




01cooperl
Members
-
Joined
-
Last visited
Everything posted by 01cooperl
-
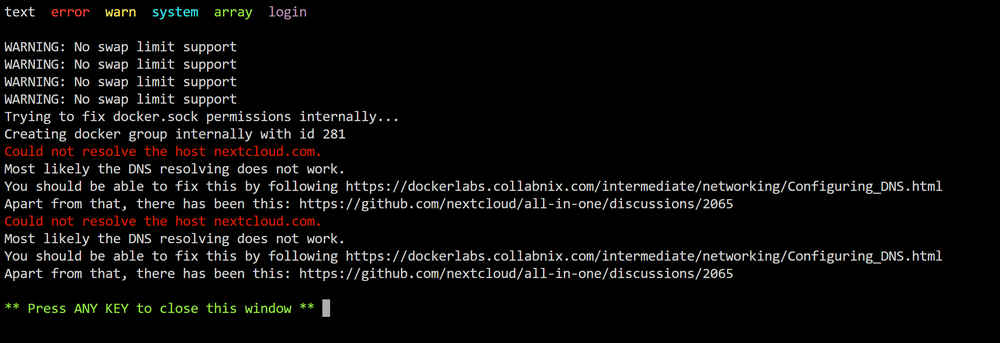
HI all, I've just been following SpaceInvaderOne's Nextcloud AIO set-up video and I'm running into an issue where the master docker container won't start properly so I cannot access the webUI and hence it will not proceed to install any other docker containers. In the logs for the docker it shows the following: Anyone else had the same issue? I have another Nextcloud installation but I've stopped the old nextcloud container with a fresh share location for the data directory. Thanks in advance!
-
Temporary licence key has expired. When is this docker expected to be updated?
-
I changed the domain to blank as suggested above to successfully start the collabora container and now nextcloud is working again. I guess it must be how I configured nextcloud to connect to collabora or swag is doing something weird
-
I have the same problem. It's taken down my nextcloud instance as well! I would have expected Nextcloud to still function is Collabora cannot start. Any ideas?
-
I have this running using swag, just follow the link you shared and I just used the config/keys folder to upload the cloudflare certificate which is downloadable in that support page.

