urbanracer34
Members
-
Joined
-
Last visited
-
Just an FYI the docker in question has been updated: https://hub.docker.com/r/jlesage/nginx-proxy-manager EDIT: The source that the image has been based on had been updated as well: https://github.com/jlesage/docker-nginx-proxy-manager
-
Hello! Where is the other nginx proxy manager? and how easy is it to set up?
-
Sorry to Necro but I am having issues getting this to run. I have followed the instructions to the letter and now when I try to transcode anything, the unraid log gives a segfault (sample below) Direct Play works perfectly. I am using lscr.io/linuxserver/plex docker AMD Ryzen 7 5700G with Radeon Graphics @ 3800 MHz - Build is an HL4 from 45homelab. Where am I going wrong? May 12 17:10:52 GibsonMini kernel: mux0:stream_seg[942897]: segfault at 54 ip 000015203239726c sp 0000152024671570 error 4 in libavformat.so.60[19626c,1520322d0000+208000] likely on CPU 0 (core 0, socket 0) May 12 17:10:52 GibsonMini kernel: Code: 44 24 10 45 31 ed eb 22 48 83 c3 1c 48 8b 47 18 4c 8b af c8 00 00 00 4c 39 e8 44 0f 47 e8 44 2b 6f 08 49 89 ff 48 89 5c 24 10 <8b> 47 54 89 44 24 0c 85 c0 0f 88 1d 01 00 00 83 7c 24 60 00 74 3b EDIT: A new error has been found in the Plex Server Logs: /home/runner/_work/plex-conan/plex-conan/.conan/data/libdrm/2.4.120-6/plex/main/build/678777ee2ca8706ca90cf805e0dd88235f6d7f05/meson-install/share/libdrm/amdgpu.ids: No such file or directory EDIT2: GPU usage climbs up by a percent for a second and drops to nothing when transcoding.
-
Will the RTL8125 chipset be supported as well? And the Plug-in has an update available. What does it have?
-
I just rebooted and everything fell into place! Thanks!
-
I can't exit the window at all. I DO have a second webui browser open. Should I use that?
-
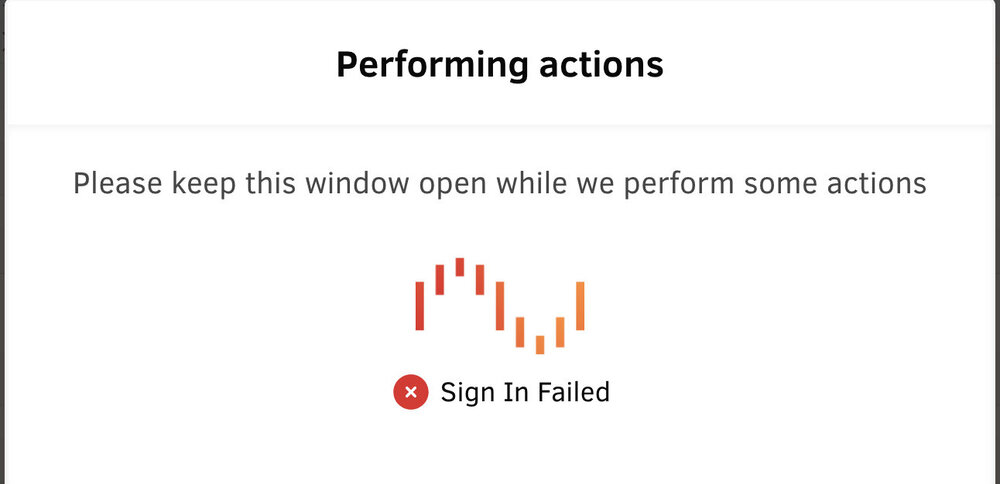
I followed your instructions and when I went to link it, it said "sign in failed" and it is stuck there. I don't want to break anything: I looked on unRAID connect and it shows it's on the account
-
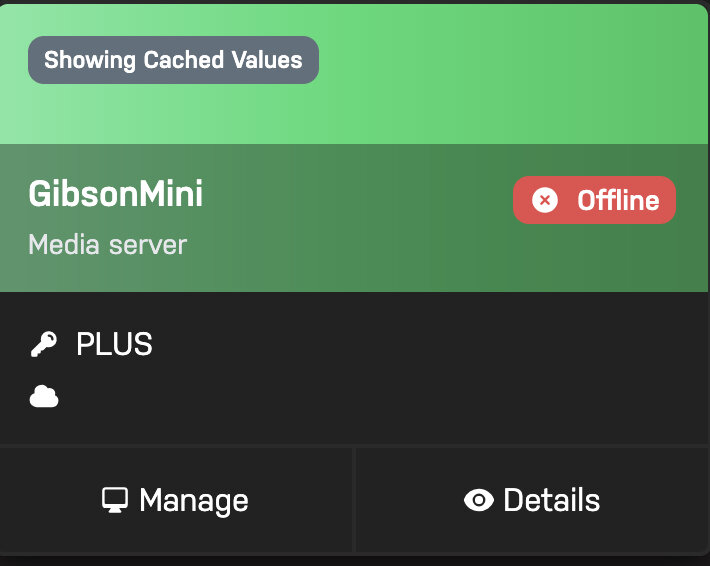
Here's what the server shows:
-
I'm not sure if I did register it. I did run into a problem when I was setting up the license for this particular machine. I stupidly copied over a license file from my old server to my new using a Mac. Something went wonky. I had to pull the usb keys from my old and new servers and transfer the license file over using a PC. I booted up the new server (this machine I'm talking about.) It then recognized that I wanted to use the old license. Of course, this one was from before the transition to the new model. I told it to adopt. It was a success.
-
Here they are. gibsonmini-diagnostics-20251110-0936.zip
-
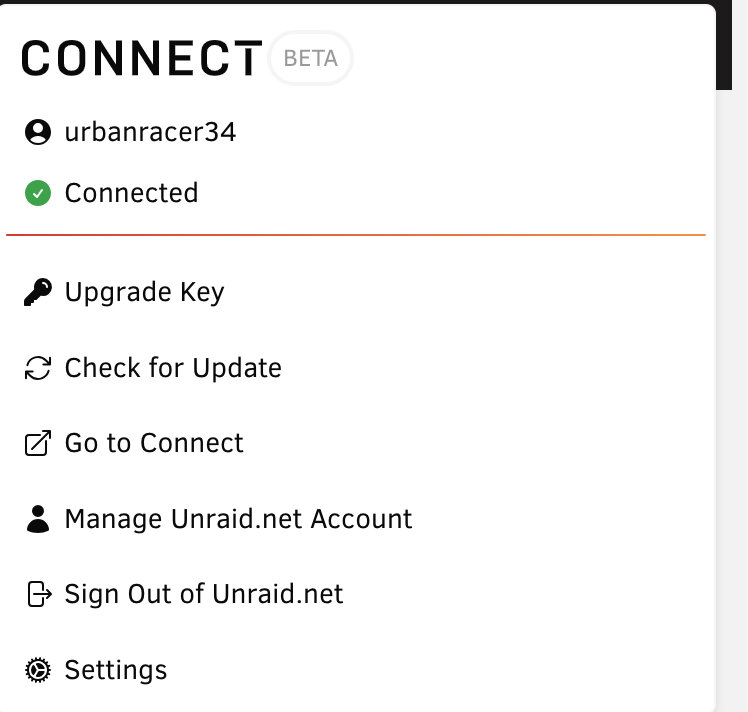
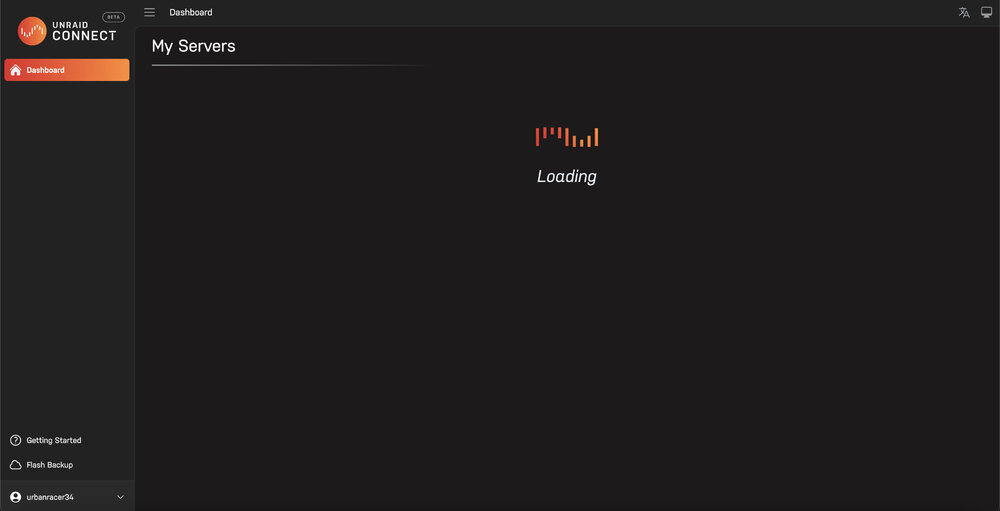
I go to access my server using Unraid Connect and it says "loading" endlessly. I've tried this across different browsers with no change. I also tried clearing cookies with no change. Where do I go from here?
-
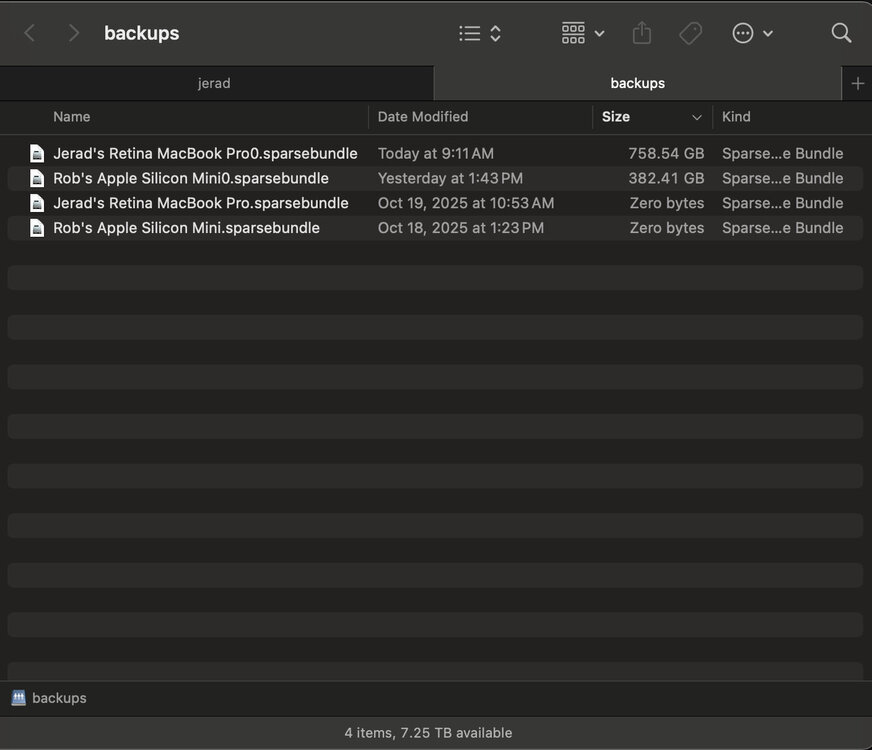
Stagger the timing of when I run the backups, correct?
-
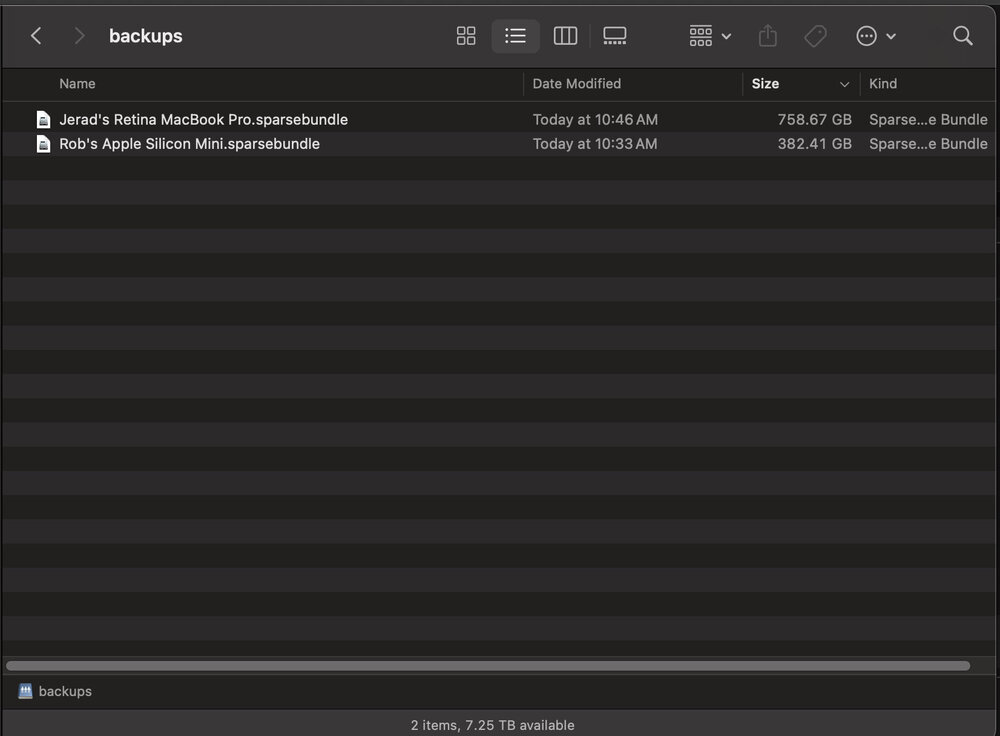
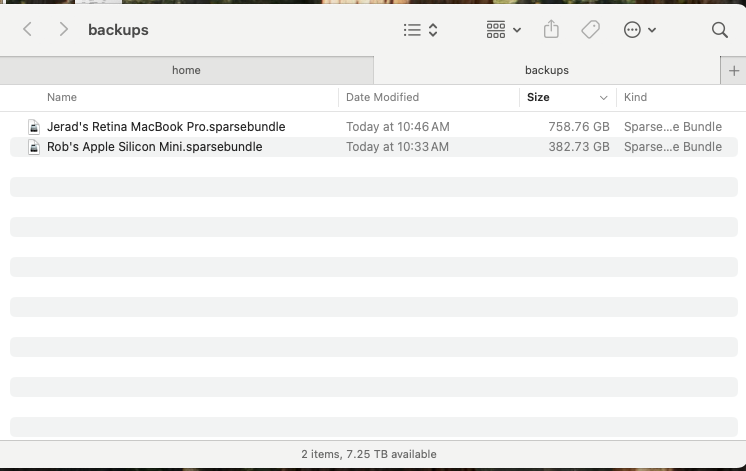
It worked! No more error messages. But I have another issue. Both the backups are being hosted on the share and are competing for the same space. Would it be wise to make separate shares and users for each machine? It's more work for me but I think it would work better.
-
Just deleted them! Here's hoping it works!
-
This is what they look like from the finder's point of view. Maybe I could try deleting the zero size ones and see if the errors continue?