

Nexius2
-
Posts
152 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Nexius2
-
-
Great question same conf on my side and about to do the same thing.
what I have tested for know:
- stop array
- remove parity dsk 1
- start array
- stop array
- add parity disk 1
- start array
My array is encrypted so it might be the cause (or the parity disk 2 but I doubt), but while rebuilt, the shares are not mounted so array not usable.
if you find a way to keep the array usable (and VM and Docker) while rebuild / add parity, I'll take it
-
I noticed today everything is ok (8To HDD are not spinning anymore), parity continues to work normaly. it seems to be a bug with the display in the array operation.
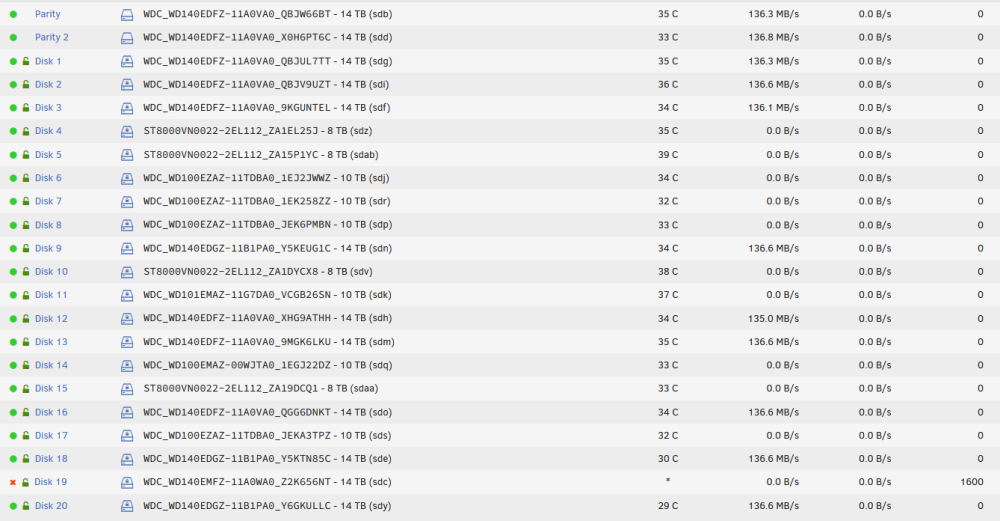
-
yes, disk20 was formated and data is written to it.
If I decide to re use disk19, it will be as a new hdd anyways. I'd guess rebuild is as usal, stop server, plug hdd, with array stop replace hdd and restart array.... it should do it's thing
")
-
thanks, I'll let it do it's thing until I receive the new HDD and will stop it then to replace HDD and check connections.
-
Just now, Vr2Io said:
Fine.
I just want to confirm does corrected parity check still in progress. If nothing have change it likely in stop.

nothing has changed since last night
-
every time I had this, it was written emulated but not this time....
but it seems to be.

-
-
is this what you want?
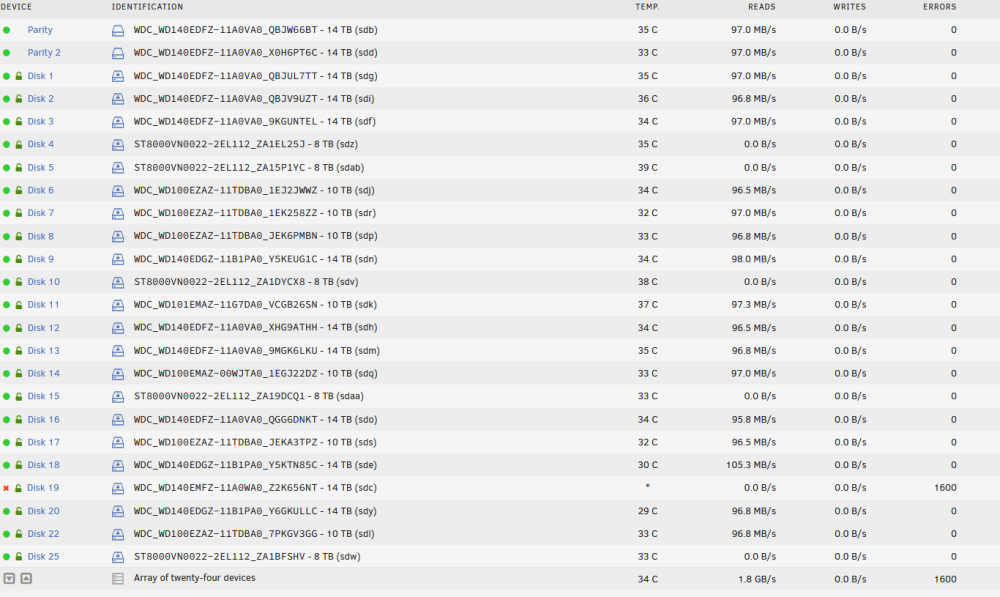
-
-
so, I added disk20 a couple days ago. no hot plug so I stoppd the server to add it. array was fine nothing to notice after array growth.
and 1 or 2 days after the parity check started (it stops at 18h and starts back at midnight).
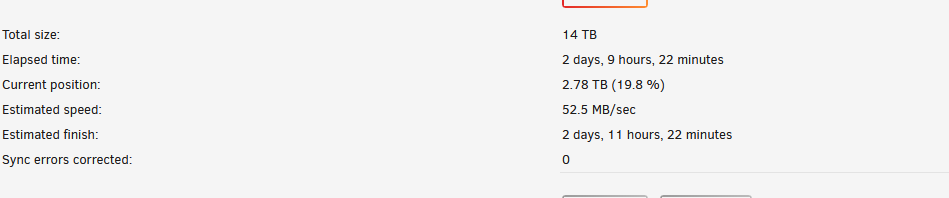
during the check it seems to have found errors on disk 19. since then, parity check has stopped, but I can see data move between all the HDD as if it was still going on.
I just notice sdac has appeared (thanks to you) don't know if it's good, it will be changed anyways.
maybe some power plug has moved while adding disk20....
but nothing realy explains why parity is stuck at 19.8%
-
Hello, a parity check started Monday morning and it detected a HDD failure. no problem, I have 2 parity drives and I ordered a new HDD for replacement.
but I have noticed the parity check stays at 19.8% since last night. since I'll have to stop the array to replace the HDD is it something normal? will it end eventually or no chances?
thanks
-
latest version of unraid and cleared cach (new computer) didn't change anything.
I'll stay on old version until correction
thanks
-
I'm thinking of adding a GPU in my server, can this plugin work with 2 GPU's? (intel CPU and NVIDIA card)
thanks
-
same thing for me, updated and not working 😕
version 2.7.2-4-01 works
-
solved....
made the same test on another serveur and updated at same time, same issue.
data seem to be written fills up and... deleted, but warning appears during issue.
a reboot and no more message
-
Hello,
I updated one of my servers last night from 6.11.2. didn't have issue before, no changes done recently and this morning I have "Invalid folder Backups contained within /mnt" ( i posted in "[Plugin] CA Fix Common Problems" but I realize i might have some reel issue) and "Rootfs file is getting full (currently 83 % used)" error messages.
all i can find about this is from RAM being full, but I have 48Gib and only using 28%. i'm guessing I have a reel issue because when I try to move a file (10gb) from a share to another (both on the same cache drive) it takes a couple secondes, just like it would between 2 drives. yesterday, it was instantly done.
I have a script that mounts to another server and rsync data every night. the receiving server whas off tonight, so maybe it could have tried to copie data in /mnt/backups but I can't find anything there.
any idea?
-
Hello,
I updated to 6.11.3 last night and this morning I have "Invalid folder Backups contained within /mnt" and "Rootfs file is getting full (currently 83 % used)" error messages.
haven't touched anything on that server recently exept updating to 6.11.2 a couple days ago.
any idea?
-
thanks for answering!
docker run nexius2/plex_user_manager:latestdidn't respond anything..... I guess I have problems with my dockerfile then....but it builds well on github 😕
-
Hello,
I'm starting to need more space and looking at new HDDs.
I had a bad experience with seagate ironwolf (8To) on my HBA card that failed randomly. No bios update on conf ever manage to solve my issue so I bought a simple sata controleur for them and continued with WD on my HBA.
now, I'm looking at seagate exos X18 18To but I don't want to buy them if I can't connect them to an HBA card.
has anybody tryied this with issue? (I meen for more then a month).
thanks
-
Hello,
comming again for some help 🙂
since I had no logs starting my container, I tryied with command lines. this is what I got
docker run plex_user_manager Unable to find image 'plex_user_manager:latest' locally docker: Error response from daemon: pull access denied for plex_user_manager, repository does not exist or may require 'docker login': denied: requested access to the resource is denied.My dockerfile seems ok, I have it synced to dockerhub succefully, so it should be ok.
here is my template
https://github.com/Nexius2/Unraid_templates/blob/main/plex_user_manager.xml
any idea what I do wrong?
thanks
-
6 hours ago, dlandon said:
What kind of shares are you asking about? Remote server shares?
yes, the one with unassigned device. unless there is a other/better method?
thanks
-
today, I had a script use a share mount. in fact, it's the "backup/restore appdata" plugin that used a unassigned device mount to backup. and it fails.
there is something not working well with unraid mounts. when I search on the forum I see lot's of "kernel: traps: lsof[****] general protection fault ******* in libc-2.36.so" and other similar errors.
I thought my servers where just failling because of too long response because of high cpu usage, but realy I'm begining to doubt.
what is, the best practice to make shares on unraid?
-
6 hours ago, dlandon said:
Looking at your diagnostics I see an issue with one server:
Oct 10 08:56:15 Halcyon unassigned.devices: Warning: shell_exec(/bin/df '/mnt/remotes/AURORA_tdownloaded' --output=size,used,avail | /bin/grep -v '1K-blocks' 2>/dev/null) took longer than 5s!This is generally indicative of network or remote server connection issues.
That server is having a tough time with a CIFS mount:
Oct 9 06:46:29 Halcyon unassigned.devices: Mount SMB share '//AURORA/tdownloaded' using SMB 3.1.1 protocol. Oct 9 06:46:29 Halcyon unassigned.devices: Mount SMB command: /sbin/mount -t cifs -o rw,noserverino,nounix,iocharset=utf8,file_mode=0777,dir_mode=0777,uid=99,gid=100,vers=3.1.1,credentials='/tmp/unassigned.devices/credentials_tdownloaded' '//AURORA/tdownloaded' '/mnt/remotes/AURORA_tdownloaded' Oct 9 06:46:29 Halcyon kernel: CIFS: Attempting to mount \\AURORA\tdownloaded Oct 9 06:46:29 Halcyon kernel: CIFS: VFS: Error connecting to socket. Aborting operation. Oct 9 06:46:29 Halcyon kernel: CIFS: VFS: cifs_mount failed w/return code = -111 Oct 9 06:46:29 Halcyon unassigned.devices: SMB 3.1.1 mount failed: 'mount error(111): could not connect to 192.168.1.70Unable to find suitable address. '.What is that server?
I would not mount that server share with UD and see if it stops your SMB issues.
Aurora is a 3rd server and this one does not unmount from Halcyon (or at least mounts back after). I would guess errors are do to high CPU usage that stalls the server. Aurora is pretty much alway between 90 and 100% CPU 🙂
My issue is from Halcyon and Nostromo or from Aurora and Nostromo because my shares are on Nostromo (and he is rarely over 40% CPU)
But maybe I'm wrong and I have some sort of network issue between all my servers 😕
-
8 hours ago, JorgeB said:
Try booting Unraid in safe mode to rule out any plugin.
never tried safe mode, but mount are made with unassigned device.... no plugin, no mount I would say... no?







adding a parity disk
in General Support
Posted
Hello,
I have a parity disk on my server and I want to add a second one.
what is the process knowing that I can stop / restart array but it must not be offline for hours. meaning during rebuild, the array MUST be online with all VMs and dockers running.
I also will have to change the actual parity disk with a bigger one
thanks