



langrock
Members
-
Joined
-
Last visited
-
Those two variables still exist. What appears to be gone is the separate key pair used to access the web GUI. Right now it defaults to the ROOT access and secret key. You can define users and group within the web UI, though, which may then also allow those users with their separate keys to back up to the server, but I haven't tried that, yet. There's probably some document that explains how to generate compatible keys in case these need to fulfill certain requirements.
-
Fantastic, works again as advertised both for Arq and Duplicacity. Nice feeling to have the backup running once again!
-
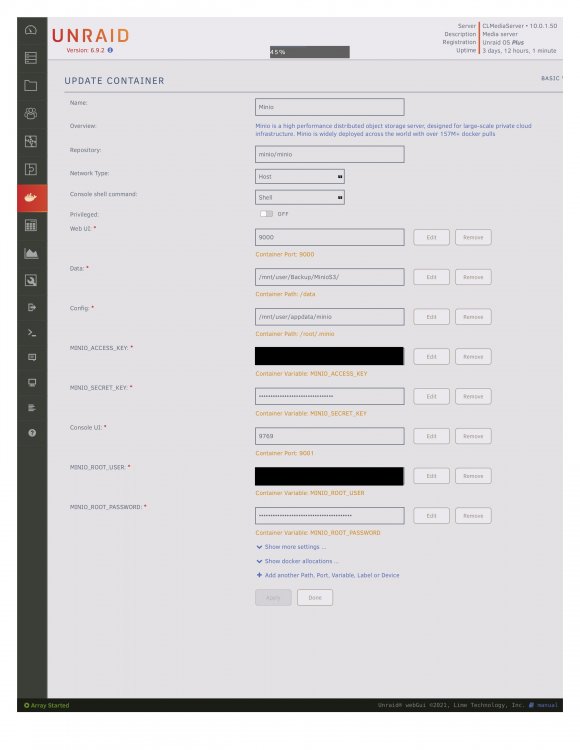
Thanks for looking into this. Would be super if this could be resolved. I am wondering if the container actually uses the as-defined access and secret keys. Screenshot attached. Please let me know if there's anything I can help with or if you see anything I should change about the configuration. Thanks
-
Looks like I am not the only one. I can no longer connect to Minio from Arq or duplicacy (CLI). I can still log into the Minio Web UI after having set the root username and password. It does show the previous buckets and such, so no data is lost. When trying to connect from Arq, I get From duplicacy Mind you, no changes have been made and the access and secret key are the same as always. I changed docker network type to 'Host' to get access to the GUI working again. Any suggestions about what to try next would be greatly appreciated. This used to work so well, it'd be a real bummer if I had to move to a different backup system:( Thanks
-
I can no longer renew the certs and am getting the following error message. I have changed absolutely nothing on either the server or the router in many years. Any idea if a recent update to the letsencrypt docker might be causing issues? The only web server running is the one serving the Unraid GUI ... this has not been an issue in the past. Thanks Update: I checked that the port forwarding worked and that I am able to access the apps I am linking to from the outside world, jellyfin and calibre-web in my case, and both still work just fine. The container log doesn't indicate any problems or warnings, but running 'certbot renew' still throws the above error. I am mystified.
-
Works like a champ! Thank you very much.
-
I am having the same problem as @Enkill with the S3 script. After upgrading to Unraid 6.8.3, I couldn't even start the server anymore. It redirected to http://server_address/update.htm when hitting the Start button; Reboot button redirects to http://server_address/webGui/include/Boot.php, and does not reboot either. There was also the same error message he is showing at the bottom of the Main tab. Removing the S3 plugin restored the normal functionality, but I really would like to be able to put the server to sleep since I only use it sporadically and cannot justify burning up the power to keep it on all the time. If someone could recommend a solution, that would be awesome! Re-installing it does not do anything for me either. The Sleep button doesn't even show up. So, for now, I suppose it's best to remove it and shut the server down until this can be fixed. Is there another way to sleep the server? Maybe over the command line? Thanks
-
There must be some sort of API already, otherwise how does Margarita , available for macOS, do this? Hadn't heard about ControlR, will check out.
-
I am having trouble installing this Docker image. I am getting the following error messages. Maybe those mean something to somebody on this forum and I'd appreciate a hint on what to try next. I tried both directly installing the Docker image as well as going through the Community Applications page. No luck, me sad:( --------------------------------------------- Pulling image: gfjardim/crashplan:latest IMAGE ID [2d02fe93d96e]: Pulling image (latest) from gfjardim/crashplan. Pulling image (latest) from gfjardim/crashplan, endpoint: https://registry-1.docker.io/v1/.'>https://registry-1.docker.io/v1/. Pulling dependent layers. IMAGE ID [f7eef3e8d2a5]: Pulling metadata. Error pulling dependent layers. IMAGE ID [2d02fe93d96e]: Error pulling image (latest) from gfjardim/crashplan, endpoint: https://registry-1.docker.io/v1/,'>https://registry-1.docker.io/v1/, HTTP code 400. Error pulling image (latest) from gfjardim/crashplan, HTTP code 400. TOTAL DATA PULLED: 0 B Command: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name="CrashPlan" --net="host" -e TZ="America/Los_Angeles" -p 4242:4242/tcp -p 4243:4243/tcp -p 4280:4280/tcp -p 4239:4239/udp -v "/mnt/cache/appdata/CrashPlan":"/config":rw -v "/mnt/user":"/UNRAID":rw -v "/mnt/user/Backup/":"/backup":rw -v "/mnt/disks/":"/unassigned":rw gfjardim/crashplan Unable to find image 'gfjardim/crashplan:latest' locally Pulling repository gfjardim/crashplan 2d02fe93d96e: Pulling image (latest) from gfjardim/crashplan 2d02fe93d96e: Pulling image (latest) from gfjardim/crashplan, endpoint: https://registry-1.docker.io/v1/ 2d02fe93d96e: Pulling dependent layers f7eef3e8d2a5: Pulling metadata f7eef3e8d2a5: Error pulling dependent layers 2d02fe93d96e: Error pulling image (latest) from gfjardim/crashplan, endpoint: https://registry-1.docker.io/v1/,'>https://registry-1.docker.io/v1/, HTTP code 400 2d02fe93d96e: Error pulling image (latest) from gfjardim/crashplan, HTTP code 400 Error pulling image (latest) from gfjardim/crashplan, HTTP code 400 The command finished successfully! --------------------------------------------- Thanks, Carsten
-
Hi, I noticed that the cache_dirs process will ignore the folder(s) specified in the 'Excluded folders (separated by comma):' section of SimpleFeatures GUI of unRAID 5.0.4. For example, I have a 'Plex" share which lives only on the cache drive. I had noticed that whenever cache_dirs was looking into this directory the CPU usage went up by a lot, >100% on a dual-core AMD machine. I was hoping that instructing cache_dirs to ignore this directory would work, but alas, I still see the process looking into this directory by issuing ps fo pid,cmd -U root on the command line at the right moment. The processes in question are /bin/bash /usr/local/sbin/cache_dirs -w -B -m 10 -M 600 -d 9999 -e 'Plex' 27607 \_ /bin/bash /usr/local/sbin/cache_dirs -w -B -m 10 -M 600 -d 9999 -e 'Plex' 27636 \_ find /mnt/cache/Plex -noleaf which does have 'Plex' as argument for the -e option. I also set the scan interval to 10 seconds since I didn't understand why this process would need to be run every second. Maybe I don't understand how to properly use the exclude function. I would appreciate helpful comments. The share I'd like to exclude is '/mnt/cache/Plex'. I had also tried to enter the full path name in 'Exclude folders' section with no success. Thanks in advance, Carsten

