




bk101
Members
-
Joined
-
Last visited
-
Quick question, if we want to follow the following steps do we do them BEFORE updating to 6.12.4 or AFTER updating? "For those users, we have a new method that reworks networking to avoid this. Tweak a few settings and your Docker containers, VMs, and WireGuard tunnels should automatically adjust to use them: Settings > Network Settings > eth0 > Enable Bridging = No Settings > Docker > Host access to custom networks = Enabled"
-
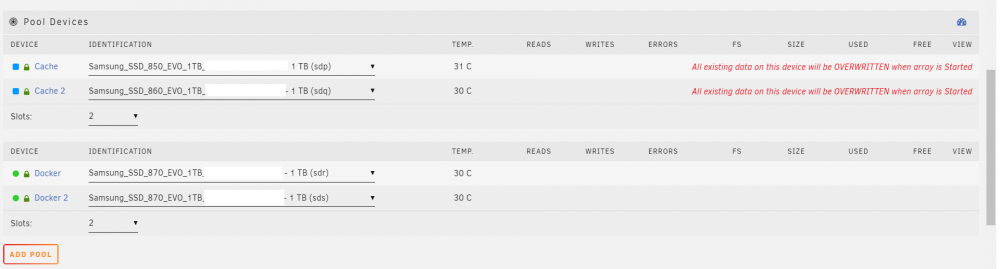
My Unraid box was running completely fine, no errors no issues with disks. I spun the array down to disable SMBv1 as per some security advice I've seen. Anyway while my array was powered down I noticed that my cache pool has 4 slots, I only have 2 cache SSDs and 2 empty slots. I thought oh lets reduce the available slot size to 2 as I probably wont add another 2 drives in the future, as soon as I did this the drive status went blue and it says "All existing data on this device will be OVERWRITTEN when array is Started" I don't want my data to be deleted so I changed the amount of slots back to 4 however it's still blue and says my data will be overwritten. How do I fix this? I don't want to power on my array in case it deletes data. My hunch is to change slots to 2 and do a new config keeping all existing settings but I'm not certain and don't want to cause another issue on top of this. Any help would be appreciated as I can't start my array without knowing what's going to happen I've noticed in cache.cfg it's references 2 additional SSDs that where in the pool in the past. This pool used to be 4 SSDs but I reduced it to 2 maybe a year ago and it's had 2 empty slots since then and working fine. Not sure if this is related. edit: Diagnostics added edit2 : I went for the new config, selected all and then checked parity is valid on start everything is back... panic over
-
This worked for me! thanks
