




1unraid_user
Members
-
Joined
-
Last visited
-
In the official docker, a hostname is defined in "docker-compose". I don't see this in this docker. This apparently leads to the fact, that the Docker ImageID is used as hostname. Unfortunately with every docker refresh I therefore have a different hostname, which leads to issues in my scripts. If I set a hostname in the GUI of ioBroker, it gets overwritten with the next docker update. Apparently earlier the -e HOST_HOSTNAME = XXX was used for this (I can still see it in my docker run command) but it doesn't seem to have an effect anymore (also not documented in buanet docker documentation)
-
Thanks so much, that fixed the issue. Fist time seeking for technical support here and great experience 🙂 For other users reading this: I can confirm no data is lost in this process, even though I had to tick a checkbox that looked dangerous when stating the Array. Is this the same effect I have when doing tools --> new config ? Just out of curiosity: The dockers are stopped anyways when disabling the pool, so why should I disable them first?
-
Thanks JorgeB, you can find the file attached unraid-diagnostics-20241216-1947.zip
-
Following it up I think when I exchanged the first cache drive, my pool went to "single". This seems to happen automatically, when one of the two RAID1 drives is missing on boot. This is very unexpected for me. I still do not understand why I can't swap the remaining 120GB HDD. I still get the "Cache Pool: Too many missing devices" error, even though I rebuilt my Raid1 in the balance options of the cache pool.
-
I am trying to get something sorted in my head and hope someone can clear things up. I have a cache Pool in RAID1 (2x120 GB) which means I have effectively 120 GB useable space and 1 drive can fail. Now I wanted to upgrade to 500 GB so I purchased 2x500 GB. I first replaced one drive and expected the RAID1 to balance on the new drive, when I restart the array. I saw read/write so I expected it to work. After that I replaced the 2nd 120GB drive but noticed UNRAID complainign about "Cache Pool: too many missing devices". It did not make sense to me, so after some investigation I found out my Cache Pool is actually not in RAID1 but "single mode". Ignore the part that shows "RAID1" this is due to the ongoing conversion (see last point). Where did my RAID1 go, or have I misconfigured it from the very beginning? You can clearly see I can only use 120GB of it (which only makes sense when the disks are operating in RAID1 to me). Both devices are in a cace Pool, so I expected them to fully work together. Next steps: I have now triggered "btrfs Balance Status = Convert to Raid 1" and will check if I can then remove the remaining 120GB drive, but I would really like to understand what I did wrong or what I am misunderstanding in the concept. I use the RAID1 for reliability but it doesn't help me when nothing works, as soon as the 120GB drive dies.


-
Some months ago my flash drive got corrupt and I wonder ever since what the best strategy is. I use the unraid.net flash backup, as well as a versioned local backup, however this doesn‘t seem a completely valid backup strategy. When my flash drive got corrupted, my backup started backing up the corrupted files, which made unraid.net backup worthless. I just found out by accident that my drive was corrupt and that something was wrong, when the server didn’t reboot. The first corrupted files were months old at this point, and I had no backup that old anymore. I was able to put together a valid flash drive by manually identifying corrupted files and replacing them with the original file. It was mostly luck, that no „individualized“ files were corrupt. I wonder how this could be avoided. To be fully sure the corrupted files are not backed up, I would need a weekly job that searches for corrupted files. Only if nothing was found, a backup should be done. If corrupted files are found, the last „clean“ backup should be used to create a new flash drive. I have not read about these issues so far. Is this problem common?
-
Hi @JoeUnraidUser, I am still using your script as part of my backup routine, but I end up with a lot of backups meanwhile. Do you have a way to delete the oldest files as soon as a certain amount of backups is reached (e.g. only keep 10 backups per Docker and then delete the oldest)
-
I got the docker to run, however I am failing on passing though the RF-USB-2. In case you have problems, check my attached screenshot on my docker-configuration. Regarding the RF-USB-2 it's possible different to a VM the driver actually has to be enabled on host-level. It's weird, as I can pass through the device to the VM without a problem, but it might be the device is not initialised completely on host-level, which then becomes a problem in the docker. In case anyone else is trying this, let me know.
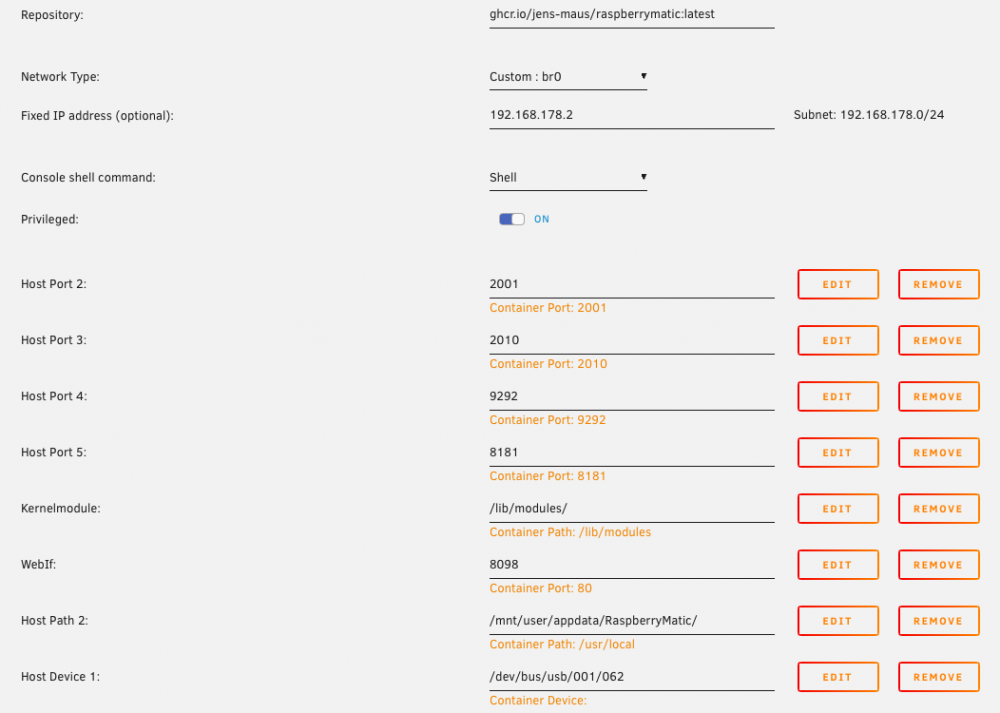
-
Hi everyone, did anyone figure out a solution by now? I am still looking into this.
-
So by now I could only solve this by setting up a VM. It's not the worst solution, but a docker would definitely be sexier, slimmer and easier to backup.
-
No ideas?
-
Sine v3.55.10. Raspberrymatic also offers the installation via docker. I saw some people setting it up as VM, but docker would be the preferred way for me, as it's much lighter. Has anyone made it run in unraid? This Github wiki explains it a little. However, I'm a bit afraid of just using these commands in my productive UNRAID. Is it safe to use? Does anyone maybe already has it running in docker? Unfortunately I have 0 experience in setting up dockers without just clicking "install" in the community applications 😅
-
Did anyone managed to run it without the array spinning up? I use a cached share as backup destination as well as Dynamix Folder Cache plugin. However, my array still spins up every time I start a backup job By the way: is it on purpose that the cache folder for the plugin is not beeing deleted after finishing? Looks to me like "appdata" in the backup could be deleted afterwards, as we have the .tgz
-
Fixed it by running chmod u+x backupDockers.sh I tried to run the command partially with "sudo" before, because I already assumed it might be a rights problem and I thought I can work around it with sudo. Turns out however, sudo was part of the problem. Don't understand it though but it's running now
-
Hi @JoeUnraidUser I just tried your script (which is exactly what I am looking for), but the system gives me this error message backupDockers.sh: line 52: syntax error near unexpected token `<' backupDockers.sh: line 52: ` readarray -t all < <(printf '%s\n' "$(docker ps -a --format "{{.Names}}" | sort -fV)")' I tried inserting as text and then downloaded the provided file. Buth without success. As this post is ranked #1 in google for unraid docker backups, I think fixing this would probably be a big gain for the community. (Maybe I am the problem).


