you *don't* have the same issue with chrome - that pretty well negates the questions posted above (well... not completely, but mostly hehehe), I really should've re-read before pulling down the HARs lol 😅
We're spending the vast majority of our wait time on DNS lookup:
"cache": {}, "timings": { "blocked": 0, "dns": 8999, "connect": 1, "ssl": 0, "send": 0, "wait": 24, "receive": 0 }, "time": 9024, "_securityState": "insecure", "serverIPAddress": "192.168.0.100", "connection": "80"The exact same amount of time for both the dashboard AND main/array pages - I'd start with restarting FF in safe mode. Having this happen only in one browser narrows this down quite a bit, and while it doesn't rule out unraid itself completely, it's certainly far less likely it's something server side.
At a glance, I'd venture one of your plugins is still causing issues. While I didn't spend a ton of time on it up to this point, a quick once-over show's us having issues with connecting to graphql, around the same time the my servers plugin is doing it's work. With our DNS lookups taking a full 9s, and in both instances happening right after protocol upgrade...
"response": { "status": 101, "statusText": "Switching Protocols", "httpVersion": "HTTP/1.1",... it seems more likely this is either an issue on the browser side; whether it's specific to Mozilla overall though or just one of your plugins interfering, we'll know more after your testing FF in safe mode.
-
Awesome! I'll try to check out the HAR tonight if time allows - if not, itll likely be next weekend due to work stuffs.
Quick questions -
* what're you using as your router (pfsense, opnsense, asus/tplink/etc) default/model, etc)?
* as for DNS - is apollo's mac and IP explicitly defined in your router, or relying upon the host and/or dhcp settings?
-
@benmandude Some things thatd help troubleshoot this:
* Testing on separate browser (Edge, Safari, Chromium, anything really)
* When you're seeing this, does clearing the browser cache help? If this is a pain, try using a private/incognito window, should provide a relative outcome.
* Connecting from another device - browser doesn't matter, just other system that's not logged in to your server's UI at that time
And for the "this is everything one could possibly need to see what's happening here" version (or at least point to the next place to check logs from at the very least):
* When you are encountering this, create a HAR file recording the occurrence and the share it here for analysis; this link has solid steps for doing so across multiple browser types. PLEASE take special note of the warnings section of the article - while creating the HAR recording, do NOTHING other than recreate/show the loading issue, then stop the recording (don't go logging into your bank or something silly like that lol)
If you go this route, attach the file here so it can be gone through. I'm sure the limetech guys can sort it out, but if it comes in this weekend, I should have time to look at it hopefully sometime Monday and see what I can make of it.
-
55 minutes ago, MacManiac said:
ok but an unassigned drive is not an array drive but a single drive. You can use it but you have no redundancy benefits.
That's unfortunately incorrect - I have ~30 drives in one of my unraid servers, but only two of them are used for the array; the rest are zfs, and all the data that matters on the server is on that zfs pool being served out by unraid.
To be more clear here as to why your best option to move forward with this is to run through the steps linked and disable the iLO provisioning component when not being used, here's my unraid array:

Meanwhile, all the data other than scratch space (which is what I use the unraid array for currently) is here (partial list):
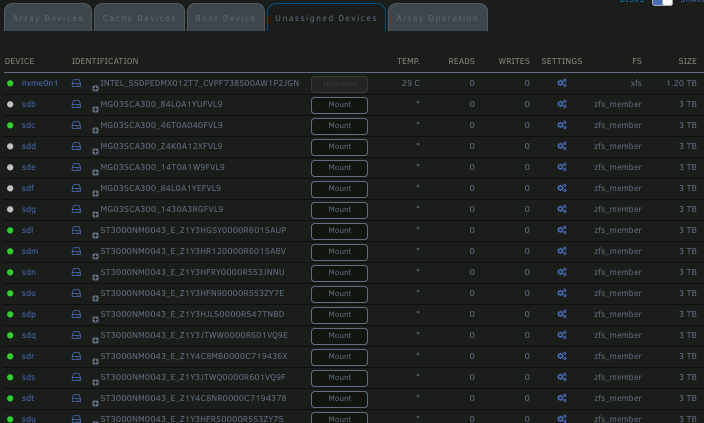
I get all the benefits of unraid's stellar community support, device passthrough, and UI (at the loss of power efficiency), but I'm not limited to just the two drives in the unraid array. If Limetech were to only make me pay for the devices I had in the unraid array, they'd really be doing themselves a huge disservice - it'd be financially infeasible.
Instead, they make the license based on the number of attached block devices - this offers us as customers the flexibility to use unraid whatever way we want to, while still allowing the business side of things to remain viable.
Hope this helps explain things a bit
-
That's not viable unfortunately as itd allow people to simply work around the license via the unassigned devices plugin (or zfs, or any number of other things)
-
I can't think of a way that Limetech could both address this in the OS, and still maintain the integrity of their licensing model. I'd incorrectly thought initially that this was something that just showed up after upgrade, but this is something that'd impact any version of UnRAID - it's not that the iLO *supports* attaching virtual block devices, it's that you have it running right now. Since the server is already 'provisioned', I'd disable it until such a time as you actually need to re-install something else (or boot something else, at which time you could easily re-enable in the BIOS):
First thing that came up when I searched for it should address it:
https://techlibrary.hpe.com/docs/iss/shared/config/activate.html
-
Sorry, I wasnt asking to install it, but to remove it if it existed. I'd attach diagnostics if you haven't pulled them yet...
How does iLO present virtual media? My supermicro board emulated a USB block device, and while I'm not anywhere I could test it at this point, I'd assumed a USB device wouldnt show up here.
One other thing I can think of - head to system devices, and stub the vendor ID of whatever virtual media mount is there; at least then itd disappear from view and you could start your array, while still allowing you to pass the connection to a VM while they sort it out
-
I bet the same thing would be seen for anyone using an out of band management module capable of virtually attached media (iDRAC from Dell, etc) - can you try unloading the iscsi driver to see if that's for whatever reason improperly noting network block storage as a physical drive towards your license limit?
From the terminal:
rmmod iscsi_tcp
Then refresh the page?
If that doesn't do it (and it might not, depending on when the license is checked), then we can insert this earlier by adding it to the modprobe.d config:
echo "rmmod iscsi_tcp" > /boot/config/modprobe.d/iscsi_override.conf
Then reboot - I'll be curious to see if it's specific to the addition of the iSCSI module, or if it doesn't care what virtual bus is used...
-
What chipset does that card use? It's not one of the Marvell based cards is it? If you're unsure, you can attach the diagnostics, or just check out the system devices page (should list it there hopefully as long as it's reporting correctly).
I've tried compiling the drivers to send you a copy to test, but it fails to make; after finding some (undocumented...) dependencies, I'd thought I'd gotten it corrected, but it just fails out a few lines further down. Tehuti's not really updated their driver source for some time from what I can tell, and their website is... well, calling it difficult to navigate would be generous (wordpress page? idk). Everything I can find related to their drivers is a mess, but I'm trying to sort through it. They really don't seem active in supporting their driver in the kernel

-
It looks like you have a Bond set up, but only one port configured within that bond, so docker believes the port to be 'down' (the mac address of the bond is already in use by the bridge, and duplicate mac addresses means whomever shows up first gets to be on the network while the other one can't).
Mar 1 19:43:55 Apollo kernel: bond0: (slave eth0): link status definitely down, disabling slave Mar 1 19:43:55 Apollo kernel: device eth0 left promiscuous mode Mar 1 19:43:55 Apollo kernel: bond0: now running without any active interface!
Did you previously have two NICs set up by chance?
Head to the network settings, disable bonding on the port (remove slave interfaces as well), and you should be set. The reason changing it to host or bridge works is because each of those relies upon the physical mac address, which is available on the network as soon as the server's connected and the network driver loads.


[6.10.0-rc1] WebUI Sometimes Slow to Load/Unresponsive
-
-
-
-
-
in Prereleases
Posted
I'd start with any packet inspection or blocking rules (e.g. surricata/pfblocker if using pfsense, that kind of thing). Short of that, I'd recommend creating a new issue report and including the same information the original user posted above.