




thedutchguy
Members
-
Joined
-
Last visited
Everything posted by thedutchguy
-
i agree, the question is what. i would very much not nuke my install and start over if this is an actual bug of some sorts that i found that can be solved without starting over.
-
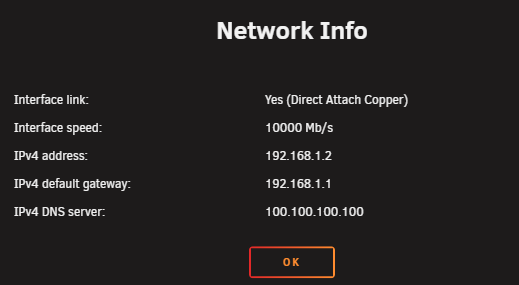
i did a reboot and unraid can go online now (checking for docker updates and stuff also works normally) so it seems the dns "took" but it still shows 100.100.100.100 on the info popup and verifying with nslookup in the terminal. after some slight googleing i found that this dns adress is used by tailscale internally. so i expect it actually didnt take and its still stuck on the tailscale dns. wich begs the question how or why unraid is locked into using my tailscale network as its only "way out" and refuses to accept anything else.
-
the info box doesnt say that (its still stuck on 100.100.100.100 and unraid is complaining it cant get online. note: the dns adress is a pihole and the router enforces all dns traffic to to go the pihole so no devices can bypass adblock and tracking. the pihole does not block any unraid traffic, it just doesnt get any according to its logs. the home assistant VM and dockers have no problem getting online as they have their ip and dns set in their own settings.
-
apologies, i uploaded the wrong file. now fixed.
-
Yello people. I found a interesting problem i have trouble fixing after upgrading my network. it seems my DNS settings are "stuck". i am capable of manually setting my ip (wich is needed) but i am unable to change my DNS after a network change. i used to be 192.168.1.20 and its been changed to 192.168.1.250. but unraid refuses to adopt these new 192.168.1.250 setting and remain stuck on 100.100.100.100 for whatever reason. its an adress i never used. while i am running the latest version i dont expect this issueto be related. before doing rash stuff i rather hear what the brain trust here has to recommend before breaking stuff. nasi-diagnostics-20260507-1818.zip
-
that would explain it. i have not used it in a while. is the feature to search/index for duplicate files also removed?
-
i noticed todat i am missing the button to do a extended test. is that feature removed or not working on the latest version of unraid?
-
You can also get the Transcend JetFlash 170 (in stock at RS online). its a 1GB stick with SLC memory. specifically made for industrial use. in practical terms it will never wear out.
-
thank you, that cleared the issue.
-
since i updated to 6.11 rc4 (might happend slighty before) i noticed the log is completly filled with this error: kernel: EDID block 0 is all zeroes this error repeats every couple seconds. unraid is running on a supermicro with ipmi and no monitor connected apart from the ipmi that is. The log has become basically useless as this error repeats every other second or so and after a few hours has filled up the log top to bottom. i would love to see how to get rid of this or what causes this. searching online for this error did not yield much useful results. syslog attached. syslog.txt
-
update: i have found the core issue after not seeling anything on the logs. it would appear the usb controller on the motherboard was slowly dying. i came to this as the system would not respond to the virtural keyboard on ipmi and neither would on most of the usb ports but worked fine on a separate 4 port usb pci-e card.
-
i have enabled that feature now and report back if i catch a crash.
-
that is a nice find. but that does not explain why this issue has only sprang up recently and has been getting worse in the last ~2 months when i have been running 6.9 and later 6.10 without issue. i have not excluded an usb stick fault (again) so far but its impossible to test as transferring the flash data invalidates the registration key and disables the array from running making the server useless (upsetting the family) and starting with a blank stick with a trial key makes me lose all the docker and share data wich also upsets the family. i did do a "surface" test on the usb stick (a sandisk extreme somethingsomething) and there are some speed hiccups when reading indicating the nand on the stick might be on its way out but without the abillity to actually replace the stick without contacting support to (again) prematurely replace the GUID on my licence within the year its not a cause i can diagnose.
-
Hello, i have been dealing with a instabillity that i cannot put my finger on on the exact cause. the system seems to crash at non-descript moments. it can be anything between hours or days. cpu load does not seem to be a factor. changing cpu features does not seem to have any effect. so far to exclude the "usual suspects" i have stripped the gpu out (and disabled VM manager) and tried way too many permuations of ram configs and i went down from 3 sticks of 8 gigs to 1 stick in an attempt to lower the amount of crashes i am currenty running as bare as possible. it does not seem to have much effect as the time between a crash can be days. the result of the instabillity is a hard lock to such an extent only a power cycle (that i thankfully can do via ipmi) will bring it back. the ipmi logs do not show any anomalies or recorded any power supply issues (wich is a high end seasonic). the lack of change in changing hardware around in the frequency of crashes does force me to look at the remaining constant: unraid. but i do not have the skill or knowledge to see or find any problems in the logs. i have attached the mandatory files and i hope someone can take a look at it and find some reason the system might crash. i would love to be able to fault find in a more targeted way by either being able to exclude unraid as a cause or find some issue. ps: could a dying usb stick cause this? i have a brand new SLC based industrial usb stick waiting to be used but the year between licence transfers has not been passed yet so i cant replace the stick yet. nasi-diagnostics-20220222-0025.zip

